Les recherches de l'équipe Mamba ont fait une percée. Ils ont réussi à « distiller » le grand modèle Transformer Llama en un modèle Mamba plus efficace. Cette recherche combine intelligemment des technologies telles que la distillation progressive, le réglage fin supervisé et l'optimisation des préférences directionnelles, et conçoit un nouvel algorithme de décodage d'inférence basé sur la structure unique du modèle Mamba, qui améliore considérablement la vitesse d'inférence du modèle sans garantir une amélioration substantielle des performances. en efficacité a été atteint sans perte. Cette recherche réduit non seulement le coût de la formation de modèles à grande échelle, mais fournit également de nouvelles idées pour l'optimisation future des modèles, ce qui revêt une importance académique et une valeur d'application importantes.
Récemment, les recherches de l'équipe Mamba sont accrocheuses : des chercheurs d'universités telles que Cornell et Princeton ont réussi à « distiller » Llama, un grand modèle de Transformer, en Mamba, et à concevoir un nouvel algorithme de décodage d'inférence qui a considérablement amélioré la vitesse d'inférence du modèle.
L'objectif des chercheurs est de transformer le lama en mamba. Pourquoi faire cela ? Parce que former un grand modèle à partir de zéro coûte cher et que Mamba a reçu une grande attention depuis sa création, mais peu d'équipes forment elles-mêmes des modèles Mamba à grande échelle. Bien qu'il existe des variantes réputées sur le marché, telles que le Jamba d'AI21 et l'Hybrid Mamba2 de NVIDIA, les nombreux modèles à succès de Transformer contiennent une richesse de connaissances. Si nous pouvions conserver ces connaissances et affiner le Transformer sur Mamba, le problème serait résolu.
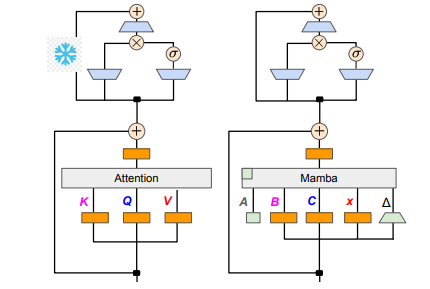
L’équipe de recherche a atteint cet objectif en combinant diverses méthodes telles que la distillation progressive, le réglage fin supervisé et l’optimisation des préférences directionnelles. Il convient de noter que la vitesse est également cruciale sans compromettre les performances. Mamba présente des avantages évidents dans le raisonnement en séquences longues, et Transformer propose également des solutions d'accélération du raisonnement, telles que le décodage spéculatif. Étant donné que la structure unique de Mamba ne peut pas appliquer directement ces solutions, les chercheurs ont spécialement conçu un nouvel algorithme et l'ont combiné avec des fonctionnalités matérielles pour mettre en œuvre un décodage spéculatif basé sur Mamba.
Enfin, les chercheurs ont réussi à convertir Zephyr-7B et Llama-38B en modèles RNN linéaires, et leurs performances étaient comparables à celles du modèle standard avant distillation. L'ensemble du processus de formation n'utilise que 20 B de jetons, et les résultats sont comparables au modèle Mamba7B formé à partir de zéro à l'aide de jetons 1,2T et au modèle NVIDIA Hybrid Mamba2 formé avec 3,5 T de jetons.
En termes de détails techniques, le RNN linéaire et l'attention linéaire sont connectés, de sorte que les chercheurs peuvent directement réutiliser la matrice de projection dans le mécanisme d'attention et terminer la construction du modèle via l'initialisation des paramètres. De plus, l'équipe de recherche a gelé les paramètres de la couche MLP dans Transformer, a progressivement remplacé la tête d'attention par une couche RNN linéaire (c'est-à-dire Mamba) et a traité l'attention des requêtes de groupe pour les clés et valeurs partagées entre les têtes.
Au cours du processus de distillation, une stratégie de remplacement progressif des couches d’attention est adoptée. Le réglage fin supervisé comprend deux méthodes principales : l'une est basée sur la divergence KL au niveau des mots et l'autre est la distillation des connaissances au niveau de la séquence. Dans la phase de réglage des préférences utilisateur, l'équipe a utilisé la méthode DPO (Direct Preference Optimization) pour garantir que le modèle peut mieux répondre aux attentes des utilisateurs lors de la génération de contenu en le comparant avec la sortie du modèle enseignant.
Ensuite, les chercheurs ont commencé à appliquer le décodage spéculatif de Transformer au modèle Mamba. Le décodage spéculatif peut être simplement compris comme l'utilisation d'un petit modèle pour générer plusieurs sorties, puis l'utilisation d'un grand modèle pour vérifier ces sorties. Les petits modèles s'exécutent rapidement et peuvent générer rapidement plusieurs vecteurs de sortie, tandis que les grands modèles sont chargés d'évaluer la précision de ces sorties, augmentant ainsi la vitesse d'inférence globale.
Afin de mettre en œuvre ce processus, les chercheurs ont conçu un ensemble d'algorithmes qui utilisent un petit modèle pour générer à chaque fois K projets de sorties, puis le grand modèle renvoie la sortie finale et le cache des états intermédiaires par vérification. Cette méthode a obtenu de bons résultats sur le GPU Mamba2.8B, qui a atteint 1,5 fois l'accélération d'inférence et le taux d'acceptation a atteint 60 %. Bien que les effets varient sur les GPU d'architectures différentes, l'équipe de recherche a encore optimisé en intégrant les noyaux et en ajustant les méthodes de mise en œuvre, et a finalement obtenu l'effet d'accélération idéal.
Dans la phase expérimentale, les chercheurs ont utilisé Zephyr-7B et Llama-3Instruct8B pour effectuer une formation de distillation en trois étapes. Au final, il n'a fallu que 3 à 4 jours pour fonctionner sur un 80G A100 à 8 cartes pour reproduire avec succès les résultats de la recherche. Cette recherche montre non seulement la transformation entre Mamba et Llama, mais fournit également de nouvelles idées pour améliorer la vitesse d'inférence et les performances des futurs modèles.
Adresse papier : https://arxiv.org/pdf/2408.15237
Cette recherche fournit une expérience précieuse et des solutions techniques pour améliorer l'efficacité des modèles de langage à grande échelle. Les résultats devraient être appliqués à davantage de domaines et favoriser le développement ultérieur de la technologie de l'intelligence artificielle. La fourniture de l’adresse papier permet aux lecteurs d’avoir une compréhension plus approfondie des détails de la recherche.