Andrej Karpathy, une autorité dans le domaine de l'IA, a récemment remis en question l'apprentissage par renforcement basé sur la rétroaction humaine (RLHF), estimant que ce n'est pas le seul moyen d'atteindre une véritable IA au niveau humain, ce qui a suscité une inquiétude généralisée et des discussions animées dans l'industrie. . Il estime que le RLHF est plus une mesure provisoire qu'une solution ultime, et a pris AlphaGo comme exemple pour comparer les différences de résolution de problèmes entre l'apprentissage par renforcement réel et le RLHF. Les opinions de Karpathy offrent sans aucun doute une nouvelle perspective sur les orientations actuelles de la recherche en IA et apportent également de nouveaux défis au développement futur de l’IA.
Récemment, Andrej Karpathy, chercheur bien connu dans l'industrie de l'IA, a avancé un point de vue controversé. Il estime que l'apprentissage par renforcement basé sur la technologie de rétroaction humaine (RLHF), actuellement largement salué, n'est peut-être pas le seul moyen d'y parvenir. de véritables capacités de résolution de problèmes au niveau humain. Cette déclaration a sans aucun doute largué une bombe lourde sur le domaine actuel de la recherche en IA.
Le RLHF était autrefois considéré comme un facteur clé du succès des modèles de langage à grande échelle (LLM) tels que ChatGPT, et était salué comme l'arme secrète qui donne à l'IA des capacités de compréhension, d'obéissance et d'interaction naturelle. Dans le processus traditionnel de formation en IA, le RLHF est généralement utilisé comme dernier maillon après la pré-formation et le réglage fin supervisé (SFT). Cependant, Karpathy a comparé le RLHF à un goulot d’étranglement et à une mesure provisoire, estimant qu’il est loin d’être la solution ultime pour l’évolution de l’IA.
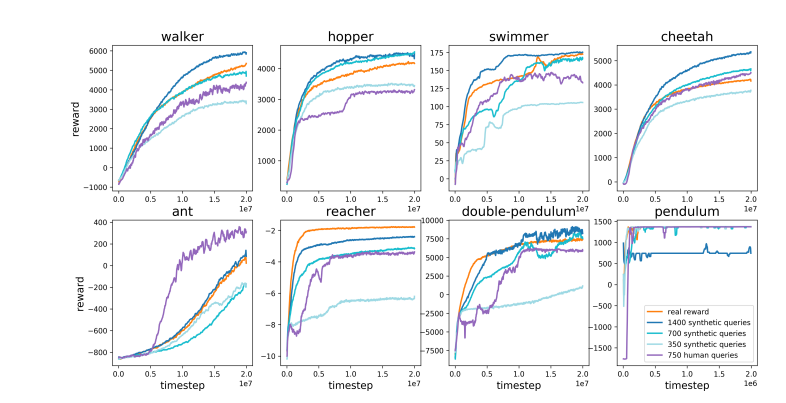
Karpathy a intelligemment comparé RLHF à AlphaGo de DeepMind. AlphaGo a utilisé ce qu'il appelle une véritable technologie RL (apprentissage par renforcement), et en jouant constamment contre lui-même et en maximisant son taux de victoire, il a finalement surpassé les meilleurs joueurs d'échecs humains sans intervention humaine. Cette approche atteint des niveaux de performances surhumains en optimisant les réseaux neuronaux pour apprendre directement des résultats du jeu.
En revanche, Karpathy estime que le RLHF consiste davantage à imiter les préférences humaines qu’à réellement résoudre des problèmes. Il a imaginé que si AlphaGo adoptait la méthode RLHF, les évaluateurs humains devront comparer un grand nombre d'états de jeu et choisir leurs préférences. Ce processus pourrait nécessiter jusqu'à 100 000 comparaisons pour former un modèle de récompense imitant la vérification de l'atmosphère humaine. Cependant, de tels jugements basés sur l’atmosphère peuvent produire des résultats trompeurs dans un jeu rigoureux comme le Go.
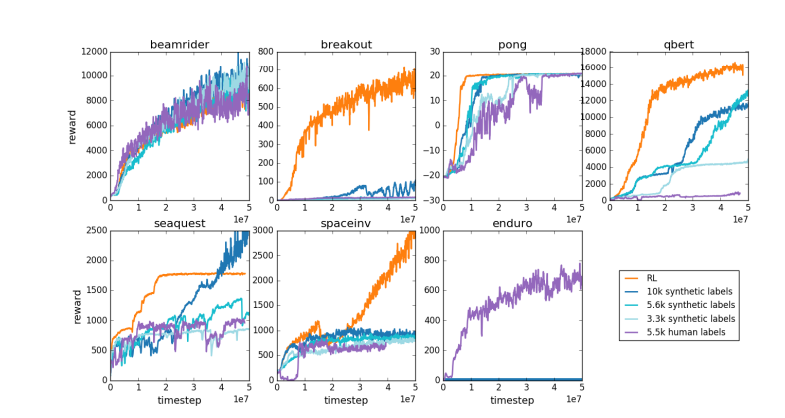
Pour la même raison, le modèle de récompense LLM actuel fonctionne de la même manière : il tend à classer les réponses élevées que les évaluateurs humains semblent statistiquement préférer. Il s’agit davantage d’un agent répondant à des préférences humaines superficielles que du reflet d’une véritable capacité à résoudre des problèmes. Plus inquiétant encore, les modèles pourraient rapidement apprendre à exploiter cette fonction de récompense plutôt que d’améliorer réellement leurs capacités.
Karpathy souligne que même si l'apprentissage par renforcement fonctionne bien dans des environnements fermés comme Go, le véritable apprentissage par renforcement reste insaisissable pour les tâches en langage ouvert. Cela est principalement dû au fait qu’il est difficile de définir des objectifs clairs et des mécanismes de récompense dans les tâches ouvertes. Comment donner des récompenses objectives pour des tâches telles que résumer un article, répondre à une question vague sur l'installation de pip, raconter une blague ou réécrire du code Java en Python ? Karpathy pose cette question perspicace, et aller dans cette direction n'est pas un principe, c'est impossible, mais ce n’est pas facile non plus et cela nécessite une certaine réflexion créative.

Néanmoins, Karpathy estime que si ce problème difficile peut être résolu, les modèles de langage ont le potentiel de véritablement égaler, voire surpasser, les capacités humaines de résolution de problèmes. Ce point de vue coïncide avec un article récent publié par Google DeepMind, qui soulignait que l'ouverture est le fondement de l'intelligence artificielle générale (AGI).
En tant que l'un des nombreux experts senior en IA qui ont quitté OpenAI cette année, Karpathy travaille actuellement sur sa propre startup d'IA éducative. Ses remarques ont sans aucun doute injecté une nouvelle dimension de réflexion dans le domaine de la recherche en IA et ont fourni des informations précieuses sur l’orientation future du développement de l’IA.
Les opinions de Karpathy ont suscité de larges discussions dans l'industrie. Les partisans estiment qu’il révèle un problème clé dans la recherche actuelle sur l’IA, à savoir comment rendre l’IA réellement capable de résoudre des problèmes complexes plutôt que de simplement imiter le comportement humain. Les opposants craignent qu’un abandon prématuré du RLHF puisse conduire à une déviation dans la direction du développement de l’IA.
Adresse papier : https://arxiv.org/pdf/1706.03741
Les opinions de Karpathy ont déclenché des discussions approfondies sur l'orientation future du développement de l'IA. Ses doutes sur le RLHF ont incité les chercheurs à réexaminer les méthodes actuelles de formation en IA et à explorer des voies plus efficaces, dans le but ultime de parvenir à une véritable intelligence artificielle.