Aujourd’hui, avec le développement rapide de la technologie de l’IA, les petits modèles de langage (SLM) attirent beaucoup d’attention en raison de leur capacité à fonctionner sur des appareils aux ressources limitées. L'équipe Nvidia a récemment publié Llama-3.1-Minitron4B, un excellent petit modèle de langage basé sur la compression du modèle Llama 3. Il utilise des technologies d'élagage et de distillation de modèles pour rivaliser avec des modèles plus grands en termes de performances, tout en offrant des avantages efficaces en matière de formation et de déploiement, offrant ainsi de nouvelles possibilités aux applications d'IA. L'éditeur de Downcodes vous amènera à comprendre en profondeur cette avancée technologique.
À une époque où les entreprises technologiques recherchent l’intelligence artificielle sur les appareils, de plus en plus de petits modèles de langage (SLM) émergent et peuvent fonctionner sur des appareils aux ressources limitées. Récemment, l'équipe de recherche de Nvidia a utilisé une technologie de pointe d'élagage et de distillation de modèles pour lancer Llama-3.1-Minitron4B, une version compressée du modèle Llama3. Ce nouveau modèle est non seulement comparable en performances à des modèles plus grands, mais rivalise également avec des modèles plus petits de même taille, tout en étant plus efficace en termes de formation et de déploiement.
L'élagage et la distillation sont deux techniques clés pour créer des modèles linguistiques plus petits et plus efficaces. L'élagage fait référence à la suppression de parties sans importance du modèle, y compris « l'élagage en profondeur » - en supprimant des couches entières, et « l'élagage en largeur » - en supprimant des éléments spécifiques tels que les neurones et les têtes d'attention. La distillation du modèle, quant à elle, transfère les connaissances et les capacités d'un grand modèle (c'est-à-dire le « modèle de l'enseignant ») vers un « modèle d'étudiant » plus petit et plus simple.
Il existe deux méthodes principales de distillation.La première est la « formation SGD », qui permet au modèle étudiant d'apprendre les entrées et les réponses du modèle enseignant. La seconde est la « distillation classique des connaissances ». le modèle étudiant a également besoin d'une activation interne du modèle d'enseignant apprenant.
Dans une étude précédente, les chercheurs de Nvidia ont réussi à réduire le modèle Nemotron15B à un modèle de 800 millions de paramètres grâce à l'élagage et à la distillation, et l'ont finalement réduit à 400 millions de paramètres. Ce processus améliore non seulement les performances de 16 % sur le célèbre benchmark MMLU, mais nécessite également 40 fois moins de données d'entraînement qu'un entraînement à partir de zéro.
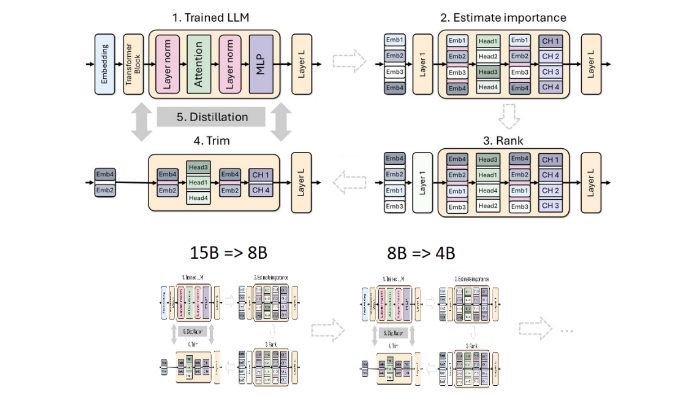
Cette fois, l'équipe Nvidia a utilisé la même méthode pour créer un modèle à 400 millions de paramètres basé sur le modèle Llama3.18B. Premièrement, ils ont affiné le modèle 8B non élagué sur un ensemble de données contenant 94 milliards de jetons pour faire face aux différences de distribution entre les données d'entraînement et l'ensemble de données distillé. Ensuite, deux méthodes d’élagage en profondeur et d’élagage en largeur ont été utilisées, et finalement deux versions différentes de Llama-3.1-Minitron4B ont été obtenues.
Les chercheurs ont affiné le modèle élagué via NeMo-Aligner et ont évalué ses capacités en matière de suivi d'instructions, de jeu de rôle, de génération d'augmentation de récupération (RAG) et d'appel de fonctions.
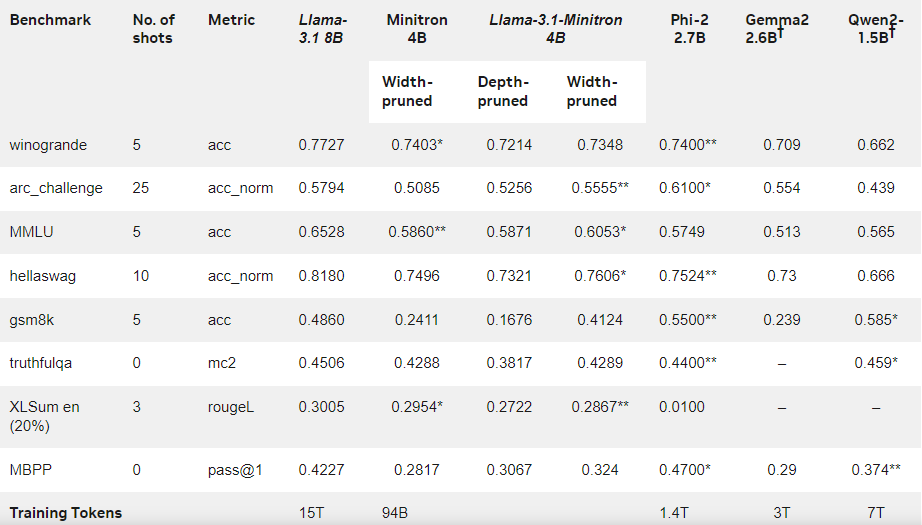
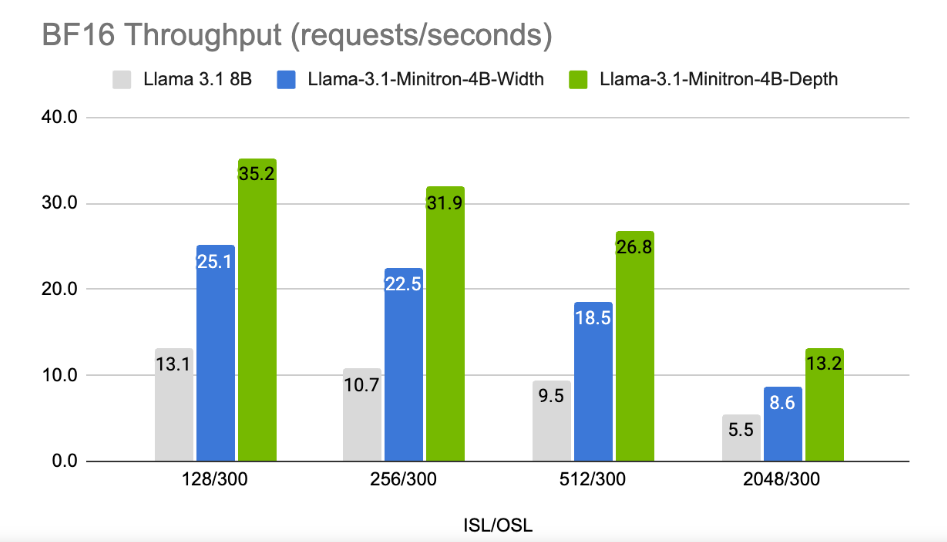
Les résultats montrent que malgré la petite quantité de données d'entraînement, les performances de Llama-3.1-Minitron4B sont toujours proches de celles d'autres petits modèles et fonctionnent bien. La version réduite en largeur du modèle a été publiée sur Hugging Face, permettant une utilisation commerciale pour aider davantage d'utilisateurs et de développeurs à bénéficier de son efficacité et de ses excellentes performances.
Blog officiel : https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model /
Souligner:
Llama-3.1-Minitron4B est un petit modèle de langage lancé par Nvidia basé sur une technologie d'élagage et de distillation, avec des capacités de formation et de déploiement efficaces.
La quantité de marqueurs utilisés dans le processus de formation de ce modèle est réduite de 40 fois par rapport à une formation à partir de zéro, mais les performances sont considérablement améliorées.
? La version d'élagage en largeur a été publiée sur Hugging Face pour faciliter l'utilisation commerciale et le développement des utilisateurs.
Dans l’ensemble, l’émergence de Llama-3.1-Minitron4B marque une nouvelle étape dans le développement de petits modèles de langage. Ses performances efficaces et sa méthode de déploiement pratique apporteront de bonnes nouvelles à davantage de développeurs et d’utilisateurs et accéléreront la vulgarisation et l’application de la technologie de l’IA. L'éditeur de Downcodes attend avec impatience d'autres innovations similaires à l'avenir.