La concurrence dans le domaine de l’intelligence artificielle est féroce et la montée en puissance des modèles open source remet en question la domination des géants de la technologie. Récemment, la startup de matériel d'intelligence artificielle Groq a publié deux modèles de langage open source - Llama-3-Groq-70B-Tool-Use et Llama3Groq Tool Use 8B, et a obtenu des résultats impressionnants sur le Berkeley Function Call Ranking (BFCL). Parmi eux, le paramètre 70B La version a surpassé les modèles propriétaires d'OpenAI, Google, Anthropic et d'autres sociétés. Le succès de ces modèles réside non seulement dans leurs performances puissantes, mais également dans leur utilisation de données synthétiques générées de manière éthique pendant le processus de formation, ce qui résout efficacement des problèmes tels que la confidentialité des données et le surajustement, et offre de nouvelles opportunités pour le développement durable du domaine. de l'intelligence artificielle par exemple.
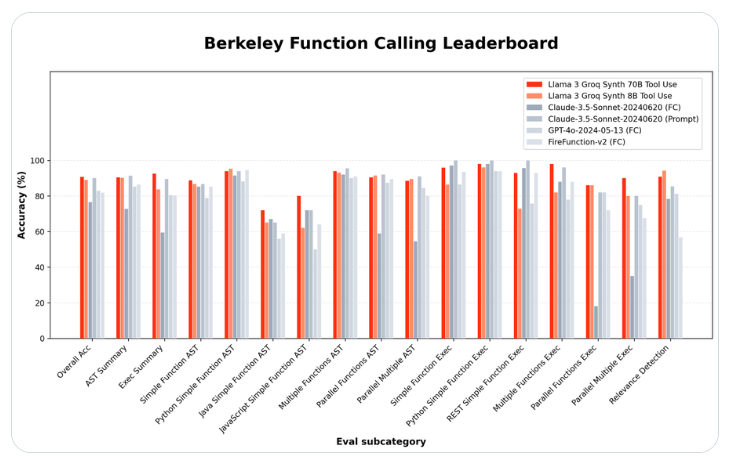
La startup de matériel d'intelligence artificielle Groq a publié deux modèles de langage open source qui surpassent les géants de la technologie dans leur capacité à utiliser des outils spécialisés. Le nouveau modèle Llama-3-Groq-70B-Tool-Use a pris la première place du Berkeley Function Call Ranking (BFCL), dépassant les produits propriétaires tels qu'OpenAI, Google et Anthropic.
Le chef du projet Groq, Rick Lamers, a annoncé cette avancée dans un article de X.com. Il a déclaré : « Je suis fier d'annoncer les modèles Llama3Groq Tool Use 8B et 70B. Il s'agit d'une version entièrement optimisée de l'outil open source de Llama3 qui a atteint la position n°1 sur le BFCL, battant tous les autres modèles, y compris les modèles propriétaires. Tels que Claude Sonnet3.5, GPT-4Turbo, GPT-4o et Gemini1.5Pro.
Données synthétiques et IA éthique : un nouveau paradigme dans la formation de modèles
La version plus grande des paramètres 70B a atteint une précision globale de 90,76 % sur BFCL, tandis que le plus petit modèle 8B a obtenu un score de 89,06 %, se classant troisième au classement général. Ces résultats montrent que les modèles open source peuvent égaler, voire dépasser, les performances des alternatives fermées sur des tâches spécifiques.
Groq a développé les modèles en partenariat avec la société de recherche en intelligence artificielle Glaive, en utilisant un réglage complet et une optimisation directe des préférences (DPO) sur le modèle de base Llama-3 de Meta. L’équipe souligne qu’elle utilise uniquement des données synthétiques générées de manière éthique pour la formation, répondant ainsi aux préoccupations courantes concernant la confidentialité des données et le surapprentissage.
Ces modèles sont désormais disponibles via l'API Groq et la plateforme Hugging Face. Cette accessibilité peut accélérer l'innovation dans les domaines qui nécessitent une utilisation d'outils et des appels de fonctions complexes, tels que le codage automatisé, l'analyse de données et les assistants IA interactifs.
Groq a également lancé une démo publique sur Hugging Face Spaces, permettant aux utilisateurs d'interagir avec le modèle et de tester directement ses capacités d'outils. Comme Gradio, acquis par Hugging Face en décembre 2021, de nombreuses démos sur Hugging Face Spaces sont créées de cette façon. La communauté de l’IA a répondu avec enthousiasme, avec de nombreux chercheurs et développeurs désireux d’explorer les capacités de ces modèles.
Points forts:
⭐ Le modèle d'IA open source publié par Groq surpasse les modèles propriétaires du géant de la technologie pour des tâches spécifiques
⭐ En utilisant des données synthétiques pour la formation, Groq remet en question les problèmes courants de confidentialité des données et de surajustement dans le développement de modèles d'IA.
⭐ Le lancement de modèles open source pourrait changer la voie de développement du domaine de l'IA et promouvoir une accessibilité plus large à l'IA et la culture d'écosystèmes innovants
Le succès du modèle open source Groq a insufflé une nouvelle vitalité au développement du domaine de l'intelligence artificielle et indique également que les modèles open source joueront un rôle de plus en plus important à l'avenir. Son application de données synthétiques fournit de nouvelles idées pour résoudre des problèmes tels que la confidentialité des données et le biais des modèles, qui méritent une étude approfondie et une référence de la part de l'industrie. Nous attendons avec impatience l’émergence d’excellents modèles open source à l’avenir pour promouvoir les progrès continus de la technologie de l’intelligence artificielle.