Le dernier modèle ChatQA2 publié par Nvidia AI a réalisé des avancées significatives dans le domaine de la compréhension du contexte des textes longs et de la génération améliorée (RAG). Il est basé sur le puissant modèle Llama3, qui améliore considérablement les capacités de suivi des instructions, les performances RAG et les capacités de compréhension des textes longs en étendant la fenêtre contextuelle à 128 000 jetons et en adoptant un réglage fin des instructions en trois étapes. ChatQA2 est capable de maintenir une cohérence contextuelle et un rappel élevé lors du traitement de données textuelles massives, et a démontré des performances comparables à GPT-4-Turbo dans plusieurs tests de référence, et les a même surpassées dans certains aspects. Cela marque une avancée significative dans la capacité des grands modèles linguistiques à gérer des textes longs.
Percée en matière de performances : ChatQA2 améliore considérablement les capacités de suivi des instructions, les performances RAG et la compréhension des textes longs en étendant la fenêtre contextuelle à 128 000 jetons et en adoptant un processus d'ajustement des instructions en trois étapes. Cette avancée technologique permet au modèle de maintenir une cohérence contextuelle et un rappel élevé lors du traitement d'ensembles de données pouvant atteindre 1 milliard de jetons.
Détails techniques : ChatQA2 a été développé à l'aide de solutions techniques détaillées et reproductibles. Le modèle étend d'abord la fenêtre contextuelle de Llama3-70B de 8 000 à 128 000 jetons grâce à une pré-formation continue. Ensuite, un processus de réglage des instructions en trois étapes a été appliqué pour garantir que le modèle puisse gérer efficacement une variété de tâches.
Résultats de l'évaluation : dans l'évaluation InfiniteBench, ChatQA2 a atteint une précision comparable à GPT-4-Turbo-2024-0409 sur des tâches telles que le résumé de texte long, les questions et réponses, les choix multiples et le dialogue, et l'a surpassé sur le benchmark RAG. Cette réalisation met en évidence les capacités complètes de ChatQA2 dans différentes longueurs de contexte et fonctionnalités.
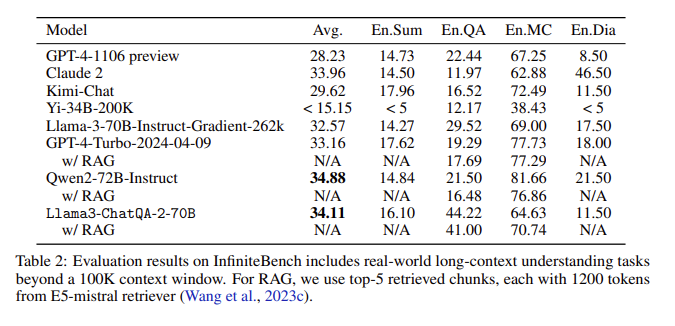
Résolution des problèmes clés : ChatQA2 cible les problèmes clés du processus RAG, tels que la fragmentation du contexte et le faible rappel, en utilisant un outil de récupération de texte long de pointe pour améliorer la précision et l'efficacité de la récupération.
En étendant la fenêtre contextuelle et en mettant en œuvre un processus de réglage des instructions en trois étapes, ChatQA2 permet une compréhension de textes longs et des performances RAG comparables à GPT-4-Turbo. Ce modèle fournit des solutions flexibles pour une variété de tâches en aval, équilibrant précision et efficacité grâce à des techniques avancées de génération de textes longs et de récupération améliorée.
Entrée papier : https://arxiv.org/abs/2407.14482
L'émergence de ChatQA2 apporte de nouvelles possibilités pour le traitement de textes longs et les applications RAG. Son efficacité et sa précision constituent une valeur de référence importante pour le développement futur de l'intelligence artificielle. La recherche ouverte sur ce modèle favorise également la collaboration entre le monde universitaire et l’industrie, favorisant ainsi les progrès continus dans le domaine. Au plaisir de voir des applications plus innovantes basées sur ce modèle à l’avenir.