L'éditeur de Downcodes vous apporte une grande nouveauté ! Cerebras Systems a lancé le service d'inférence d'IA le plus rapide au monde - Cerebras Inference, qui a complètement changé les règles du jeu dans le domaine de l'inférence d'IA grâce à sa vitesse incroyable et son prix extrêmement compétitif. Il fonctionne bien dans le traitement de divers modèles d'IA, en particulier les grands modèles de langage (LLM), et est 20 fois plus rapide que les systèmes GPU traditionnels à un prix aussi bas qu'un dixième, voire un centième. Comment cela affectera-t-il le développement futur des applications d’IA ? Regardons de plus près.
Cerebras Systems, pionnier du calcul de performance de l'IA, a introduit une solution révolutionnaire qui révolutionnera l'inférence de l'IA. Le 27 août 2024, la société a annoncé le lancement de Cerebras Inference, le service d'inférence d'IA le plus rapide au monde. Les indicateurs de performance de Cerebras Inference éclipsent les systèmes GPU traditionnels, offrant une vitesse 20 fois supérieure à un coût extrêmement faible, établissant ainsi une nouvelle référence pour l'informatique IA.
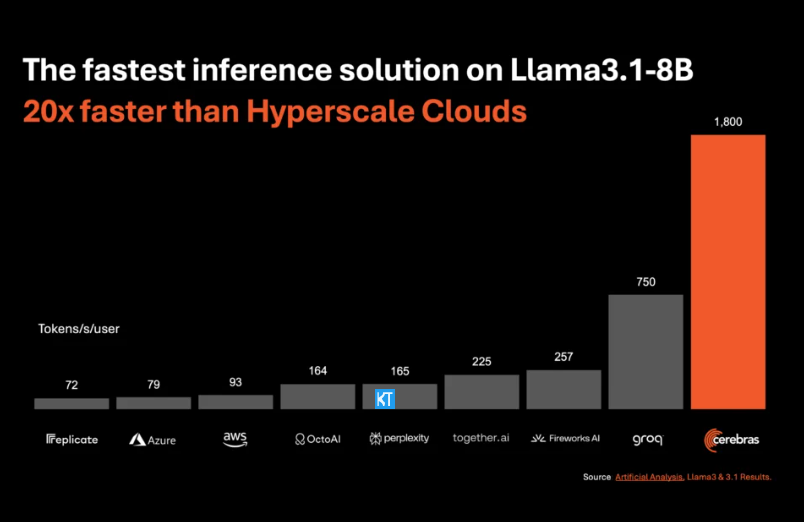
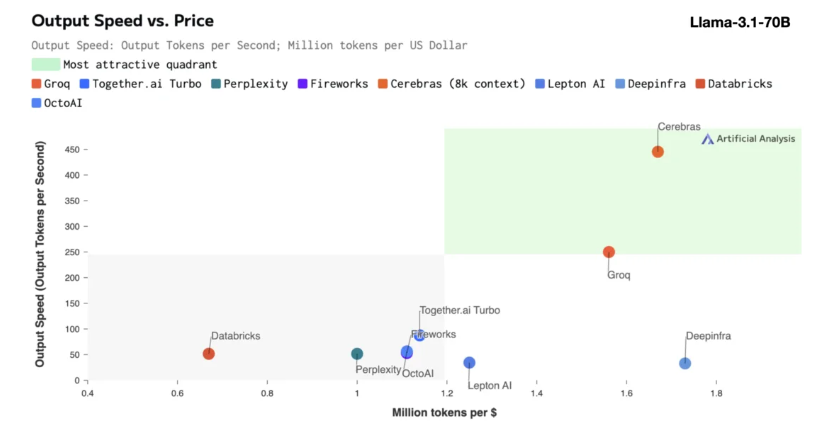
L'inférence de Cerebras est particulièrement adaptée au traitement de divers types de modèles d'IA, en particulier les « grands modèles de langage » (LLM) en développement rapide. En prenant comme exemple le dernier modèle Llama3.1, sa version 8B peut traiter 1 800 jetons par seconde, tandis que la version 70B peut traiter 450 jetons. Non seulement c'est 20 fois plus rapide que les solutions GPU NVIDIA, mais son prix est également plus compétitif. Le prix de Cerebras Inference commence à seulement 10 cents par million de jetons, et la version 70B est à 60 cents. Par rapport aux produits GPU existants, le rapport prix/performance est 100 fois amélioré.
Il est impressionnant que Cerebras Inference atteigne cette vitesse tout en conservant une précision de pointe. Contrairement à d'autres solutions axées sur la vitesse, Cerebras effectue toujours des inférences dans le domaine 16 bits, garantissant ainsi que les améliorations de performances ne se font pas au détriment de la qualité de sortie du modèle d'IA. Micha Hill-Smith, PDG d'Artificial Analytics, a déclaré que Cerebras avait atteint une vitesse de plus de 1 800 jetons de sortie par seconde sur le modèle Llama3.1 de Meta, établissant ainsi un nouveau record.
L’inférence IA est le segment de l’informatique IA qui connaît la croissance la plus rapide, représentant environ 40 % de l’ensemble du marché du matériel IA. L'inférence d'IA à haut débit, telle que celle fournie par Cerebras, est comme l'émergence de l'Internet à haut débit, ouvrant de nouvelles opportunités et inaugurant une nouvelle ère pour les applications d'IA. Les développeurs peuvent utiliser Cerebras Inference pour créer des applications d'IA de nouvelle génération qui nécessitent des performances complexes en temps réel, telles que des agents intelligents et des systèmes intelligents.
Cerebras Inference propose trois niveaux de service à des prix raisonnables : le niveau gratuit, le niveau développeur et le niveau entreprise. Le niveau gratuit offre un accès API avec des limites d'utilisation généreuses, ce qui le rend idéal pour un large éventail d'utilisateurs. Le niveau développeur offre des options de déploiement sans serveur flexibles, tandis que le niveau entreprise fournit des services personnalisés et une assistance aux organisations avec des charges de travail continues.
En termes de technologie de base, Cerebras Inference utilise le système CerebrasCS-3, piloté par le Wafer Scale Engine3 (WSE-3), leader du secteur. Ce processeur IA est sans précédent en termes d'échelle et de vitesse, offrant 7 000 fois plus de bande passante mémoire que le NVIDIA H100.
Cerebras Systems est non seulement à la pointe de la tendance dans le domaine de l'informatique IA, mais joue également un rôle important dans plusieurs secteurs tels que le médical, l'énergie, le gouvernement, l'informatique scientifique et les services financiers. En faisant progresser continuellement l’innovation technologique, Cerebras aide les organisations de divers domaines à relever les défis complexes de l’IA.
Souligner:
La vitesse de service de Cerebras Systems est multipliée par 20, son prix est plus compétitif et ouvre une nouvelle ère de raisonnement par l'IA.
Prend en charge divers modèles d'IA, particulièrement performants sur les grands modèles de langage (LLM).
Trois niveaux de service sont proposés pour permettre aux développeurs et aux utilisateurs d'entreprise de choisir en toute flexibilité.
Dans l’ensemble, l’émergence de Cerebras Inference marque une étape importante dans le domaine de l’inférence de l’IA. Ses excellentes performances et son économie favoriseront la vulgarisation généralisée et le développement innovant des applications d’IA, et méritent l’attention et l’anticipation de l’industrie ! L'éditeur de Downcodes continuera de vous apporter davantage d'informations technologiques de pointe.