Nous Research lance l'optimiseur révolutionnaire de formation en IA DisTrO, mettant fin à la situation où la formation de grands modèles d'IA est limitée aux grandes entreprises géantes. DisTrO peut réduire considérablement la quantité de transmission de données entre plusieurs GPU et former efficacement des modèles d'IA même dans des environnements réseau ordinaires. Cela abaissera considérablement le seuil de formation des modèles d'IA et permettra à davantage d'individus et d'institutions de participer au développement de la recherche sur l'IA. et développement en cours. Cette technologie innovante devrait changer complètement le modèle de recherche et développement dans le domaine de l’IA et promouvoir la vulgarisation et le développement de la technologie de l’IA.
Récemment, l'équipe de recherche de Nous Research a apporté des nouvelles passionnantes au cercle technologique. Elle a lancé un nouvel optimiseur appelé DisTrO (Distributed Internet Training). La naissance de cette technologie signifie que les modèles d’IA puissants ne sont pas seulement le brevet des grandes entreprises, mais que les gens ordinaires ont également la possibilité d’utiliser leur propre ordinateur pour s’entraîner efficacement à la maison.
La magie de DisTrO réside dans le fait qu'il peut réduire considérablement la quantité d'informations qui doivent être transférées entre plusieurs unités de traitement graphique (GPU) lors de la formation d'un modèle d'IA. Grâce à cette innovation, de puissants modèles d'IA peuvent être formés dans des conditions de réseau ordinaires, et même permettre à des individus ou des institutions du monde entier d'unir leurs forces pour développer conjointement une technologie d'IA.
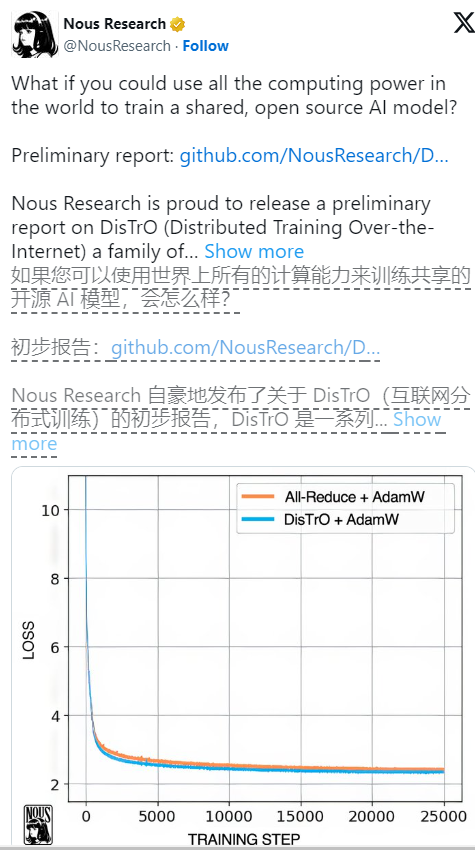
Selon un article technique de Nous Research, l'amélioration de l'efficacité de DisTrO est étonnante. L'efficacité de la formation qui l'utilise est 857 fois supérieure à celle d'un algorithme commun All-Reduce. En même temps, la quantité d'informations transmises dans chaque formation. l’étape est également réduite de 74,4 Go à 74,4 Go 86,8 Mo. De telles améliorations rendent non seulement la formation plus rapide et moins coûteuse, mais signifient également qu'un plus grand nombre de personnes ont la possibilité de participer à ce domaine.
Nous Research a déclaré sur sa plateforme sociale que grâce à DisTrO, les chercheurs et les institutions n'ont plus besoin de s'appuyer sur une certaine entreprise pour gérer et contrôler le processus de formation, ce qui leur offre plus de liberté pour innover et expérimenter. Cet environnement concurrentiel ouvert contribue à promouvoir le progrès technologique et profite en fin de compte à l’ensemble de la société.
Dans la formation en IA, les exigences matérielles sont souvent prohibitives. En particulier, les GPU Nvidia hautes performances sont devenus de plus en plus rares et coûteux à cette époque, et seules certaines entreprises bien financées peuvent se permettre le fardeau d'une telle formation. Cependant, la philosophie de Nous Research est exactement à l’opposé. Ils s’engagent à ouvrir au public la formation de modèles d’IA à moindre coût et à s’efforcer de permettre à un plus grand nombre de personnes d’y participer.
DisTrO fonctionne en réduisant les frais de communication de quatre à cinq ordres de grandeur en réduisant le besoin d'une synchronisation complète du gradient entre les GPU. Cette innovation permet de former des modèles d'IA sur des connexions Internet plus lentes, les vitesses de téléchargement de 100 Mbps et de téléchargement de 10 Mbps facilement accessibles à de nombreux foyers étant aujourd'hui suffisantes.
Lors de tests préliminaires sur le grand modèle de langage Llama2 de Meta, DisTrO a montré des résultats de formation comparables à ceux des méthodes traditionnelles tout en réduisant considérablement la quantité de communication requise. Les chercheurs ont également déclaré que bien qu'ils n'aient été testés jusqu'à présent que sur des modèles plus petits, ils spéculent provisoirement qu'à mesure que la taille du modèle augmente, la réduction des besoins de communication pourrait être plus significative, atteignant même 1 000 à 3 000 fois.
Il convient de noter que même si DisTrO rend la formation plus flexible, elle repose toujours sur la prise en charge des GPU, mais désormais, ces GPU n'ont plus besoin d'être rassemblés au même endroit, mais peuvent être dispersés dans le monde entier et collaborer via Internet ordinaire. Nous avons constaté que DisTrO était capable d'égaler la méthode traditionnelle AdamW+All-Reduce en termes de vitesse de convergence lors de tests rigoureux utilisant 32 GPU H100, mais il réduisait considérablement les besoins en communication.
DisTrO convient non seulement aux grands modèles de langage, mais peut également être utilisé pour former d'autres types d'IA, tels que les modèles de génération d'images. Les perspectives d'application futures sont passionnantes. De plus, en améliorant l'efficacité de la formation, DisTrO peut également réduire l'impact environnemental de la formation en IA, car il optimise l'utilisation de l'infrastructure existante et réduit le besoin de grands centres de données.
Grâce à DisTrO, Nous Research promeut non seulement les progrès technologiques dans la formation en IA, mais promeut également un écosystème de recherche plus ouvert et flexible, qui ouvre des possibilités illimitées pour le développement futur de l'IA.
Référence : https://venturebeat.com/ai/this-could-change-everything-nous-research-unveils-new-tool-to-train-powerful-ai-models-with-10000x-efficiency/
L'émergence de DisTrO annonce le processus de démocratisation de la formation en IA, abaisse le seuil de participation, favorise le développement rapide et l'application généralisée de la technologie de l'IA et apporte une nouvelle vitalité et des possibilités illimitées au domaine de l'IA. À l’avenir, nous nous attendons à ce que DisTrO apporte encore plus de surprises au développement de l’IA.