Le développement rapide des grands modèles de langage (LLM) a apporté d’étonnantes capacités de traitement du langage naturel, mais leurs énormes besoins en matière de calcul et de stockage limitent leur popularité. L’exécution d’un modèle avec 176 milliards de paramètres nécessite des centaines de gigaoctets d’espace de stockage et plusieurs GPU haut de gamme, ce qui le rend coûteux et difficile à mettre à l’échelle. Pour résoudre ce problème, les chercheurs se sont concentrés sur les techniques de compression des modèles, telles que la quantification, afin de réduire la taille du modèle et les exigences d'exécution, mais elles sont également confrontées au risque de perte de précision.
L'intelligence artificielle (IA) devient de plus en plus intelligente, en particulier les grands modèles de langage (LLM), qui sont remarquables dans le traitement du langage naturel. Mais le saviez-vous ? Derrière ces cerveaux intelligents d’IA, une puissance de calcul et un espace de stockage énormes sont nécessaires pour les prendre en charge.
Un modèle Bloom multilingue avec 176 milliards de paramètres nécessite au moins 350 Go d'espace rien que pour stocker les poids du modèle, et son fonctionnement nécessite également plusieurs GPU avancés. C’est non seulement coûteux, mais aussi difficile à vulgariser.
Afin de résoudre ce problème, les chercheurs ont proposé une technique appelée « quantification ». La quantification revient à « réduire la taille » du cerveau de l'IA. En mappant les poids et les activations du modèle dans un format de données à chiffres inférieurs, elle réduit non seulement la taille du modèle, mais accélère également la vitesse d'exécution du modèle. Mais ce processus comporte également des risques, et une certaine précision peut être perdue.
Face à ce défi, des chercheurs de l'Université Beihang et de SenseTime Technology ont développé conjointement la boîte à outils LLMC. LLMC est comme un coach personnel de perte de poids pour l'IA. Il peut aider les chercheurs et les développeurs à trouver le plan de perte de poids le plus approprié, ce qui peut alléger le modèle d'IA sans affecter son niveau d'intelligence.
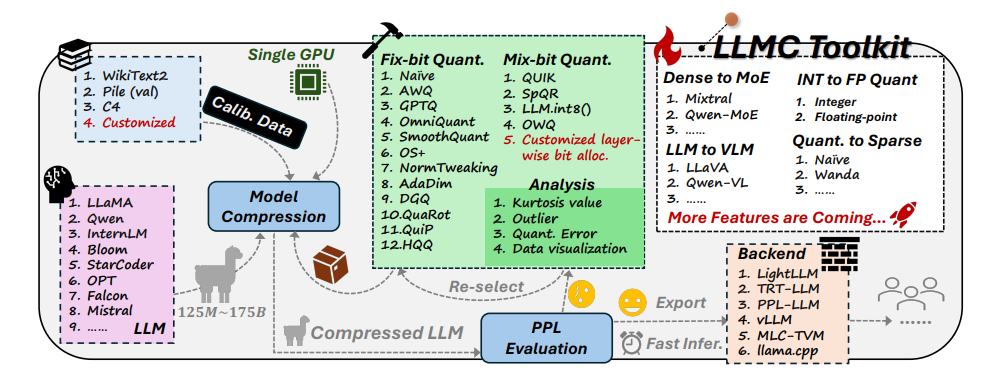
La boîte à outils LLMC comporte trois fonctionnalités principales :
Diversification : LLMC propose 16 méthodes quantitatives différentes, ce qui revient à préparer 16 recettes de perte de poids différentes pour l'IA. Que votre IA souhaite perdre du poids partout ou localement, LLMC peut répondre à vos besoins.
Faible coût : LLMC est très économe en ressources et ne nécessite que peu de support matériel, même pour le traitement de très grands modèles. Par exemple, en utilisant seulement un GPU A100 de 40 Go, le modèle OPT-175B avec 175 milliards de paramètres peut être ajusté et évalué. C’est aussi efficace que d’utiliser un tapis roulant domestique pour entraîner un champion olympique !
Haute compatibilité : LLMC prend en charge une variété de paramètres de quantification et de formats de modèles, et est également compatible avec une variété de backends et de plates-formes matérielles. C'est comme un entraîneur universel qui peut vous aider à élaborer un plan d'entraînement adapté quel que soit l'équipement que vous utilisez.
Applications pratiques du LLMC : rendre l'IA plus intelligente et plus économe en énergie
L'émergence de la boîte à outils LLMC fournit un test de référence complet et équitable pour la quantification de grands modèles de langage. Il prend en compte trois facteurs clés : les données d'entraînement, l'algorithme et le format des données pour aider les utilisateurs à trouver la meilleure solution d'optimisation des performances.
Dans les applications pratiques, LLMC peut aider les chercheurs et les développeurs à intégrer plus efficacement les algorithmes appropriés et les formats low-bit, favorisant ainsi la vulgarisation de la compression de grands modèles de langage. Cela signifie que nous pourrions voir à l’avenir des applications d’IA plus légères mais tout aussi puissantes.
Les auteurs de l’article ont également partagé quelques conclusions et suggestions intéressantes :
Lors de la sélection des données d'entraînement, vous devez choisir un ensemble de données plus similaire aux données de test en termes de répartition du vocabulaire, tout comme lorsque les humains perdent du poids, ils doivent choisir des recettes appropriées en fonction de leur propre situation.
En termes d’algorithmes de quantification, ils ont exploré l’impact des trois principales techniques de transformation, de recadrage et de reconstruction, tout comme comparer les effets de différentes méthodes d’exercice sur la perte de poids.
En choisissant entre la quantification entière et la quantification à virgule flottante, ils ont constaté que la quantification à virgule flottante présente plus d'avantages dans la gestion de situations complexes, tandis que la quantification entière peut être meilleure dans certains cas particuliers. C'est comme si différentes intensités d'exercice étaient nécessaires à différentes étapes de la perte de poids.
L'avènement de la boîte à outils LLMC a apporté une nouvelle tendance dans le domaine de l'IA. Il fournit non seulement un assistant puissant aux chercheurs et aux développeurs, mais indique également la direction du développement futur de l’IA. Grâce à LLMC, nous pouvons nous attendre à voir des applications d’IA plus légères et plus performantes, permettant à l’IA de véritablement entrer dans notre vie quotidienne.
Adresse du projet : https://github.com/ModelTC/llmc
Adresse papier : https://arxiv.org/pdf/2405.06001
Dans l'ensemble, la boîte à outils LLMC fournit une solution efficace pour résoudre le problème de consommation de ressources des grands modèles de langage. Elle réduit non seulement le coût et le seuil de fonctionnement du modèle, mais améliore également l'efficacité et la convivialité du modèle, en injectant une injection dans le modèle. vulgarisation et développement de l’IA. À l’avenir, nous pouvons nous attendre à l’émergence d’applications d’IA plus légères basées sur LLMC, apportant plus de commodité à nos vies.