La technologie Text-to-SQL vise à simplifier les requêtes de base de données afin que les utilisateurs ordinaires puissent facilement obtenir des données sans apprendre le langage SQL. Cependant, face à des structures de bases de données de plus en plus complexes, la conversion précise du langage naturel en commandes SQL reste un défi. Des équipes de recherche de l'Université de technologie de Chine du Sud et de l'Université Tsinghua ont proposé une solution innovante, MAG-SQL, qui améliore considérablement la précision et l'efficacité de la conversion texte-SQL grâce à une collaboration multi-agents.
Dans le domaine du langage naturel (NLP), la technologie text-to-SQL (Text-to-SQL) se développe rapidement. Cette technologie permet aux utilisateurs ordinaires d'interroger facilement des bases de données en utilisant la langue japonaise sans avoir besoin de maîtriser les langages de programmation professionnels. comme SQL. Cependant, à mesure que la structure des bases de données devient de plus en plus complexe, la conversion précise du langage naturel en commandes SQL est devenue un défi de taille.
Des équipes de recherche de l'Université de technologie de Chine du Sud et de l'Université Tsinghua ont récemment proposé une nouvelle solution - MAG-SQL (Multiple Intelligence Generating Model), visant à améliorer l'effet de la conversion de texte en SQL. Cette méthode utilise la coopération de plusieurs agents et s'efforce d'améliorer la précision de la génération SQL.
La façon dont MAG-SQL fonctionne est assez intelligente. Les composants de base incluent le « Soft Mode Linker », le « Target-Conditional Resolver », le « Sub-SQL Generator » et le « Sub-SQL Modifier ». Premièrement, l'éditeur de liens en mode logiciel filtrera les colonnes de la base de données les plus pertinentes pour la requête, réduisant ainsi les interférences d'informations inutiles et améliorant la précision de la génération des commandes SQL. Ensuite, le décomposeur conditionnel à l'objectif divise la requête complexe en sous-requêtes plus petites pour un traitement plus facile.
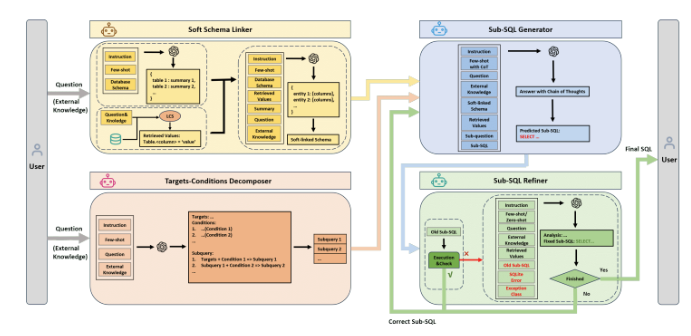
Le générateur de sous-SQL génère ensuite des requêtes sous-SQL basées sur les résultats précédents, garantissant ainsi que les commandes SQL peuvent être progressivement affinées. Enfin, le correcteur sub-SQL est chargé de corriger les erreurs SQL générées, améliorant ainsi encore la précision globale. Cette méthode de traitement en plusieurs étapes permet à MAG-SQL de fonctionner correctement dans des bases de données complexes.
Lors de tests récents, MAG-SQL a très bien fonctionné sur l'ensemble de données BIRD. Lors de l'utilisation du modèle GPT-4, le système a atteint une précision d'exécution de 61,08 %, ce qui a été considérablement amélioré par rapport aux 46,35 % du GPT-4 traditionnel. Même lorsque GPT-3.5 est utilisé, la précision de MAG-SQL atteint 57,62 %, surpassant la méthode MAC-SQL précédente. De plus, MAG-SQL fonctionne tout aussi bien sur un autre ensemble de données complexe, Spider, démontrant sa bonne polyvalence.
L'introduction de MAG-SQL améliore non seulement la précision de la conversion de texte en SQL, mais fournit également de nouvelles idées pour résoudre des requêtes complexes. Ce cadre multi-agents, grâce à des raffinements répétés et itératifs, a considérablement amélioré la capacité des grands modèles de langage dans des applications pratiques, en particulier lorsqu'il s'agit de bases de données complexes et de requêtes difficiles.
Entrée papier : https://arxiv.org/pdf/2408.07930
Souligner:
? ** Précision améliorée ** : MAG-SQL a atteint une précision d'exécution de 61,08 % sur l'ensemble de données BIRD, dépassant de loin les 46,35 % du GPT-4 traditionnel.
**Collaboration multi-agents** : cette méthode utilise plusieurs agents pour diviser le travail et coopérer, rendant le processus de génération SQL plus efficace et plus précis.
**Larges perspectives d'application** : MAG-SQL fonctionne également bien sur d'autres ensembles de données (tels que Spider), démontrant sa bonne convivialité et son applicabilité.
Le cadre multi-agent de MAG-SQL a apporté des améliorations significatives aux performances de la technologie texte-vers-SQL. Ses excellentes performances sur des ensembles de données complexes indiquent l'énorme potentiel de cette technologie dans les applications pratiques et ouvriront la voie à de futures innovations dans les méthodes d'interrogation des bases de données. . Fournit de nouvelles orientations.