Gudang data analitik Apache Kylin v4.0.3 versi resmi
4.0.3
Apache Kylin: Alat kueri sub-detik untuk data berskala sangat besar
Editor kode bawah
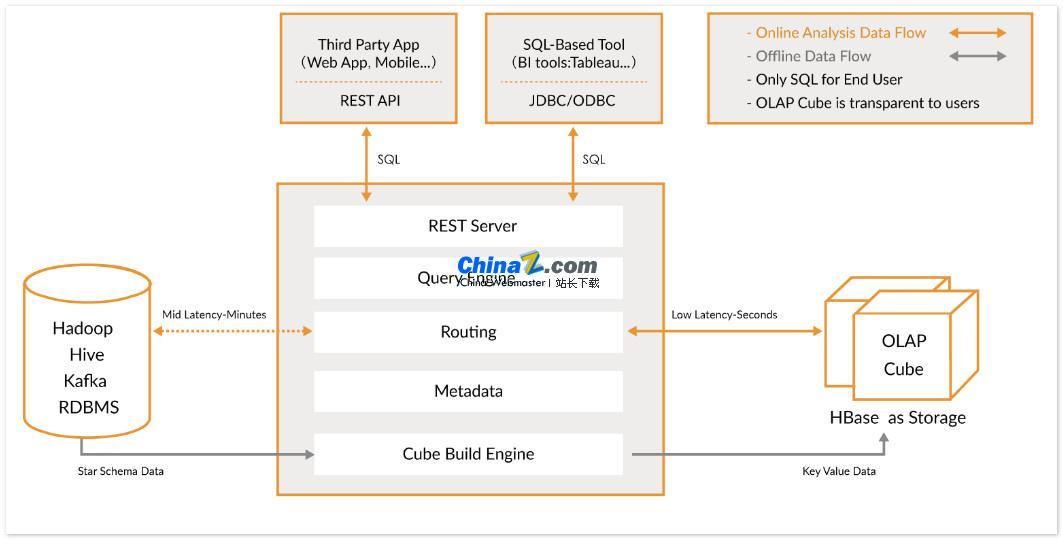
Apache Kylin adalah gudang data analitik terdistribusi dan open source yang menyediakan kemampuan antarmuka kueri SQL dan analisis multidimensi (OLAP) di atas Hadoop/Spark, dan dapat memproses data berskala sangat besar secara efisien. Awalnya dikembangkan oleh eBay dan berkontribusi pada komunitas open source, ia menyelesaikan pertanyaan tentang data besar dalam hitungan sub-detik.
Tiga langkah utama Kylin
Kylin memungkinkan pengguna menerapkan kueri sub-detik pada kumpulan data yang sangat besar hanya dalam tiga langkah:
1. Tentukan model bintang atau kepingan salju pada kumpulan data Anda: Pertama, Anda perlu menentukan model bintang atau kepingan salju untuk mendeskripsikan kumpulan data Anda. Ini akan membantu Kylin memahami hubungan antar data dan dengan demikian mengoptimalkan kinerja kueri.
2. Build Cube: Build Cube pada tabel data yang ditentukan. Cube adalah unit Kylin untuk melakukan prakomputasi dan menyimpan data, yang dapat sangat meningkatkan kecepatan kueri.
3. Gunakan kueri SQL standar: Gunakan sintaks SQL standar untuk menanyakan Cube melalui ODBC, JDBC, atau RESTFUL API.
Kemampuan integrasi Kylin
Kylin terintegrasi dengan berbagai alat visualisasi data, seperti Tableau, Power BI, dll. Pengguna dapat menggunakan alat BI ini untuk menganalisis data Hadoop dan menampilkan wawasan data secara visual.
Meringkaskan
Apache Kylin adalah alat canggih yang dapat membantu pengguna menyelesaikan kueri pada data berskala sangat besar dalam hitungan sub-detik. Kemudahan penggunaan, skalabilitas, dan efisiensinya menjadikannya ideal untuk menangani analisis data skala besar.