NVIDIA a récemment publié la série Minitron de petits modèles linguistiques, comprenant les versions 4B et 8B. Cette décision vise à réduire les coûts de formation et de déploiement des grands modèles de langage et à permettre à davantage de développeurs d'utiliser facilement cette technologie avancée. Grâce aux technologies « d'élagage » et de « distillation des connaissances », le modèle Minitron réduit considérablement la taille du modèle tout en conservant des performances comparables aux grands modèles, et surpasse même d'autres modèles bien connus dans certains indicateurs. Cela revêt une grande importance pour promouvoir la vulgarisation de la technologie de l’intelligence artificielle.
Récemment, NVIDIA a fait de nouveaux progrès dans le domaine de l'intelligence artificielle. Ils ont lancé la série Minitron de petits modèles de langage, comprenant les versions 4B et 8B. Ces modèles multiplient non seulement la vitesse de formation par 40, mais permettent également aux développeurs de les utiliser plus facilement pour diverses applications, telles que la traduction, l'analyse des sentiments et l'IA conversationnelle.
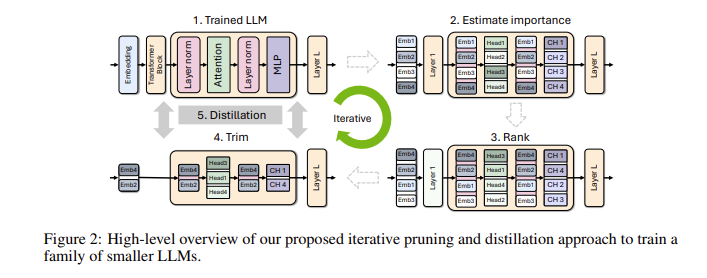
Vous vous demandez peut-être pourquoi les petits modèles de langage sont-ils si importants ? En fait, bien que les grands modèles de langage traditionnels aient de bonnes performances, leurs coûts de formation et de déploiement sont très élevés et nécessitent souvent une grande quantité de ressources informatiques et de données. Afin de rendre ces technologies avancées abordables pour un plus grand nombre de personnes, l'équipe de recherche de NVIDIA a trouvé une solution brillante : combiner deux technologies : « l'élagage » et la « distillation des connaissances » pour réduire efficacement la taille du modèle.
Plus précisément, les chercheurs partiront d’un grand modèle existant et l’élagueront. Ils évaluent l’importance de chaque neurone, couche ou tête d’attention dans le modèle et suppriment ceux qui sont moins importants. De cette façon, le modèle devient beaucoup plus petit, et les ressources et le temps nécessaires à la formation sont également considérablement réduits. Ensuite, ils utiliseront également un ensemble de données à petite échelle pour effectuer une formation de distillation des connaissances sur le modèle élagué afin de restaurer la précision du modèle. Étonnamment, ce processus permet non seulement d'économiser de l'argent, mais améliore également les performances du modèle !
Lors de tests réels, l'équipe de recherche de NVIDIA a obtenu de bons résultats sur la famille de modèles Nemotron-4. Ils ont réussi à réduire la taille du modèle de 2 à 4 fois tout en conservant des performances similaires. Ce qui est encore plus excitant, c'est que le modèle 8B surpasse d'autres modèles bien connus tels que Mistral7B et LLaMa-38B dans de nombreux indicateurs, et nécessite 40 fois moins de données d'entraînement pendant le processus d'entraînement, ce qui permet d'économiser 1,8 fois les coûts de calcul. Imaginez ce que cela signifie ? Un plus grand nombre de développeurs peuvent bénéficier de puissantes capacités d'IA avec moins de ressources et de coûts !
NVIDIA rend ces modèles Minitron optimisés open source sur Huggingface pour que tout le monde puisse les utiliser librement.
Entrée démo : https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Points forts:
** Vitesse de formation améliorée ** : la vitesse de formation du modèle Minitron est 40 fois plus rapide que celle des modèles traditionnels, permettant aux développeurs d'économiser du temps et des efforts.
**Économies de coûts** : grâce à la technologie d'élagage et de distillation des connaissances, les ressources informatiques et le volume de données requis pour la formation sont considérablement réduits.
? **Partage open source** : Le modèle Minitron a été open source sur Huggingface, afin que davantage de personnes puissent facilement y accéder et l'utiliser, favorisant ainsi la vulgarisation de la technologie de l'IA.
L'open source du modèle Minitron marque une avancée importante dans l'application pratique des petits modèles de langage. Elle indique également que la technologie de l'intelligence artificielle deviendra plus populaire et plus facile à utiliser, permettant ainsi à davantage de développeurs et de scénarios d'application. À l’avenir, nous pouvons nous attendre à davantage d’innovations similaires favorisant le développement continu de la technologie de l’intelligence artificielle.