L'essor de l'architecture Transformer a révolutionné le domaine du traitement du langage naturel, mais son coût de calcul élevé est devenu un goulot d'étranglement lors du traitement de textes longs. En réponse à ce problème, cet article présente une nouvelle méthode appelée Tree Attention, qui réduit efficacement la complexité informatique de l'auto-attention du modèle Transformer à contexte long grâce à la réduction de l'arborescence et exploite pleinement la puissance des clusters GPU modernes. améliore considérablement l’efficacité informatique.
À l’ère de l’explosion de l’information, l’intelligence artificielle est comme des étoiles brillantes qui éclairent le ciel nocturne de la sagesse humaine. Parmi ces stars, l'architecture Transformer est sans aucun doute la plus éblouissante. Avec le mécanisme d'auto-attention comme noyau, elle ouvre une nouvelle ère de traitement du langage naturel. Cependant, même les étoiles les plus brillantes ont des recoins difficiles à atteindre. Pour les modèles Transformer à contexte long, la consommation élevée de ressources du calcul d’auto-attention devient un problème. Imaginez que vous essayiez de faire comprendre à l’IA un article de plusieurs dizaines de milliers de mots. Chaque mot doit être comparé à tous les autres mots de l’article. La quantité de calcul est sans aucun doute énorme.
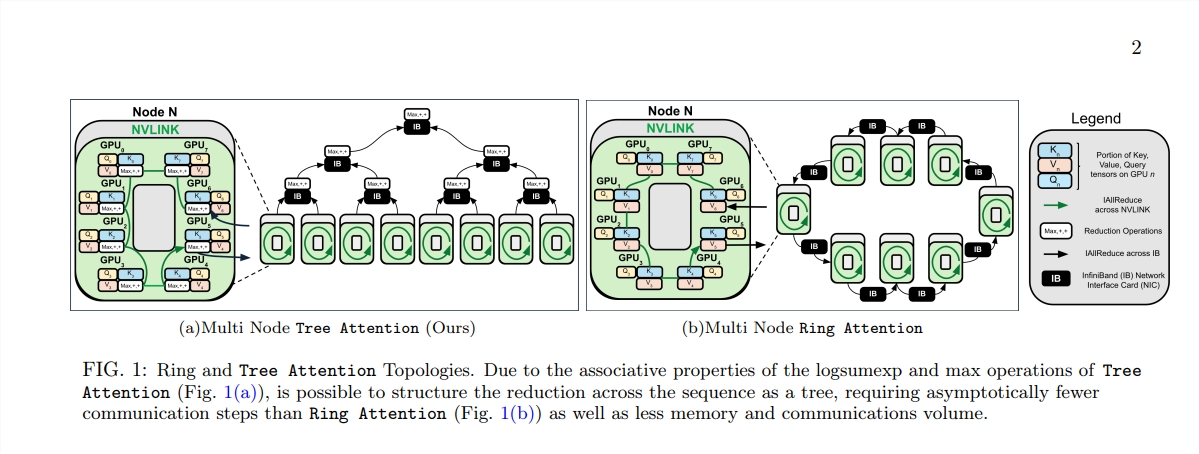
Afin de résoudre ce problème, un groupe de scientifiques de Zyphra et EleutherAI a proposé une nouvelle méthode appelée Tree Attention.
L'attention personnelle, en tant que cœur du modèle Transformer, sa complexité de calcul augmente de façon quadratique à mesure que la longueur de la séquence augmente. Cela devient un obstacle insurmontable lorsqu'il s'agit de textes longs, en particulier pour les grands modèles de langage (LLM).
La naissance de Tree Attention, c’est comme planter des arbres capables d’effectuer des calculs efficaces dans cette forêt informatique. Il décompose le calcul de l'attention personnelle en plusieurs tâches parallèles grâce à la réduction de l'arbre. Chaque tâche est comme une feuille sur l'arbre, qui forment ensemble un arbre complet.
Ce qui est encore plus étonnant, c'est que les proposants de Tree Attention ont également dérivé la fonction énergétique de l'attention personnelle, qui non seulement fournit une explication bayésienne de l'attention personnelle, mais la relie également étroitement à des modèles énergétiques tels que le réseau Hopfield.
Tree Attention prend également en compte la topologie du réseau des clusters GPU modernes et réduit les exigences de communication entre nœuds en utilisant intelligemment les connexions à large bande passante au sein du cluster, améliorant ainsi l'efficacité informatique.
Grâce à une série d'expériences, les scientifiques ont vérifié les performances de Tree Attention sous différentes longueurs de séquence et nombre de GPU. Les résultats montrent que Tree Attention est jusqu'à 8 fois plus rapide que les méthodes Ring Attention existantes lors du décodage sur plusieurs GPU, tout en réduisant considérablement le volume de communication et l'utilisation maximale de la mémoire.
La proposition de Tree Attention fournit non seulement une solution efficace pour le calcul de modèles d'attention à contexte long, mais nous offre également une nouvelle perspective pour comprendre le mécanisme interne du modèle Transformer. À mesure que la technologie de l’IA continue de progresser, nous avons des raisons de croire que Tree Attention jouera un rôle important dans les futures recherches et applications en IA.
Adresse papier : https://mp.weixin.qq.com/s/U9FaE6d-HJGsUs7u9EKKuQ
L’émergence de Tree Attention fournit une solution efficace et innovante pour résoudre le goulot d’étranglement informatique du traitement de textes longs. Elle revêt une importance considérable pour la compréhension et le développement futur du modèle Transformer. Cette méthode permet non seulement d’améliorer considérablement les performances, mais, plus important encore, de fournir de nouvelles idées et orientations pour des recherches ultérieures, qui méritent une étude et une discussion approfondies.