L'équipe UCSC-VLAA a publié l'énorme ensemble de données médicales multimodales MedTrinity-25M, qui contient 25 millions d'images médicales et des annotations détaillées, marquant une avancée majeure dans les ressources de données dans le domaine médical. L'annotation multigranulaire de cet ensemble de données permet aux chercheurs de comprendre et d'appliquer les données médicales plus en profondeur et fournit une base solide pour la formation de grands modèles médicaux multimodaux avancés. Le processus de construction de MedTrinity-25M intègre une variété de technologies, notamment un traitement de données sophistiqué, l'intégration de métadonnées, la génération de descriptions assistée par modèle de langage à grande échelle (MLLM), etc., ce qui améliore considérablement la convivialité et la valeur des données pour la recherche.
L'ensemble de données multimodales à grande échelle « MedTrinity-25M » de l'équipe UCSC-VLAA est officiellement publié. Cet ensemble de données contient 25 millions d'images médicales et des annotations détaillées. Il peut être décrit comme une innovation importante dans le domaine médical. Il comporte des annotations multigranulaires qui peuvent aider les chercheurs à mieux comprendre et appliquer les données médicales et à être utilisées pour former de grands modèles médicaux multimodaux.
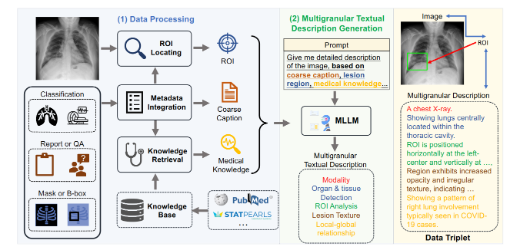
Le processus de construction de MedTrinity-25M est assez compliqué. Après un traitement minutieux des données, l'équipe a extrait les informations clés obtenues à partir de divers types de données, intégré des métadonnées, généré des titres approximatifs, localisé les domaines d'intérêt et collecté des informations médicales pertinentes. Ce qui est plus intéressant, c'est qu'ils ont utilisé ces informations pour générer des descriptions détaillées à l'aide de modèles linguistiques à grande échelle (MLLM). Cette approche améliore non seulement la disponibilité des données, mais ouvre également de nouvelles directions à la recherche médicale.
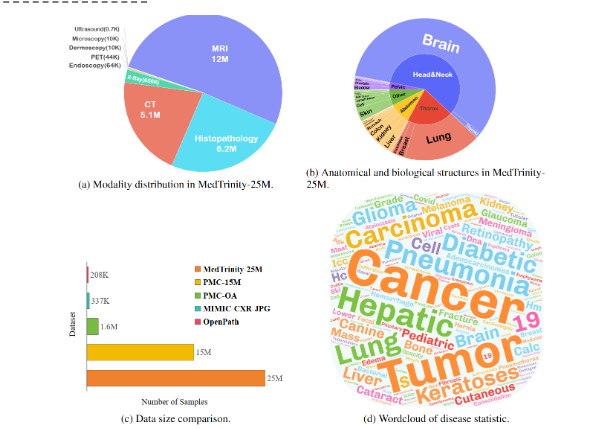
En parlant du processus de publication, il convient de mentionner que l'ensemble de données de démonstration de MedTrinity-25M a été en ligne dès juin 2024, tandis que l'ensemble de données complet a été officiellement publié le 21 juillet, et plus récemment le 7 août, ils ont également publié documents connexes.
En plus de l'ensemble de données lui-même, l'équipe fournit également une série de modèles pré-entraînés, tels que LLaVA-Med++, qui fonctionnent bien dans plusieurs tâches médicales. Les chercheurs peuvent utiliser ces outils pour mieux mener à bien leurs projets, améliorant ainsi considérablement l’efficacité de la recherche médicale.
MedTrinity-25M constitue une ressource précieuse pour la communauté médicale. J'espère que chacun pourra utiliser pleinement cet ensemble de données pour promouvoir le développement de la recherche médicale.
Entrée du projet : https://top.aibase.com/tool/medtrinity-25m
La publication de l’ensemble de données MedTrinity-25M et de ses modèles de support donne un puissant coup de pouce à la recherche sur l’intelligence artificielle médicale. Nous espérons que cet ensemble de données favorisera des percées dans l’analyse d’images médicales, le diagnostic des maladies et dans d’autres domaines, et bénéficiera à terme à davantage de patients. Les chercheurs sont invités à visiter le portail du projet pour en savoir plus et utiliser cette précieuse ressource.