L’expérience de Meta dans la formation du modèle linguistique à grande échelle Llama 3.1 nous a montré des défis et des opportunités sans précédent dans le développement de l’IA. L'énorme cluster de 16 384 GPU a connu une panne moyenne toutes les 3 heures au cours de la période de formation de 54 jours. Cela a non seulement mis en évidence la croissance rapide de l'échelle du modèle d'IA, mais a également révélé l'énorme goulot d'étranglement dans la stabilité du supercalcul. système. Cet article examinera les défis rencontrés par Meta au cours du processus de formation Llama 3.1, les stratégies qu'ils ont adoptées pour relever ces défis et analysera ses implications pour l'ensemble de l'industrie de l'IA.
Dans le monde de l’intelligence artificielle, chaque avancée s’accompagne de données à couper le souffle. Imaginez que 16 384 GPU fonctionnent en même temps. Ce n'est pas une scène d'un film de science-fiction, mais une véritable représentation de Meta lors de l'entraînement du dernier modèle Llama3.1. Pourtant, derrière ce festin technologique se cache une panne qui survient en moyenne toutes les 3 heures. Ce chiffre étonnant démontre non seulement la rapidité du développement de l’IA, mais révèle également les énormes défis auxquels est confrontée la technologie actuelle.
Des 2 028 GPU utilisés dans Llama1 aux 16 384 GPU utilisés dans Llama3.1, cette croissance rapide n'est pas seulement un changement en quantité, mais aussi un défi extrême pour la stabilité du système de calcul intensif existant. Les données de recherche de Meta montrent qu'au cours du cycle de formation de 54 jours de Llama3.1, un total de 419 pannes inattendues de composants se sont produites, dont environ la moitié étaient liées au GPU H100 et à sa mémoire HBM3. Ces données nous obligent à réfléchir : tout en poursuivant des percées dans les performances de l'IA, la fiabilité du système s'est-elle également améliorée en même temps ?
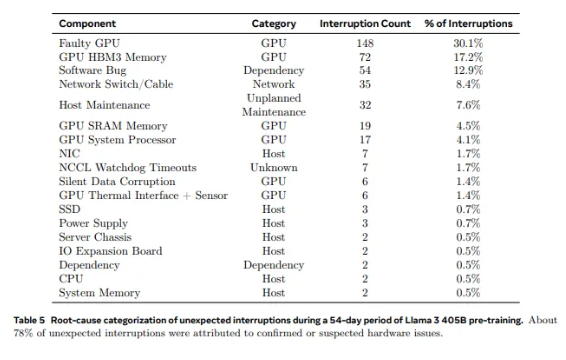
En fait, il existe un fait incontestable dans le domaine du calcul intensif : plus l’échelle est grande, plus il est difficile d’éviter les pannes. Le cluster de formation Llama 3.1 de Meta se compose de dizaines de milliers de processeurs, de centaines de milliers d’autres puces et de centaines de kilomètres de câbles, un niveau de complexité comparable à celui du réseau neuronal d’une petite ville. Dans un tel mastodonte, les dysfonctionnements semblent être monnaie courante.
Face aux échecs fréquents, l’équipe Meta n’était pas démunie. Ils ont adopté une série de stratégies d’adaptation : réduire les temps de démarrage des tâches et des points de contrôle, développer des outils de diagnostic propriétaires, tirer parti de l’enregistreur de vol NCCL de PyTorch, etc. Ces mesures améliorent non seulement la tolérance aux pannes du système, mais améliorent également les capacités de traitement automatisé. Les ingénieurs de Meta sont comme des pompiers des temps modernes, prêts à éteindre tout incendie susceptible de perturber le processus de formation.
Cependant, les défis ne viennent pas uniquement du matériel lui-même. Les facteurs environnementaux et les fluctuations de la consommation d’énergie posent également des défis inattendus aux clusters de calcul intensif. L'équipe Meta a découvert que les changements de température diurnes et nocturnes et les fluctuations drastiques de la consommation électrique du GPU auront un impact significatif sur les performances d'entraînement. Cette découverte nous rappelle que tout en poursuivant les avancées technologiques, nous ne pouvons ignorer l’importance de la gestion de l’environnement et de la consommation énergétique.
Le processus de formation de Llama3.1 peut être qualifié de test ultime de la stabilité et de la fiabilité du système de calcul intensif. Les stratégies adoptées par l'équipe Meta pour relever les défis et les outils automatisés développés fournissent une expérience et une inspiration précieuses à l'ensemble de l'industrie de l'IA. Malgré les difficultés, nous avons des raisons de croire qu’avec les progrès continus de la technologie, les futurs systèmes de calcul intensif seront plus puissants et plus stables.
À l’ère du développement rapide de la technologie de l’IA, la tentative de Meta est sans aucun doute une aventure courageuse. Cela repousse non seulement les limites de performances des modèles d’IA, mais nous montre également les véritables défis auxquels nous sommes confrontés pour atteindre ces limites. Attendons avec impatience les possibilités infinies offertes par la technologie de l’IA, tout en félicitant les ingénieurs qui travaillent sans relâche à la pointe de la technologie. Chaque tentative, chaque échec et chaque percée qu’ils réalisent ouvrent la voie au progrès technologique humain.
Références :
https://www.tomshardware.com/tech-industry/artificial-intelligence/faulty-nvidia-h100-gpus-and-hbm3-memory-caused-half-of-the-failures-during-llama-3-training- un échec toutes les trois heures pour le cluster de formation métas-16384-gpu
Le cas de formation de Llama 3.1 nous a fourni de précieuses leçons et a souligné l'orientation future du développement des systèmes de calcul intensif : tout en recherchant la performance, nous devons attacher une grande importance à la stabilité et à la fiabilité du système et explorer activement des stratégies pour faire face à diverses pannes. Ce n’est qu’ainsi que nous pourrons garantir le développement continu et stable de la technologie de l’IA et qu’elle profitera à l’humanité.