L'amélioration de l'efficacité des grands modèles de langage a toujours été un point chaud de la recherche dans le domaine de l'intelligence artificielle. Récemment, des équipes de recherche d'Aleph Alpha, de l'Université technique de Darmstadt et d'autres institutions ont développé une nouvelle méthode appelée T-FREE, qui améliore considérablement l'efficacité opérationnelle des grands modèles de langage. Cette méthode réduit le nombre de paramètres de couche d'intégration en utilisant des triples de caractères pour une activation clairsemée et modélise efficacement la similarité morphologique entre les mots. Elle réduit considérablement la consommation de ressources informatiques tout en garantissant les performances du modèle. Cette technologie révolutionnaire apporte de nouvelles possibilités pour l’application de grands modèles de langage.
L’équipe de recherche a récemment introduit une nouvelle méthode passionnante appelée T-FREE, qui permet d’augmenter considérablement l’efficacité opérationnelle des grands modèles de langage. Des scientifiques d'Aleph Alpha, de la TU Darmstadt, de hessian.AI et du Centre allemand de recherche sur l'intelligence artificielle (DFKI) ont lancé conjointement cette technologie étonnante, dont le nom complet est « Représentation clairsemée sans Tagger, une intégration efficace en mémoire est possible ».
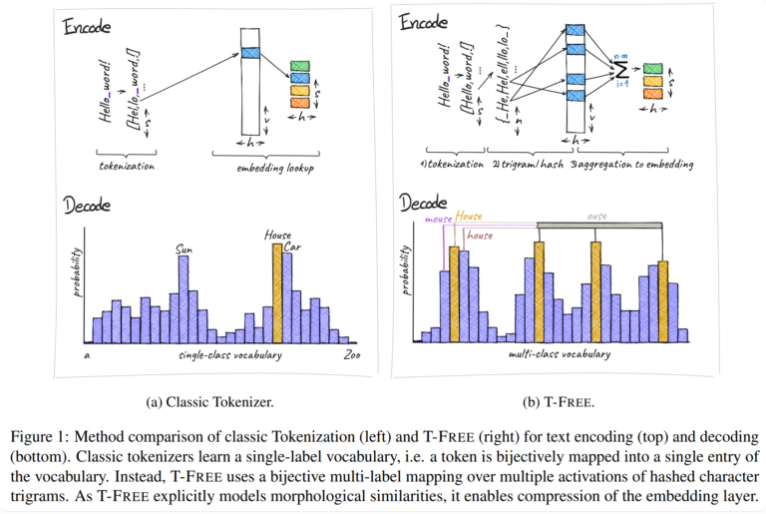
Traditionnellement, nous utilisons des tokenizers pour convertir le texte en une forme numérique que les ordinateurs peuvent comprendre, mais T-FREE a choisi une voie différente. Il utilise des triples de caractères, ce que nous appelons « triples », pour intégrer des mots directement dans le modèle via une activation clairsemée. Grâce à cette démarche innovante, le nombre de paramètres dans la couche d'intégration a été réduit d'un étonnant 85 % ou plus, tandis que les performances du modèle n'ont pas été affectées du tout lors de la gestion de tâches telles que la classification de texte et la réponse aux questions.
Un autre point fort de T-FREE est qu’il modélise très intelligemment les similitudes morphologiques entre les mots. Tout comme les mots « maison », « maisons » et « domestique » que nous rencontrons souvent dans la vie quotidienne, T-FREE peut représenter plus efficacement ces mots similaires dans le modèle. Les chercheurs pensent que les mots similaires devraient être rapprochés les uns des autres pour obtenir des taux de compression plus élevés. Par conséquent, T-FREE réduit non seulement la taille de la couche d'intégration, mais réduit également la longueur moyenne d'encodage du texte de 56 %.
Ce qui mérite d’être mentionné, c’est que T-FREE fonctionne particulièrement bien dans l’apprentissage par transfert entre différentes langues. Dans une expérience, les chercheurs ont utilisé un modèle avec 3 milliards de paramètres, formés d'abord en anglais puis en allemand, et ont découvert que T-FREE était bien plus adaptable que les méthodes traditionnelles basées sur les marqueurs.
Les chercheurs restent toutefois modestes quant à leurs résultats actuels. Ils admettent que les expériences se sont jusqu'à présent limitées à des modèles comportant jusqu'à 3 milliards de paramètres, et que d'autres évaluations sur des modèles plus grands et des ensembles de données plus importants sont prévues à l'avenir.
L'émergence de la méthode T-FREE fournit de nouvelles idées pour améliorer l'efficacité des grands modèles de langage. Ses avantages en matière de réduction des coûts de calcul et d'amélioration des performances des modèles méritent l'attention. Les futures orientations de recherche se concentreront sur la vérification de modèles et d'ensembles de données à plus grande échelle afin d'élargir davantage le champ d'application de T-FREE et de promouvoir le développement continu de la technologie des modèles de langage à grande échelle. On pense que T-FREE jouera un rôle important dans davantage de domaines dans un avenir proche.