Ces dernières années, les innovations en matière de grands modèles de langage (LLM) se sont succédées, remettant constamment en question les limites des architectures existantes. L'éditeur de Downcodes a appris que des chercheurs de Stanford, UCSD, UC Berkeley et Meta ont proposé conjointement une nouvelle architecture appelée TTT (Test-Time-Training Layers). Avec sa conception révolutionnaire, elle devrait complètement changer notre compréhension du langage. Le modèle est reconnu et appliqué. En combinant intelligemment les avantages de RNN et de Transformer, l'architecture TTT améliore considérablement la capacité d'expression du modèle tout en garantissant une complexité linéaire. Elle fonctionne particulièrement bien lors du traitement de textes longs, apportant de nouvelles perspectives dans des domaines tels que la possibilité de modélisation de vidéos longues.
Dans le monde de l’IA, le changement survient toujours de manière inattendue. Tout récemment, une nouvelle architecture appelée TTT a été proposée conjointement par des chercheurs de Stanford, UCSD, UC Berkeley et Meta. Elle a renversé Transformer et Mamba du jour au lendemain et a apporté des changements révolutionnaires aux modèles de langage.
TTT, le nom complet des couches Test-Time-Training, est une toute nouvelle architecture qui compresse le contexte par descente de gradient et remplace directement le mécanisme d'attention traditionnel. Cette approche améliore non seulement l'efficacité, mais débloque également une architecture de complexité linéaire avec une mémoire expressive, nous permettant de former des LLM contenant des millions, voire des milliards de jetons en contexte.

La proposition de la couche TTT est basée sur une connaissance approfondie des architectures RNN et Transformer existantes. Bien que RNN soit très efficace, il est limité par sa capacité d'expression ; tandis que Transformer a une forte capacité d'expression, mais son coût de calcul augmente linéairement avec la longueur du contexte. La couche TTT combine intelligemment les avantages des deux, en conservant une complexité linéaire et en améliorant les capacités d'expression.
Lors des expériences, les deux variantes, TTT-Linear et TTT-MLP, ont démontré d'excellentes performances, surpassant Transformer et Mamba dans des contextes courts et longs. En particulier dans les scénarios à contexte long, les avantages de la couche TTT sont plus évidents, ce qui offre un énorme potentiel pour des scénarios d'application tels que la modélisation vidéo longue.
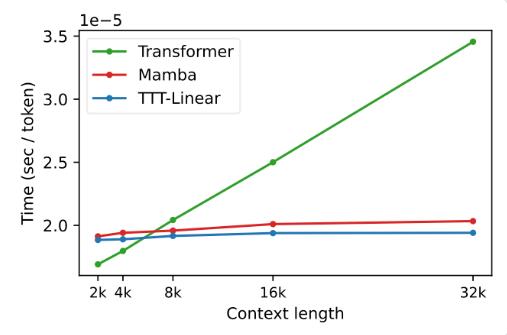
La proposition de couche TTT est non seulement innovante en théorie, mais présente également un grand potentiel dans les applications pratiques. À l'avenir, la couche TTT devrait être appliquée à la modélisation vidéo longue pour fournir des informations plus riches grâce à des images d'échantillonnage densément. C'est un fardeau pour le Transformer, mais c'est une bénédiction pour la couche TTT.
Cette recherche est le résultat de cinq années de travail acharné de l’équipe et se prépare depuis la période postdoctorale du Dr Yu Sun. Ils ont persisté à explorer et à essayer, et ont finalement obtenu ce résultat révolutionnaire. Le succès de la couche TTT est le résultat des efforts inlassables et de l’esprit d’innovation de l’équipe.
L'avènement de la couche TTT a apporté une nouvelle vitalité et de nouvelles possibilités au domaine de l'IA. Cela change non seulement notre compréhension des modèles de langage, mais ouvre également une nouvelle voie pour les futures applications de l’IA. Attendons avec impatience l'application et le développement futurs de la couche TTT et assistons aux progrès et aux percées de la technologie de l'IA.
Adresse papier : https://arxiv.org/abs/2407.04620
L'émergence de l'architecture TTT a sans aucun doute donné un élan au domaine de l'IA. Ses progrès révolutionnaires dans le traitement de textes longs indiquent que les futures applications d'IA auront des capacités de traitement plus puissantes et des perspectives d'application plus larges. Attendons de voir comment l’architecture TTT va encore changer notre monde.