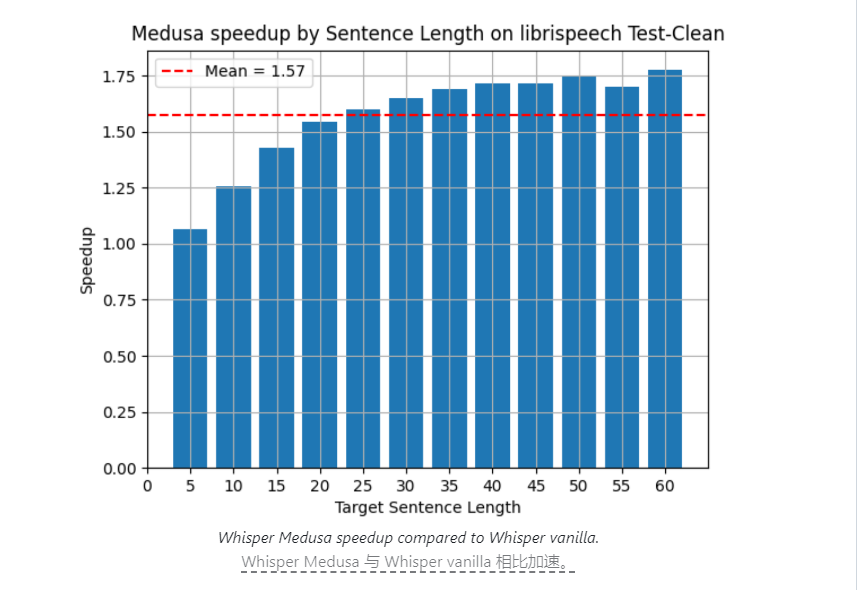
La société israélienne d'intelligence artificielle aiOla a récemment publié un modèle de reconnaissance vocale open source appelé Whisper Medusa. Le modèle a réalisé une avancée significative en termes de vitesse et sa vitesse de traitement est 50 % plus rapide que le modèle Whisper d'OpenAI. Cette percée a attiré une large attention dans l'industrie et son noyau réside dans une conception architecturale améliorée et des méthodes de formation innovantes. Whisper Medusa est non seulement plus rapide, mais maintient également un haut niveau de précision et de stabilité, ouvrant ainsi de nouvelles possibilités au développement de la technologie de reconnaissance vocale.
La société israélienne d’intelligence artificielle aiOla a récemment réalisé une percée majeure dans le domaine de la technologie de reconnaissance vocale et a lancé un modèle de reconnaissance vocale open source appelé Whisper Medusa. La vitesse de traitement de ce nouveau modèle est 50 % plus rapide que celle du modèle Whisper d'OpenAI, qui a attiré une large attention dans l'industrie.
La principale innovation de Whisper Medusa est sa conception architecturale améliorée. aiOla a modifié l'architecture originale de Whisper et introduit un mécanisme d'attention multi-têtes. Ce mécanisme permet au modèle de se concentrer simultanément sur les informations provenant de différents sous-espaces de représentation en utilisant plusieurs têtes d'attention en parallèle. Cette innovation permet au modèle de prédire dix jetons à la fois au lieu d'un jeton traditionnel à la fois, améliorant ainsi considérablement la vitesse de prédiction vocale et la durée d'exécution de la génération.
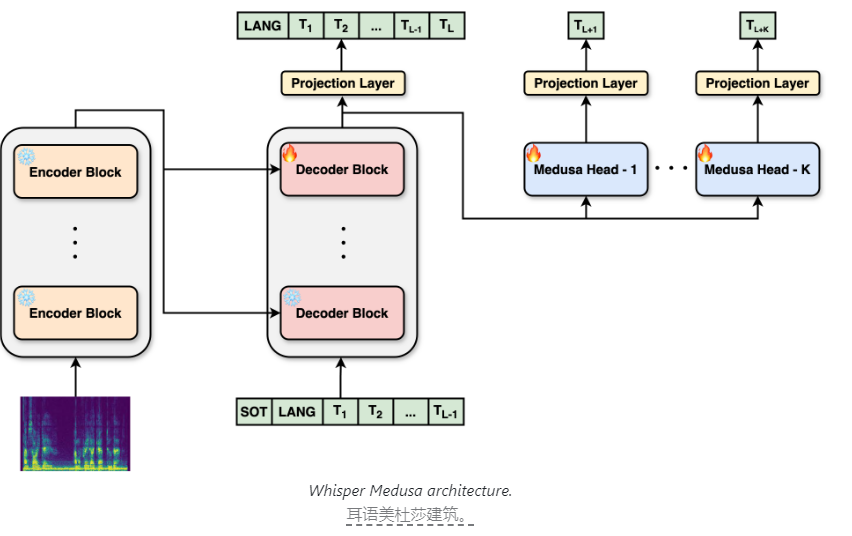
Il convient de noter que Whisper Medusa augmente la vitesse sans sacrifier les performances. Cela est dû au fait que son système principal est toujours basé sur Whisper, garantissant la précision et la stabilité du modèle. Pendant le processus de formation, aiOla utilise une méthode d'apprentissage automatique appelée supervision faible. Plus précisément, ils ont gelé les principaux composants de Whisper et ont utilisé les transcriptions audio générées par le modèle comme étiquettes pour former des modules de prédiction de jetons supplémentaires. Cette méthode de formation innovante améliore encore l’efficacité et la précision de l’apprentissage du modèle.
La sortie open source de Whisper Medusa pourrait avoir un impact profond sur le développement de la technologie de reconnaissance vocale. Non seulement il fournit aux chercheurs et aux développeurs un nouvel outil puissant, mais il pourrait également favoriser le développement d'applications de traitement de la parole plus rapides et plus efficaces. Dans le contexte de la demande croissante d’interaction vocale, cette avancée technologique ouvrira sans aucun doute de nouvelles possibilités d’application de l’intelligence artificielle dans le domaine de la reconnaissance vocale.
Avec le lancement de Whisper Medusa, nous pouvons nous attendre à voir davantage d'applications innovantes basées sur ce modèle, des assistants intelligents à la traduction en temps réel en passant par les systèmes de commande vocale, qui pourraient toutes bénéficier d'améliorations significatives des performances. Ces progrès marquent non seulement une étape importante dans la technologie de reconnaissance vocale, mais dressent également un plan plus efficace et plus fluide pour l’avenir de l’interaction entre l’intelligence artificielle et les humains.
Adresse du projet : https://github.com/aiola-lab/whisper-medusa
visage câlin : https://huggingface.co/aiola/whisper-medusa-v1
L'open source et les hautes performances de Whisper Medusa indiquent que la technologie de reconnaissance vocale inaugurera une nouvelle vague de développement, apportant une expérience plus fluide et plus efficace à diverses applications vocales et promouvant l'application de la technologie de l'intelligence artificielle dans davantage de domaines. Nous sommes impatients de voir émerger davantage d’applications innovantes basées sur ce modèle.