La grande sortie de Meta Company ! Open source son dernier grand modèle de langage Llama 3.1 405B, avec un volume de paramètres allant jusqu'à 128 milliards, et ses performances sont comparables à GPT-4 dans plusieurs tâches. Après un an de préparation minutieuse, de la planification du projet à l'examen final, les modèles de la série Llama 3 rencontrent enfin le public. Cette open source inclut non seulement le modèle lui-même, mais également son traitement optimisé des données avant la formation, son assurance qualité des données après la formation et sa technologie de quantification efficace pour réduire les exigences informatiques et faciliter son utilisation par les développeurs. L'éditeur de Downcodes vous expliquera en détail les améliorations et les points forts de Llama 3.1 405B.
Hier soir, Meta a annoncé l'open source de son dernier grand modèle de langage Llama3.1 405B. Cette grande nouvelle marque qu'après un an de préparation minutieuse, de la planification du projet à l'examen final, les modèles de la série Llama3 ont enfin rencontré le public.
Llama3.1405B est un modèle d'utilisation d'outils multilingues avec 128 milliards de paramètres. Après un pré-entraînement avec une longueur de contexte de 8 K, le modèle est ensuite entraîné avec une longueur de contexte de 128 K. Selon Meta, les performances de ce modèle sur plusieurs tâches sont comparables à celles du GPT-4, leader du secteur.
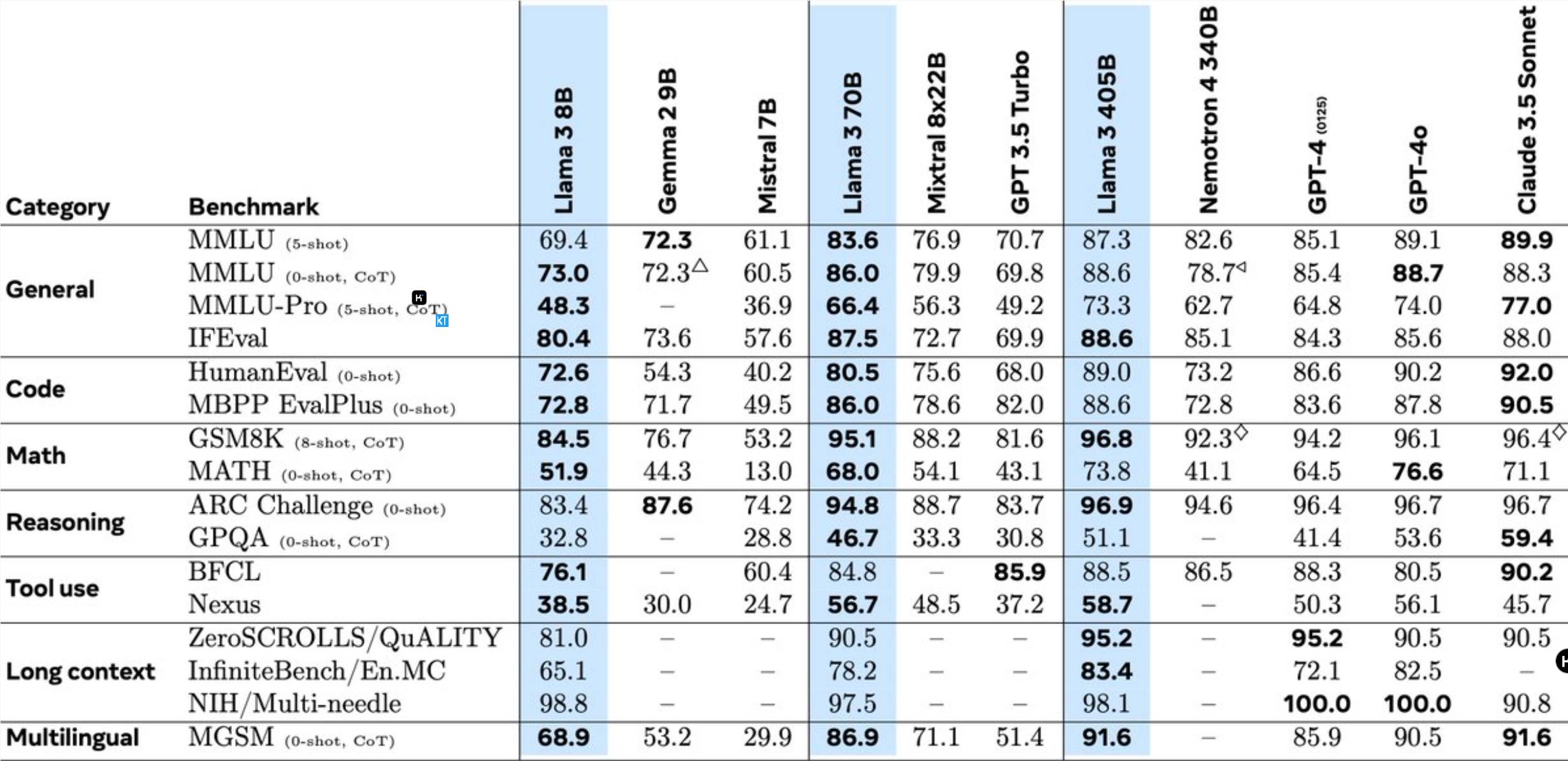
Par rapport au modèle Llama précédent, Meta a été optimisé sous de nombreux aspects :
La pré-formation du modèle 405B constitue un énorme défi, impliquant 15,6 billions de jetons et 3,8x10^25 opérations à virgule flottante. À cette fin, Meta a optimisé l’ensemble de l’architecture de formation et utilisé plus de 16 000 GPU H100.
Pour prendre en charge l'inférence de production de masse du modèle 405B, Meta l'a quantifié de 16 bits (BF16) à 8 bits (FP8), réduisant considérablement les exigences informatiques et permettant à un seul nœud de serveur d'exécuter le modèle.
De plus, Meta utilise le modèle 405B pour améliorer la qualité post-formation des modèles 70B et 8B. Au cours de la phase post-formation, l'équipe a affiné le modèle de chat grâce à plusieurs séries de processus d'alignement, notamment le réglage fin supervisé (SFT), l'échantillonnage de rejet et l'optimisation directe des préférences. Il convient de noter que la plupart des échantillons SFT sont générés à l'aide de données synthétiques.
Llama3 intègre également des fonctions d'image, de vidéo et de voix, en utilisant une approche combinée pour permettre au modèle de reconnaître les images et les vidéos et de prendre en charge l'interaction vocale. Cependant, ces fonctionnalités sont encore en développement et n’ont pas encore été officiellement publiées.
Meta a également mis à jour son accord de licence pour permettre aux développeurs d'utiliser la sortie du modèle Llama pour améliorer d'autres modèles.
Les chercheurs de Meta ont déclaré : Il est extrêmement passionnant de travailler à la pointe de l’IA avec les meilleurs talents du secteur et de publier les résultats de la recherche de manière ouverte et transparente. Nous sommes impatients de voir l'innovation apportée par les modèles open source et le potentiel des futurs modèles de la série Llama !
Cette initiative open source apportera sans aucun doute de nouvelles opportunités et de nouveaux défis dans le domaine de l'IA et favorisera le développement ultérieur de la technologie des grands modèles de langage.
L'open source de Llama 3.1 405B favorisera grandement l'avancement de la technologie des grands modèles de langage et apportera plus de possibilités au domaine de l'IA. Nous attendons avec impatience que les développeurs créent des applications plus étonnantes basées sur ce modèle !