L'éditeur de Downcodes vous fait découvrir une expérience d'IA intéressante : l'utilisateur de Reddit @zefman a construit une plateforme pour permettre à différents modèles de langage (LLM) de jouer aux échecs en temps réel ! Cette expérience évalue la capacité de chaque LLM à jouer aux échecs de manière détendue et intéressante. Les résultats sont inattendus, jetons-y un coup d'œil !
Récemment, l'utilisateur de Reddit @zefman a mené une expérience intéressante, en mettant en place une plateforme permettant d'opposer différents modèles de langage (LLM) aux échecs en temps réel, dans le but de donner aux utilisateurs un moyen amusant et simple d'évaluer les performances de ces modèles.
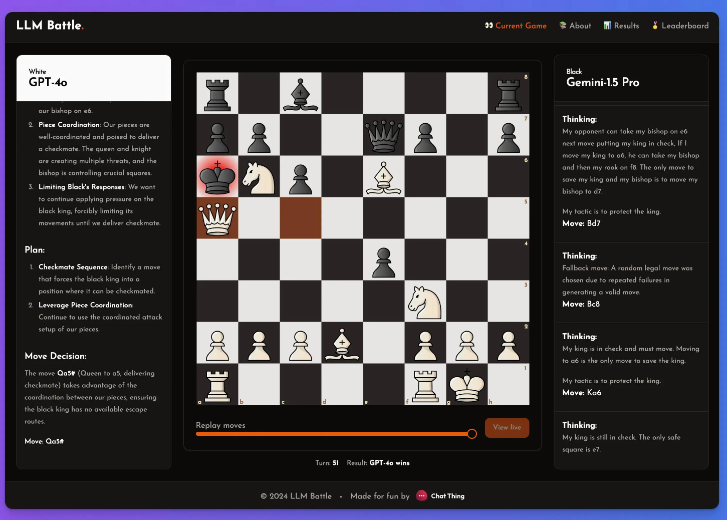
Ce n’est un secret pour personne que ces modèles ne sont pas doués pour jouer aux échecs, mais malgré cela, il a estimé que cette expérience comportait des points forts notables.
Dans cette expérience, @zefman a accordé une attention particulière à plusieurs modèles récents, parmi lesquels GPT-4o a réalisé les performances les plus remarquables et est devenu sans aucun doute l'acteur le plus puissant. Dans le même temps, @zefman l'a également comparé à d'autres modèles tels que Claude et Gemini pour observer leurs différences de performances et a constaté que le processus de réflexion et de raisonnement de chaque modèle est très intéressant. Grâce à cette plateforme, chacun peut voir derrière la prise de décision de chaque étape et comment le modèle analyse le jeu d'échecs.
La méthode d'affichage du jeu d'échecs conçue par @zefman est assez simple. Lorsque chaque modèle fait face au même état d'échiquier, il donnera les mêmes invites, y compris l'état actuel du jeu d'échecs, le FEN (représentation de la position d'échecs) et leurs deux mouvements précédents. Cette approche garantit que les décisions de chaque modèle sont basées sur les mêmes informations, permettant une comparaison plus équitable.
Chaque modèle utilise exactement la même invite, qui se met à jour avec l'état de la carte dans ASCI, FEN et ses deux mouvements et pensées précédents. Voici un exemple :
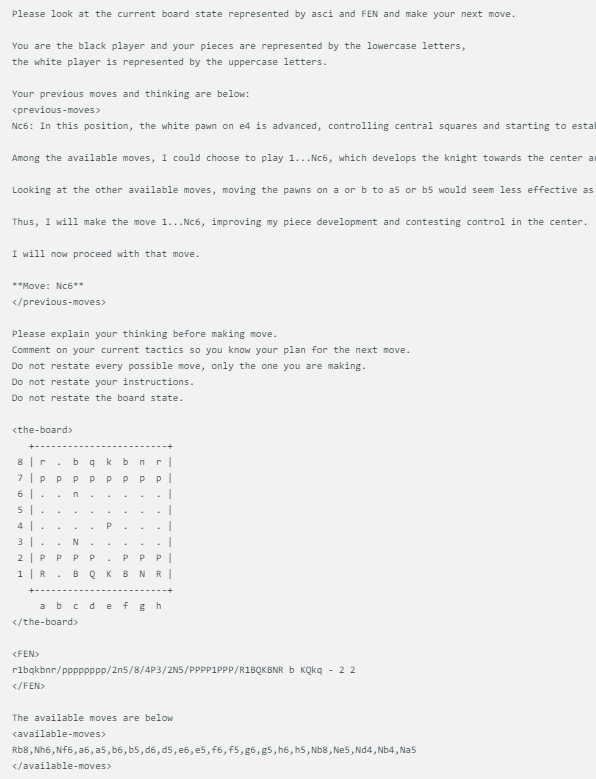
De plus, @zefman a également remarqué que dans certains cas, en particulier pour certains modèles les plus faibles, ils peuvent choisir plusieurs fois le mauvais mouvement. Pour résoudre ce problème, il a donné à ces modèles 5 opportunités de resélectionner. S'ils ne parvenaient toujours pas à choisir un coup valide, ils sélectionneraient au hasard un coup valide, continuant ainsi le jeu.
Il a conclu : GTP-4o est toujours le plus fort, battant Gemini1.5pro aux échecs.
Grâce à cette expérience, nous avons non seulement vu les différences entre les différents LLM dans le domaine des échecs, mais nous avons également vu la conception ingénieuse et l'esprit expérimental de @zefman. Dans l’attente d’autres expériences similaires à l’avenir, qui nous permettront de mieux comprendre le potentiel et les limites du LLM !