Récemment, une étude publiée dans le magazine Cureus a montré que le modèle GPT-4 d’OpenAI avait réussi l’examen national japonais de physiothérapie sans formation supplémentaire. Les chercheurs ont testé GPT-4 en utilisant 1 000 questions couvrant la mémoire, la compréhension, l'application, l'analyse et l'évaluation. Les résultats ont montré qu'il avait un taux de précision de 73,4 % et qu'il avait réussi les cinq parties du test. Cette recherche soulève des inquiétudes quant au potentiel de GPT-4 pour les applications médicales, tout en révélant également ses limites dans le traitement de types spécifiques de problèmes, tels que les problèmes pratiques et ceux contenant des tableaux d'images.
Une récente étude évaluée par des pairs et publiée dans la revue Cureus montre que le modèle linguistique GPT-4 d’OpenAI a réussi l’examen national japonais de physiothérapie sans aucune formation supplémentaire.
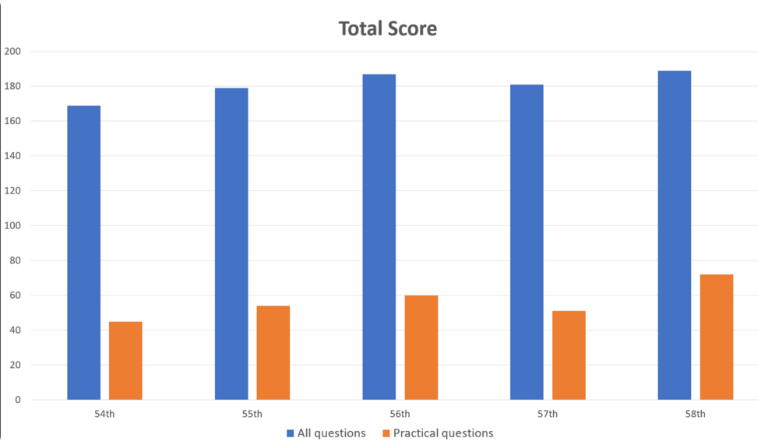
Les chercheurs ont introduit 1 000 questions dans GPT-4, couvrant des domaines tels que la mémoire, la compréhension, l'application, l'analyse et l'évaluation. Les résultats ont montré que GPT-4 a répondu correctement à 73,4 % des questions dans l’ensemble, réussissant les cinq parties du test. Cependant, les recherches ont également révélé les limites de l’IA dans certains domaines.

GPT-4 a obtenu de bons résultats sur les problèmes généraux, avec une précision de 80,1 %, mais seulement de 46,6 % sur les problèmes pratiques. De même, il gère bien mieux les questions contenant uniquement du texte (80,5 % de bonnes réponses) que les questions contenant des images et des tableaux (35,4 % de bonnes réponses). Cette découverte est cohérente avec des recherches antérieures sur les limites de la compréhension visuelle du GPT-4.
Il convient de noter que la difficulté des questions et la longueur du texte ont peu d'impact sur les performances de GPT-4. Bien que le modèle ait été principalement formé à l’aide de données anglaises, il a également donné de bons résultats lors de la gestion des entrées japonaises.
Les chercheurs ont noté que même si cette étude démontre le potentiel du GPT-4 en matière de réadaptation clinique et d’éducation médicale, elle doit être considérée avec prudence. Ils ont souligné que GPT-4 ne répond pas correctement à toutes les questions et que de futures évaluations des nouvelles versions et des capacités du modèle dans les tests écrits et de raisonnement seront nécessaires.
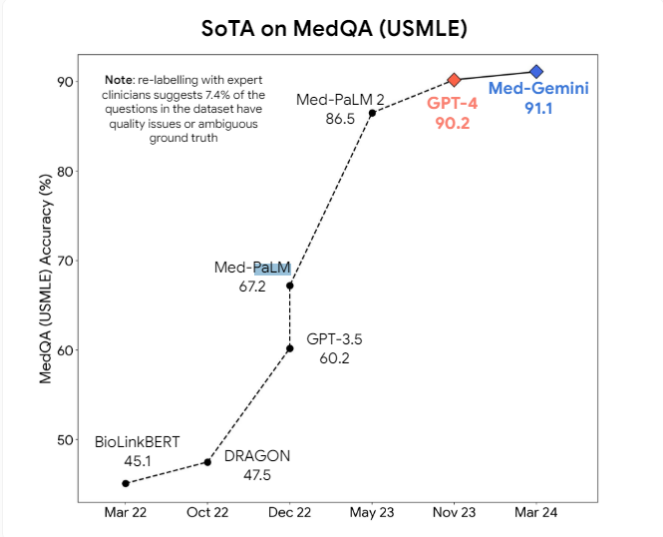
En outre, les chercheurs ont proposé que les modèles multimodaux tels que GPT-4v puissent apporter de nouvelles améliorations à la compréhension visuelle. Actuellement, des modèles d'IA médicale professionnelle tels que Med-PaLM2 et Med-Gemini de Google, ainsi que le modèle médical de Meta basé sur Llama3, sont activement développés, dans le but de surpasser les modèles à usage général dans les tâches médicales.
Cependant, les experts estiment qu’il faudra peut-être beaucoup de temps avant que les modèles d’IA médicale ne soient largement utilisés dans la pratique. L’espace d’erreur des modèles actuels reste trop grand en milieu médical, et des progrès significatifs dans les capacités d’inférence sont nécessaires pour intégrer ces modèles en toute sécurité dans la pratique médicale quotidienne.
Bien que cette étude démontre le potentiel du GPT-4 dans le domaine médical, elle nous rappelle également que la technologie de l’IA doit encore être continuellement améliorée avant de pouvoir véritablement être appliquée à des scénarios médicaux complexes. À l’avenir, des modèles multimodaux et des capacités de raisonnement plus puissantes constitueront des améliorations clés pour garantir la sécurité et la fiabilité de l’IA dans les soins médicaux.