Les optimiseurs de requêtes de base de données s'appuient fortement sur l'estimation de cardinalité (CE) pour prédire la taille des résultats des requêtes et ainsi sélectionner le meilleur plan d'exécution. Des estimations de cardinalité inexactes peuvent entraîner une dégradation des performances des requêtes. Les méthodes CE existantes ont des limites, notamment lorsqu'il s'agit de requêtes complexes. Bien que le modèle d’apprentissage CE soit plus précis, son coût de formation est élevé et il manque d’évaluation systématique de référence.
Dans les bases de données relationnelles modernes, l'estimation de cardinalité (CE) joue un rôle crucial. En termes simples, l'estimation de cardinalité est une prédiction du nombre de résultats intermédiaires qu'une requête de base de données renverra. Cette prédiction a un impact énorme sur les choix de plan d'exécution de l'optimiseur de requêtes, tels que la décision de l'ordre de jointure, l'utilisation ou non des index et le choix de la meilleure méthode de jointure. Si l'estimation de la cardinalité est inexacte, le plan d'exécution peut être considérablement compromis, ce qui entraînera des vitesses de requête extrêmement lentes et affectera sérieusement les performances globales de la base de données.
Cependant, les méthodes d’estimation de cardinalité existantes présentent de nombreuses limites. La technologie CE traditionnelle repose sur certaines hypothèses simplificatrices et prédit souvent avec précision la cardinalité des requêtes complexes, en particulier lorsque plusieurs tables et conditions sont impliquées. Bien que l’apprentissage des modèles CE puisse fournir une meilleure précision, leur application est limitée par les longs temps de formation, la nécessité de disposer de grands ensembles de données et l’absence d’évaluation systématique des références.
Pour combler cette lacune, l'équipe de recherche de Google a lancé CardBench, un nouveau cadre d'analyse comparative. CardBench comprend plus de 20 bases de données réelles et des milliers de requêtes, dépassant de loin les références précédentes. Cela permet aux chercheurs d’évaluer et de comparer systématiquement différents modèles d’apprentissage CE dans diverses conditions. Le benchmark prend en charge trois paramètres principaux : les modèles basés sur des instances, les modèles sans tir et les modèles affinés, adaptés à différents besoins de formation.
CardBench est également conçu pour inclure un ensemble d'outils capables de calculer les statistiques nécessaires, de générer de véritables requêtes SQL et de créer des graphiques de requêtes annotés pour la formation des modèles CE.
Le test fournit deux ensembles de données de formation : un pour une requête de table unique avec plusieurs prédicats de filtre et un pour une requête de jointure binaire impliquant deux tables. Le benchmark comprend 9 125 requêtes sur table unique et 8 454 requêtes de jointure binaire sur l'un des plus petits ensembles de données, garantissant ainsi un environnement robuste et stimulant pour l'évaluation des modèles. Les étiquettes de données de formation de Google BigQuery ont nécessité 7 années CPU de temps d'exécution des requêtes, ce qui met en évidence l'investissement informatique important dans la création de cette référence. En fournissant ces ensembles de données et ces outils, CardBench abaisse les obstacles permettant aux chercheurs de développer et de tester de nouveaux modèles CE.
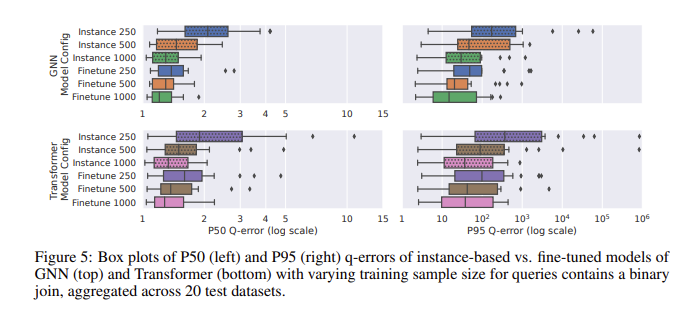
Lors de l'évaluation des performances à l'aide de CardBench, le modèle affiné s'est particulièrement bien comporté. Alors que les modèles sans tir ont du mal à améliorer la précision lorsqu'ils sont appliqués à des ensembles de données invisibles, en particulier dans les requêtes complexes impliquant des jointures, les modèles affinés peuvent atteindre une précision comparable aux méthodes basées sur des instances avec beaucoup moins de données d'entraînement. Par exemple, un modèle de réseau neuronal graphique (GNN) affiné a atteint une erreur q médiane de 1,32 et une erreur q au 95e centile de 120 sur les requêtes de jointure binaire, ce qui est nettement meilleur que le modèle zéro tir. Les résultats montrent que même avec 500 requêtes, un réglage fin du modèle pré-entraîné peut améliorer considérablement ses performances. Cela les rend adaptés aux applications pratiques où les données de formation peuvent être limitées.
L'introduction de CardBench apporte un nouvel espoir dans le domaine de l'estimation de cardinalité apprise, permettant aux chercheurs d'évaluer et d'améliorer plus efficacement les modèles, favorisant ainsi le développement de ce domaine important.
Entrée papier : https://arxiv.org/abs/2408.16170
En bref, CardBench fournit un cadre d'analyse comparative complet et puissant, fournit des outils et des ressources importants pour la recherche et le développement de modèles d'estimation de cardinalité d'apprentissage et favorise l'avancement de la technologie d'optimisation des requêtes de base de données. Les excellentes performances de son modèle affiné méritent particulièrement l’attention, offrant de nouvelles possibilités de scénarios d’application pratiques.