Le métascientifique Thomas Scialom a expliqué en détail le processus de développement de Llama 3.1 sur le podcast Latent Space et a donné un aperçu de l'orientation du développement de Llama 4. Llama 3.1 n'est pas un simple empilement de paramètres, mais un compromis entre la taille des paramètres, le temps de formation et les limitations matérielles. Sa taille de paramètre 405B est une réponse à GPT-4o. Bien que la taille énorme du modèle rende difficile son exécution sur des ordinateurs ordinaires, la fonctionnalité open source permet à davantage de personnes de participer et de promouvoir le développement technologique.
La naissance de Llama3.1 est un équilibre parfait entre l'échelle des paramètres, le temps de formation et les limitations matérielles. L'énorme corps du 405B n'est pas un choix aléatoire, mais un défi lancé par Meta au GPT-4o. Bien que les limitations matérielles empêchent Llama3.1 de fonctionner sur tous les ordinateurs personnels, la puissance de la communauté open source rend tout possible.
Lors du développement de Llama 3.1, Scialom et son équipe ont réexaminé Scaling Law. Ils ont constaté que la taille du modèle était effectivement essentielle, mais que la quantité totale de données d’entraînement était plus importante. Llama3.1 a choisi d'augmenter le nombre de jetons d'entraînement, même si cela impliquait de dépenser plus de puissance de calcul.
Il n'y a pas de changements bouleversants dans l'architecture de Llama 3.1, mais Meta a fait de gros efforts en termes d'échelle et de qualité des données. L'océan de jetons 15T a donné à Llama3.1 un saut qualitatif dans la profondeur et l'étendue des connaissances.
En termes de sélection de données, Sciom croit fermement qu'il y a trop de déchets de texte sur l'Internet public et que le véritable or réside dans les données synthétiques. Dans le processus post-formation de Llama3.1, aucune réponse écrite manuellement n'a été utilisée, mais s'est entièrement appuyée sur les données synthétiques générées par Llama2.
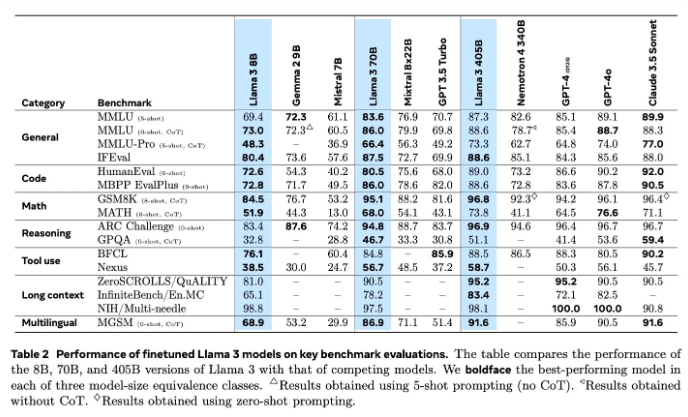
L'évaluation des modèles a toujours été un problème difficile dans le domaine de l'IA. Llama3.1 a essayé diverses méthodes d'évaluation et d'amélioration, notamment des modèles de récompense et divers tests de référence. Mais le véritable défi consiste à trouver les bonnes invites capables de vaincre les modèles puissants.
Meta a commencé la formation de Llama4 en juin, et cette fois, ils se sont concentrés sur la technologie des agents. Le développement d’outils d’agents tels que Toolformer annonce la nouvelle exploration de Meta dans le domaine de l’IA.
L'open source de Llama3.1 n'est pas seulement une tentative audacieuse de Meta, mais aussi une réflexion profonde sur l'avenir de l'IA. Avec le lancement de Llama4, nous avons des raisons de croire que Meta continuera à montrer la voie en matière d'IA. Attendons avec impatience de voir comment Llama4 et la technologie des agents redéfiniront l'avenir de l'IA.
Grâce à une compréhension approfondie du processus de R&D de Llama 3.1, nous pouvons constater l'innovation et les efforts continus de Meta dans le domaine des modèles de langage à grande échelle, ainsi que l'accent mis sur la communauté open source. L'orientation de la recherche et du développement de Llama 4 indique également la tendance future du développement de la technologie de l'IA, qui mérite d'être attendue et surveillée. Attendons avec impatience de voir comment la technologie de l’IA se développera à l’avenir.