Llama 3.1, ce modèle de langage open source géant doté de 405 milliards de paramètres, a provoqué un énorme choc dans le domaine de l'IA en raison de fuites sans sortie officielle. Ses performances sont si puissantes qu'elles surpassent même GPT-4o dans certains tests de référence, établissant ainsi une nouvelle référence pour les modèles open source. La discussion animée sur Reddit prouve encore une fois son impact sur la communauté IA. Cet article approfondira les performances, les points forts et les mesures de sécurité de Llama 3.1 et dévoilera ce mystérieux modèle.
Llama3.1 a fuité ! Vous avez bien entendu, ce modèle open source doté de 405 milliards de paramètres a fait sensation sur Reddit. Il s’agit probablement du modèle open source le plus proche de GPT-4o à ce jour, et le surpasse même à certains égards.
Llama3.1 est un grand modèle de langage développé par Meta (anciennement Facebook). Bien qu'il n'y ait pas encore de version officielle, la version divulguée a déjà fait sensation dans la communauté. Ce modèle comprend non seulement le modèle de base, mais également les résultats de référence de 8B, 70B et le paramètre maximum de 405B.
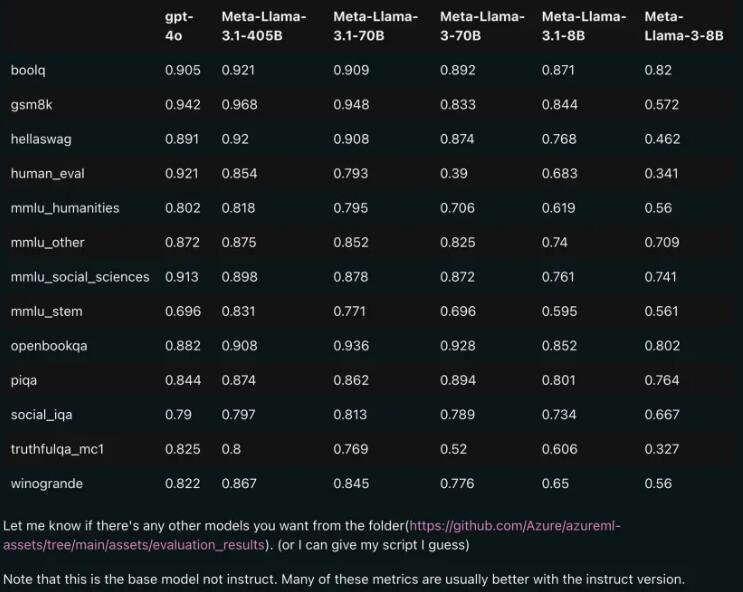
Comparaison des performances : Llama3.1 vs GPT-4o
À en juger par les résultats de comparaison divulgués, même la version 70B de Llama3.1 a surpassé GPT-4o dans plusieurs tests de référence. C’est la première fois qu’un modèle open source atteint le niveau SOTA (State of the Art, la technologie la plus avancée) sur plusieurs benchmarks. Les gens ne peuvent s’empêcher de soupirer : la puissance de l’open source est vraiment puissante !
Points forts du modèle : prise en charge multilingue, données de formation plus riches
Le modèle Llama3.1 utilise plus de 15 T de jetons provenant de sources publiques pour la formation, et la date limite pour les données de pré-formation est décembre 2023. Il prend en charge non seulement l'anglais mais également le français, l'allemand, l'hindi, l'italien, le portugais, l'espagnol et le thaï. Cela le rend idéal dans les cas d’utilisation de conversations multilingues.

L'équipe de recherche de Llama3.1 attache une grande importance à la sécurité du modèle. Ils ont utilisé une approche de collecte de données à multiples facettes combinant des données générées par l'homme et synthétiques pour atténuer les risques de sécurité potentiels. En outre, le modèle introduit également des invites de limites et des invites contradictoires pour améliorer le contrôle de la qualité des données.
Source de la carte modèle : https://pastebin.com/9jGkYbXY#google_vignette
La fuite de Llama 3.1 aura sans aucun doute un impact profond sur le domaine de l'IA. Cela démontre non seulement l’énorme potentiel des modèles open source, mais suscite également une réflexion plus approfondie sur la sécurité des modèles et les questions éthiques. À l'avenir, nous continuerons à prêter attention à Llama 3.1 et à son développement ultérieur, et nous espérons qu'il apportera davantage de surprises à l'avancement de la technologie de l'IA.