Kunlun Technology a récemment annoncé que deux modèles de récompense qu'elle a développés, Skywork-Reward-Gemma-2-27B et Skywork-Reward-Llama-3.1-8B, ont obtenu d'excellents résultats sur RewardBench, le modèle 27B étant en tête de liste. Cela marque que Kunlun Wanwei a réalisé une percée majeure dans le domaine de l'intelligence artificielle, en particulier dans la recherche et le développement de modèles de récompense, et fournit un nouveau support technique pour la formation de grands modèles de langage. Les modèles de récompense sont cruciaux dans l’apprentissage par renforcement, car ils peuvent guider l’apprentissage du modèle et générer un contenu plus conforme aux préférences humaines. Le modèle de Kunlun Wanwei présente des avantages uniques en matière de sélection de données et de formation de modèles, ce qui le rend performant dans des aspects tels que le dialogue et la sécurité, et montre particulièrement de fortes capacités lors du traitement d'échantillons difficiles.
Kunlun Wanwei Technology Co., Ltd. a récemment annoncé que deux nouveaux modèles de récompense développés par la société, Skywork-Reward-Gemma-2-27B et Skywork-Reward-Llama-3.1-8B, ont obtenu de bons résultats sur RewardBench, le modèle de récompense faisant autorité au niveau international. Parmi eux, le modèle Skywork-Reward-Gemma-2-27B a remporté la première place et a été hautement reconnu par les responsables de RewardBench.
Le modèle de récompense occupe une position centrale dans l'apprentissage par renforcement, évaluant les performances de l'agent dans différents états et fournissant des signaux de récompense pour guider le processus d'apprentissage de l'agent, afin qu'il puisse faire le choix optimal dans un environnement spécifique. Dans la formation de grands modèles de langage, le modèle de récompense joue un rôle particulièrement critique, aidant le modèle à comprendre et à générer plus précisément un contenu conforme aux préférences humaines.
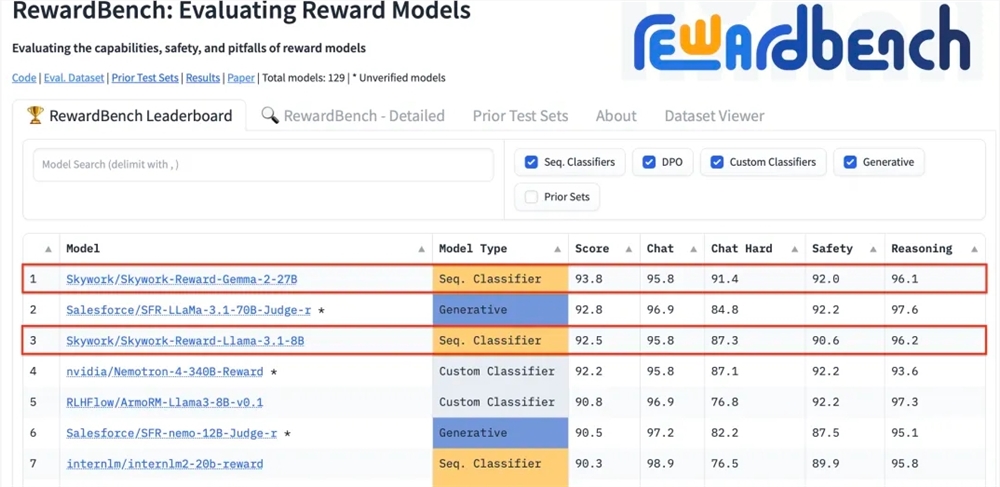
RewardBench est une liste de référence qui évalue spécifiquement l'efficacité des modèles de récompense dans les grands modèles de langage. Elle évalue de manière exhaustive les modèles à travers plusieurs tâches, notamment le dialogue, le raisonnement et la sécurité. L'ensemble de données de test de cette liste se compose de triplets composés de mots d'invite, de réponses sélectionnées et de réponses rejetées. Il est utilisé pour tester si le modèle de récompense peut classer correctement les réponses sélectionnées parmi les réponses rejetées compte tenu des mots d'invite avant de rejeter la réponse. .
Le modèle Skywork-Reward de Kunlun Wanwei est développé à partir d'ensembles de données partiellement ordonnés soigneusement sélectionnés et de modèles de base relativement petits. Par rapport aux modèles de récompense existants, ses données partiellement ordonnées proviennent uniquement de données publiques sur Internet et sont filtrées via des filtres spécifiques pour obtenir des résultats élevés. -ensembles de données de préférences de qualité. Les données couvrent un large éventail de sujets, notamment la sécurité, les mathématiques et le code, et sont vérifiées manuellement pour garantir l'objectivité des données et l'importance des écarts de récompense.
Après les tests, le modèle de récompense de Kunlun Wanwei a montré d'excellentes performances dans des domaines tels que le dialogue et la sécurité. Surtout face à des échantillons difficiles, seul le modèle Skywork-Reward-Gemma-2-27B a donné des prédictions correctes. Cette réalisation témoigne de la force technique et des capacités d’innovation de Kunlun Wanwei dans le domaine mondial de l’IA, et offre également de nouvelles possibilités pour le développement et l’application de la technologie de l’IA.
Adresse du modèle 27B :
https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B
Adresse du modèle 8B :
https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8B
L'excellente performance de Kunlun Wanwei sur RewardBench démontre ses capacités technologiques et d'innovation de pointe dans le domaine de l'intelligence artificielle. Elle offre également de nouvelles orientations et possibilités pour le développement futur de grands modèles de langage.