Le nouveau modèle de langage Zamba2-2.7B de Zyphra fait des vagues dans le domaine des petits modèles de langage. Ce modèle réduit considérablement les besoins en ressources d'inférence tout en conservant des performances comparables à celles du modèle 7B, ce qui le rend idéal pour les applications sur appareils mobiles. Zamba2-2.7B a considérablement amélioré la vitesse de réponse, l'utilisation de la mémoire et la latence, ce qui est crucial pour les applications nécessitant une interaction en temps réel, telles que les assistants virtuels et les chatbots. Son mécanisme d'attention partagée entrelacé amélioré et son projecteur LoRA garantissent un traitement efficace des tâches complexes.
Récemment, Zyphra a publié le nouveau modèle de langage Zamba2-2.7B. Cette version revêt une grande importance dans l'histoire du développement des petits modèles de langage. Le nouveau modèle réalise des améliorations significatives en termes de performances et d'efficacité, avec son ensemble de données de formation atteignant environ 3 000 milliards de jetons, ce qui le rend comparable en termes de performances à Zamba1-7B et à d'autres modèles 7B leaders.
Le plus surprenant est que les besoins en ressources de Zamba2-2.7B lors de l'inférence sont considérablement réduits, ce qui en fait une solution efficace pour les applications sur appareils mobiles.
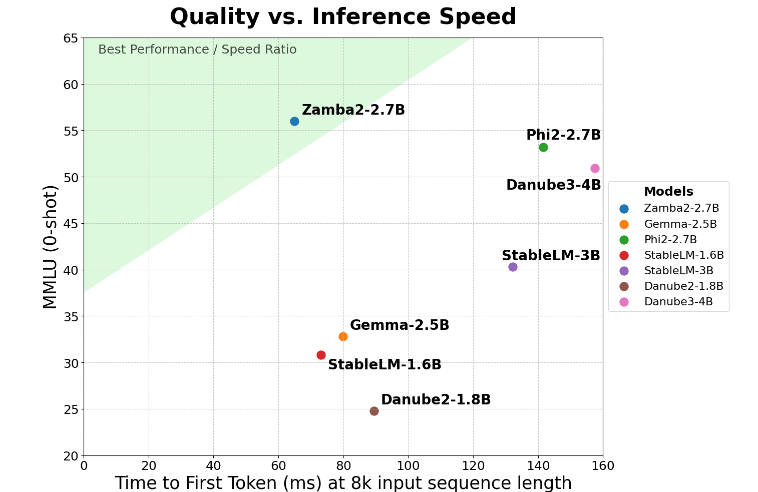
Zamba2-2.7B parvient à doubler la mesure clé du « temps de réponse de première génération », ce qui signifie qu'il peut générer des réponses initiales plus rapidement que la concurrence. Ceci est essentiel pour les applications telles que les assistants virtuels et les chatbots qui nécessitent une interaction en temps réel.
En plus de l'amélioration de la vitesse, Zamba2-2.7B fait également un excellent travail en termes d'utilisation de la mémoire. Il réduit la surcharge de mémoire de 27 %, ce qui le rend idéal pour le déploiement sur des appareils disposant de ressources mémoire limitées. Une telle gestion intelligente de la mémoire garantit que le modèle peut fonctionner efficacement dans des environnements dotés de ressources informatiques limitées, élargissant ainsi sa portée d'application sur divers appareils et plates-formes.
Zamba2-2.7B présente également l'avantage significatif d'une latence de construction plus faible. Par rapport au Phi3-3.8B, sa latence est réduite de 1,29 fois, ce qui rend l'interaction plus fluide. Une faible latence est particulièrement importante dans les applications qui nécessitent une communication transparente et continue, telles que les robots du service client et les outils pédagogiques interactifs. Par conséquent, Zamba2-2.7B est sans aucun doute le premier choix des développeurs en termes d’amélioration de l’expérience utilisateur.
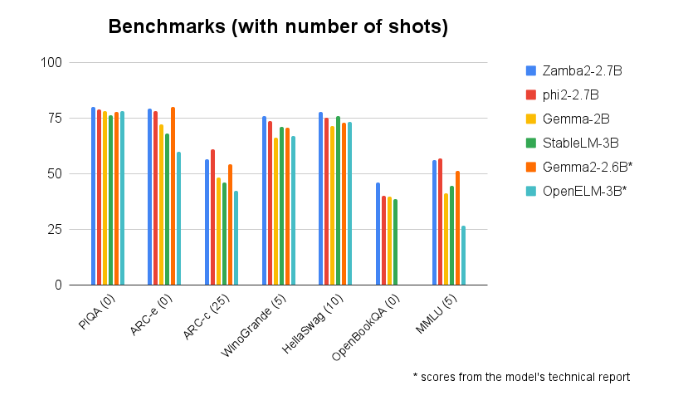
Le Zamba2-2.7B surpasse systématiquement les comparaisons avec d'autres modèles de taille similaire. Ses performances supérieures prouvent l'innovation et les efforts de Zyphra pour promouvoir le développement de la technologie de l'intelligence artificielle. Ce modèle utilise un mécanisme d'attention partagée entrelacée amélioré et est équipé d'un projecteur LoRA sur un module MLP partagé pour garantir une sortie haute performance lors du traitement de tâches complexes.
Entrée du modèle : https://huggingface.co/Zyphra/Zamba2-2.7B
Points forts:
Le modèle Zamba2-27B double le premier temps de réponse, ce qui le rend adapté aux applications interactives en temps réel.
? Ce modèle réduit la surcharge de mémoire de 27 % et convient aux appareils aux ressources limitées.
En termes de délai de génération, le Zamba2-2.7B surpasse les modèles similaires, améliorant ainsi l'expérience utilisateur.
En bref, Zamba2-2.7B a établi une nouvelle référence pour les petits modèles de langage avec ses excellentes performances et efficacité, offrant aux développeurs des outils d'IA plus puissants et plus flexibles, et devrait jouer un rôle important dans les applications mobiles. Son utilisation efficace des ressources et son expérience utilisateur fluide en font un moteur clé pour le développement de futures applications d’IA.