Dans le domaine en plein essor de l’IA, les méthodes d’acquisition de données deviennent de plus en plus au centre de l’attention. Cet article explore la controverse provoquée par le comportement de grattage de données à grande échelle de l'équipe Claude de la société d'IA Anthropic. Le programme d'exploration de l'équipe Claude, ClaudeBot, a exploré une grande quantité de données provenant de plusieurs sites Web sans autorisation, ce qui a non seulement violé les réglementations du site Web, mais a également provoqué une énorme consommation de ressources du serveur, déclenchant de nombreuses critiques et inquiétudes. Cet incident met en évidence la contradiction entre le développement de l’IA et la protection des droits d’auteur sur les données, incitant l’industrie à repenser l’éthique et les normes juridiques de l’acquisition de données.
La cause de l'incident était que le robot d'exploration de l'équipe de Claude a visité le serveur d'une entreprise 1 million de fois en 24 heures, explorant gratuitement le contenu d'un site Web. Ce comportement a non seulement ignoré de manière flagrante l'annonce d'interdiction d'exploration du site Web, mais a également occupé de force une grande quantité de ressources du serveur.
Malgré tous ses efforts pour se défendre, l'entreprise victime n'a finalement pas réussi à empêcher l'équipe de Claude de récupérer les données. Les dirigeants de l'entreprise se sont tournés avec colère vers les médias sociaux pour condamner les actions de l'équipe de Claude. De nombreux internautes ont également exprimé leur mécontentement, et certains ont même suggéré d'utiliser le mot vol pour décrire ce comportement.
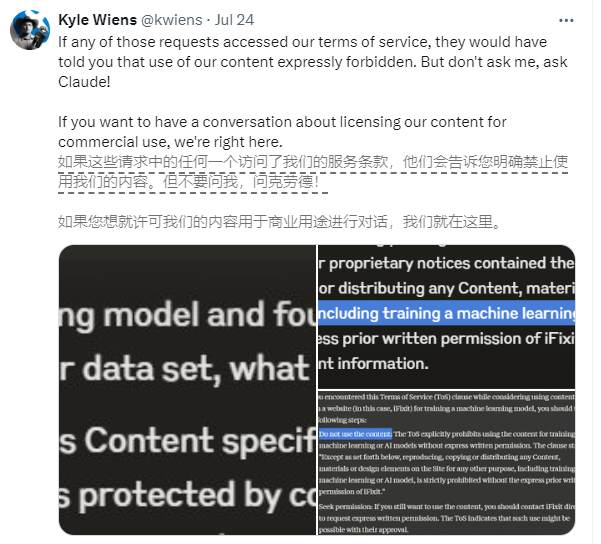
La société impliquée est iFixit, un site américain de commerce électronique et de procédures. iFixit propose des millions de pages de guides de réparation en ligne gratuits couvrant les appareils électroniques grand public et les gadgets. Cependant, iFixit a découvert que le programme d'exploration de Claude, ClaudeBot, avait lancé un grand nombre de requêtes en peu de temps, accédant à 10 To de fichiers en une journée et à un total de 73 To sur tout le mois de mai.
Le PDG d'iFixit, Kyle Wiens, a déclaré que ClaudeBot avait volé toutes leurs données sans autorisation et occupé les ressources du serveur. Bien qu'iFixit indique explicitement sur son site Web que le grattage de données non autorisé est interdit, l'équipe Claude semble fermer les yeux sur ce point.
Le comportement de l'équipe de Claude n'est pas unique. En avril de cette année, le forum Linux Mint a également souffert des visites fréquentes de ClaudeBot, ce qui a entraîné un ralentissement, voire un crash du forum. En outre, certaines voix ont souligné qu'en plus de Claude et du GPT d'OpenAI, de nombreuses autres sociétés d'IA ignorent également les paramètres robots.txt du site Web et récupèrent de force des données.
Face à cette situation, il a été suggéré aux propriétaires de sites Web d'ajouter à la page du faux contenu contenant des informations traçables ou uniques pour détecter si les données ont été illégalement récupérées. iFixit a en fait franchi cette étape et a découvert que leurs données avaient été récupérées non seulement par Claude, mais également par OpenAI.
L’incident a suscité de nombreuses discussions sur les pratiques de récupération de données des sociétés d’IA. D’une part, le développement de l’IA nécessite une grande quantité de données pour la prendre en charge ; d’autre part, la capture des données doit également respecter les droits et réglementations du propriétaire du site Web. Comment trouver un équilibre entre la promotion du progrès technologique et la protection du droit d’auteur est une question à laquelle l’ensemble du secteur doit réfléchir.
L'incident de saisie de données de l'équipe de Claude a tiré la sonnette d'alarme, rappelant aux entreprises d'IA que tout en poursuivant le progrès technologique, elles doivent respecter les droits de propriété intellectuelle, se conformer aux lois et réglementations et explorer activement des moyens conformes d'obtenir des données. Ce n’est qu’ainsi que nous pourrons garantir le développement sain de la technologie de l’IA et éviter de nuire à la réputation de l’industrie et à la confiance du public en raison d’un comportement inapproprié.