Récemment, MLCommons a publié les résultats de l'inférence MLPerf v4.1. Plusieurs fabricants de puces d'inférence IA ont participé, et la concurrence était féroce. Pour la première fois, cette compétition inclut des puces d'AMD, Google, UntetherAI et d'autres fabricants, ainsi que les dernières puces Blackwell de Nvidia. Outre la comparaison des performances, l’efficacité énergétique est également devenue une dimension concurrentielle importante. Divers fabricants ont montré leurs compétences particulières et démontré leurs avantages respectifs dans différents tests de référence, apportant une nouvelle vitalité au marché des puces d'inférence IA.
Dans le domaine de la formation à l'intelligence artificielle, les cartes graphiques de Nvidia sont quasiment inégalées, mais en matière d'inférence d'IA, les concurrents semblent commencer à rattraper leur retard, notamment en termes d'efficacité énergétique. Malgré les bonnes performances des dernières puces Blackwell de Nvidia, il n'est pas sûr qu'elles puissent conserver leur avance. Aujourd'hui, ML Commons a annoncé les résultats du dernier concours d'inférence d'IA : MLPerf Inference v4.1. Pour la première fois, l'accélérateur Instinct d'AMD, l'accélérateur Trillium de Google, les puces de la startup canadienne UntetherAI et les puces Blackwell de Nvidia participent. Deux autres sociétés, Cerebras et FuriosaAI, ont lancé de nouvelles puces d'inférence mais n'ont pas soumis MLPerf pour tests.
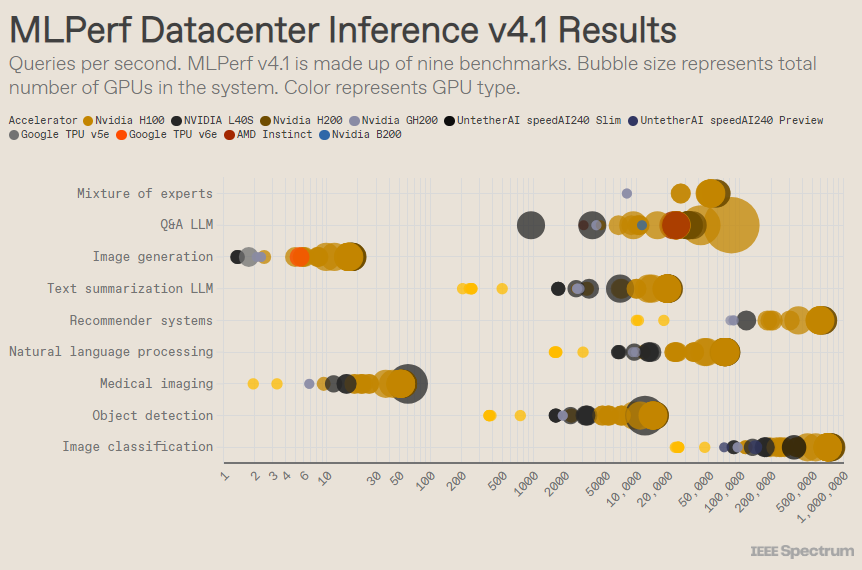
MLPerf est structuré comme une compétition olympique, avec plusieurs événements et sous-événements. La catégorie « Data Center Enclosure » compte le plus grand nombre d’entrées. Contrairement à la catégorie ouverte, la catégorie fermée oblige les participants à effectuer des inférences directement sur un modèle donné sans modifier de manière significative le logiciel. La catégorie des centres de données teste principalement la capacité à traiter les demandes par lots, tandis que la catégorie périphérique se concentre sur la réduction de la latence.
Il existe 9 benchmarks différents dans chaque catégorie, couvrant une variété de tâches d'IA, y compris la génération d'images populaires (pensez à Midjourney) et la réponse aux questions avec de grands modèles de langage (tels que ChatGPT), ainsi que certaines tâches importantes mais moins connues, telles que moteurs de classification d’images, de détection d’objets et de recommandation.
Ce cycle ajoute une nouvelle référence : le « modèle hybride expert ». Il s'agit d'une méthode de plus en plus populaire de déploiement de modèles de langage qui divise un modèle de langage en plusieurs petits modèles indépendants, chacun étant affiné pour une tâche spécifique, telle qu'une conversation quotidienne, la résolution de problèmes mathématiques ou une aide à la programmation. En attribuant chaque requête au petit modèle correspondant, l'utilisation des ressources est réduite, ce qui réduit les coûts et augmente le débit, a déclaré Miroslav Hodak, membre du personnel technique senior d'AMD.

Dans le benchmark populaire « centre de données fermé », les gagnants sont toujours les soumissions basées sur le GPU Nvidia H200 et la superpuce GH200, qui combinent GPU et CPU dans un seul package. Cependant, un examen plus attentif des résultats révèle quelques détails intéressants. Certains concurrents ont utilisé plusieurs accélérateurs, tandis que d’autres n’en ont utilisé qu’un seul. Les résultats sont encore plus déroutants si nous normalisons les requêtes par seconde en fonction du nombre d'accélérateurs et conservons les soumissions les plus performantes pour chaque type d'accélérateur. Il convient de noter que cette approche ignore le rôle du CPU et de l'interconnexion.
Par accélérateur, Blackwell de Nvidia a excellé dans les tâches de questions-réponses sur de grands modèles de langage, offrant une accélération de 2,5 fois par rapport aux itérations précédentes de la puce, la seule référence à laquelle il s'est soumis. La puce de prévisualisation speedAI240 d'Untether AI a fonctionné presque aussi bien que le H200 sur la seule tâche de reconnaissance d'image à laquelle elle a été soumise. Le Trillium de Google a des performances légèrement inférieures à celles du H100 et du H200 sur les tâches de génération d'images, tandis que l'Instinct d'AMD a des performances équivalentes au H100 sur les tâches de questions et réponses sur un grand modèle de langage.
Une partie du succès de Blackwell vient de sa capacité à exécuter de grands modèles de langage en utilisant une précision en virgule flottante de 4 bits. Nvidia et ses concurrents se sont efforcés de réduire le nombre de bits représentés dans les modèles de transformation tels que ChatGPT afin d'accélérer les calculs. Nvidia a introduit les mathématiques 8 bits dans le H100, et cette soumission est la première démonstration des mathématiques 4 bits dans le benchmark MLPerf.
Le plus grand défi lorsque l'on travaille avec des chiffres d'une telle précision est de maintenir l'exactitude, a déclaré Dave Salvator, directeur du marketing produit chez Nvidia. Pour maintenir une grande précision dans les soumissions MLPerf, l'équipe Nvidia a apporté de nombreuses innovations au logiciel.
De plus, la bande passante mémoire du Blackwell double presque, passant à 8 téraoctets par seconde, contre 4,8 téraoctets pour le H200.
La proposition Blackwell de Nvidia utilise une seule puce, mais Salvator affirme qu'elle est conçue pour la mise en réseau et la mise à l'échelle, et qu'elle fonctionnera mieux lorsqu'elle sera combinée avec l'interconnexion NVLink de Nvidia. Les GPU Blackwell prennent en charge jusqu'à 18 connexions NVLink de 100 Go par seconde, avec une bande passante totale de 1,8 téraoctets par seconde, soit près de deux fois la bande passante d'interconnexion du H100.
Salvator estime qu'à mesure que les grands modèles de langage continuent d'évoluer, même l'inférence nécessitera des plates-formes multi-GPU pour répondre à la demande, et Blackwell est conçu pour cette situation. « Havel est une plateforme », a déclaré Salvator.
Nvidia a soumis son système de puces Blackwell à la sous-catégorie Aperçu, ce qui signifie qu'il n'est pas encore disponible, mais devrait être disponible avant la prochaine version de MLPerf, qui est dans environ six mois.
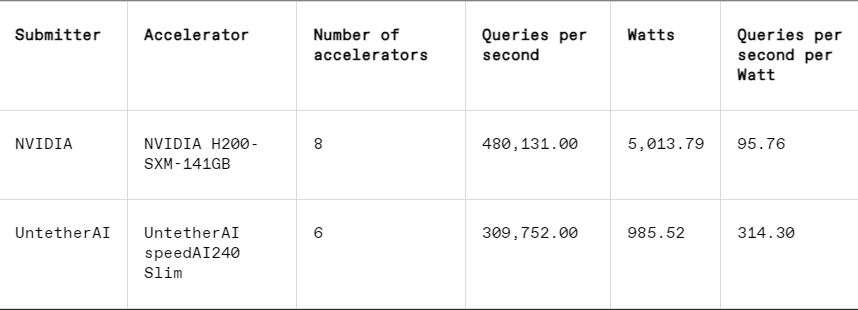
Dans chaque benchmark, MLPerf comprend également une section de mesure d'énergie qui teste systématiquement la consommation électrique réelle de chaque système lors de l'exécution de tâches. Le principal concours de ce cycle (Data Center Enclosed Energy Category) ne comptait que deux soumissionnaires, Nvidia et Untether AI. Alors que Nvidia a participé à tous les benchmarks, Untether n'a soumis que les résultats de la tâche de reconnaissance d'image.
Untether AI excelle à cet égard, atteignant avec succès une excellente efficacité énergétique. Leur puce utilise une approche appelée « informatique en mémoire ». La puce d'Untether AI est composée d'une banque de cellules mémoire avec un petit processeur situé à proximité. Chaque processeur fonctionne en parallèle, traitant les données simultanément avec les unités de mémoire adjacentes, réduisant considérablement le temps et l'énergie consacrés au transfert des données de modèle entre la mémoire et les cœurs de calcul.
« Nous avons constaté que lors de l'exécution de charges de travail d'IA, 90 % de la consommation d'énergie est liée au déplacement des données de la DRAM vers les unités de traitement du cache », a déclaré Robert Beachler, vice-président des produits chez Untether AI. "Donc, Untether rapproche le calcul des données, plutôt que de déplacer les données vers l'unité de calcul."
Cette approche fonctionne particulièrement bien dans une autre sous-catégorie de MLPerf : la fermeture des bords. Cette catégorie se concentre sur des cas d'utilisation plus pratiques, tels que l'inspection des machines dans les usines, les robots à vision guidée et les véhicules autonomes, des applications qui ont des exigences strictes en matière d'efficacité énergétique et de rapidité de traitement, a expliqué Beachler.
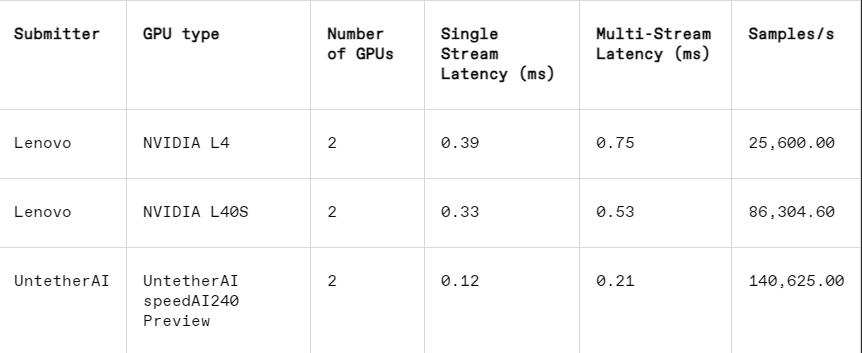
Dans la tâche de reconnaissance d'image, les performances de latence de la puce de prévisualisation speedAI240 d'Untether AI sont 2,8 fois plus rapides que celles du L40S de Nvidia, et le débit (nombre d'échantillons par seconde) est également augmenté de 1,6 fois. La startup a également soumis des résultats de consommation d'énergie dans cette catégorie, mais les concurrents de Nvidia ne l'ont pas fait, ce qui rend les comparaisons directes difficiles. Cependant, la puce de prévisualisation speedAI240 d'Untether AI a une consommation d'énergie nominale de 150 watts, tandis que le L40S de Nvidia est de 350 watts, ce qui présente un avantage de 2,3 fois en termes de consommation d'énergie et de meilleures performances de latence.
Bien que Cerebras et Furiosa n'aient pas participé à MLPerf, ils ont également respectivement publié de nouvelles puces. Cerebras a dévoilé son service d'inférence lors de la conférence IEEE Hot Chips à l'Université de Stanford. Cerebras, basé à Sunny Valley, en Californie, fabrique des puces géantes aussi grandes que le permettent les plaquettes de silicium, évitant ainsi les interconnexions entre les puces et augmentant considérablement la bande passante mémoire de l'appareil. Elles sont principalement utilisées pour former des réseaux neuronaux géants. Ils ont désormais mis à niveau leur dernier ordinateur, CS3, pour prendre en charge l'inférence.
Bien que Cerebras n'ait pas soumis de MLPerf, la société affirme que sa plate-forme surpasse le H100 de 7 fois et la puce concurrente Groq de 2 fois en termes de nombre de jetons LLM générés par seconde. « Aujourd'hui, nous sommes dans l'ère de l'IA générative par ligne commutée », a déclaré Andrew Feldman, PDG et co-fondateur de Cerebras. "Tout cela est dû au goulot d'étranglement de la bande passante mémoire. Qu'il s'agisse du H100 de Nvidia, du MI300 ou du TPU d'AMD, ils utilisent tous la même mémoire externe, ce qui entraîne les mêmes limitations. Nous brisons cette barrière parce que nous le faisons au niveau de la conception de la tranche. "
Lors de la conférence Hot Chips, Furiosa de Séoul a également présenté sa puce RNGD de deuxième génération (prononcé « rebelle »). La nouvelle puce de Furiosa présente son architecture Tensor Contraction Processor (TCP). Dans les charges de travail d’IA, la fonction mathématique de base est la multiplication matricielle, souvent implémentée dans le matériel en tant que primitive. Cependant, la taille et la forme de la matrice, c'est-à-dire le tenseur le plus large, peuvent varier considérablement. RNGD implémente cette multiplication tensorielle plus générale en tant que primitive. "Au cours de l'inférence, la taille des lots varie considérablement, il est donc essentiel de tirer pleinement parti du parallélisme inhérent et de la réutilisation des données d'une forme de tenseur donnée", a déclaré June Paik, fondatrice et PDG de Furiosa, chez Hot Chips.
Bien que Furiosa ne dispose pas de MLPerf, ils ont comparé la puce RNGD au benchmark récapitulatif LLM de MLPerf lors de tests internes, et les résultats étaient comparables à ceux de la puce L40S de Nvidia, mais ne consommaient que 185 watts par rapport aux 320 watts du L40S. Paik a déclaré que les performances s'amélioreront avec de nouvelles optimisations logicielles.
IBM a également annoncé le lancement de sa nouvelle puce Spyre, conçue pour permettre aux entreprises de générer des charges de travail d'IA et qui devrait être disponible au premier trimestre 2025.
De toute évidence, le marché des puces d’inférence d’IA sera très animé dans un avenir prévisible.
Référence : https://spectrum.ieee.org/new-inference-chips
Dans l'ensemble, les résultats de MLPerf v4.1 montrent que la concurrence sur le marché des puces d'inférence IA devient de plus en plus féroce. Bien que Nvidia conserve toujours la tête, la montée en puissance de fabricants tels qu'AMD, Google et Untether AI ne peut être ignorée. À l’avenir, l’efficacité énergétique deviendra un facteur de compétitivité clé, et les nouvelles technologies telles que l’informatique en mémoire joueront également un rôle important. Les innovations technologiques de divers fabricants continueront de promouvoir l’amélioration des capacités de raisonnement de l’IA et donneront une forte impulsion à la vulgarisation et au développement d’applications d’IA.