RadFact adalah kerangka kerja untuk evaluasi laporan radiologi yang dihasilkan model berdasarkan laporan kebenaran lapangan, dengan atau tanpa landasan . Memanfaatkan kemampuan inferensi logis dari model bahasa besar, RadFact bukanlah angka tunggal melainkan serangkaian metrik, yang menangkap aspek presisi dan perolehan pada tingkat teks saja dan teks dan landasan.
RadFact diperkenalkan di MAIRA-2: Pembuatan Laporan Radiologi Beralas. Di sini kami menyediakan implementasi metrik sumber terbuka untuk memfasilitasi penggunaan dan pengembangannya.
LLMEngine untuk pemrosesan paralelUntuk menjalankan RadFact, Anda hanya perlu mengkloning repositori ini dan menjalankan perintah berikut:
pip install . Ini akan menginstal paket radfact dan semua dependensinya.
Alternatifnya, kami menyediakan Makefile untuk menyiapkan lingkungan conda dengan semua dependensinya. Anda dapat menciptakan lingkungan dengan:
make miniconda
make mamba
make env
conda activate radfact Langkah pertama menginstal miniconda, langkah kedua menginstal mamba untuk resolusi ketergantungan yang cepat, dan langkah ketiga membuat lingkungan conda yang disebut radfact dengan semua dependensinya. Ini juga akan menginstal paket radfact dalam mode yang dapat diedit secara default melalui resep setup_packages_with_deps (lihat Makefile). Terakhir, aktifkan lingkungan untuk menjalankan RadFact. Ini sangat disarankan jika Anda berniat berkontribusi pada proyek ini.
Untuk menggunakan RadFact, Anda memerlukan akses ke model bahasa yang besar. Anda harus menyiapkan titik akhir terlebih dahulu dengan autentikasi, lalu mengonfirmasi bahwa titik akhir tersebut berfungsi seperti yang diharapkan menggunakan skrip pengujian kami.
LLM harus tersedia sebagai titik akhir API dan didukung oleh langchain (versi 0.1.4). Kami mendukung dua jenis model: model AzureChatOpenAI dan ChatOpenAI. Yang pertama cocok untuk model GPT yang tersedia di Azure, sedangkan yang kedua cocok untuk model yang diterapkan secara khusus seperti Llama-3 di Azure.
Kami mendukung metode otentikasi berikut:
API_KEY ke kunci API titik akhir. Kami menggunakan API_KEY sebagai nama variabel lingkungan default. Jika Anda menggunakan nama yang berbeda, Anda dapat menentukannya di konfigurasi titik akhir melalui api_key_env_var_name . Hal ini sangat berguna ketika menggunakan beberapa titik akhir dengan kunci API yang berbeda.config.json di direktori akar proyek. Konfigurasi ini harus memiliki kunci subscription_id , resource_group , dan workspace_name . Itu dapat diunduh dari ruang kerja AzureML melalui portal. File ini ditambahkan ke .gitignore untuk menghindari komitmen yang tidak disengaja. Pastikan untuk menyimpan file di direktori root proyek dengan nama config.json seperti yang diharapkan oleh kelas titik akhir.key_vault_secret_name di konfigurasi titik akhir.azure_ad_token_provider model AzureChatOpenAI yang memungkinkan penyegaran token otomatis. Ini hanya didukung untuk model AzureChatOpenAI . Untuk mempelajari lebih lanjut tentang cara kami mengintegrasikan enpoint dalam RadFact, silakan merujuk ke kelas LLMAPIArguments di argument.py yang menggunakan objek titik akhir dari kelas Endpoint di endpoint.py.
Kami menggunakan hydra untuk manajemen konfigurasi. Konfigurasi titik akhir ada di jalur: configs/endpoints .
Ini adalah contoh file konfigurasi:
ENDPOINT_EXAMPLE : type : " CHAT_OPENAI " url : "" deployment_name : " llama3-70b " api_key_env_var_name : "" keyvault_secret_name : "" speed_factor : 1.0 num_parallel_processes : 10
type: "CHAT_OPENAI" dan type: "AZURE_CHAT_OPENAI" bergantung pada model end-point yang digunakan. Untuk model GPT yang tersedia di Azure, gunakan type: "AZURE_CHAT_OPENAI" . Untuk model yang disebarkan khusus seperti Llama-3 di Azure, gunakan type: "CHAT_OPENAI" .url dan kemungkinan bidang deployment_name dengan nilai yang sesuai.keyvault_secret_name bersifat opsional dan tidak diperlukan jika Anda mengatur api melalui variabel lingkungan. Perbarui api_key_env_var_name jika Anda menggunakan nama variabel lingkungan yang berbeda untuk kunci API dari default "API_KEY" . Saat menggunakan beberapa titik akhir, tentukan api_key_env_var_name yang berbeda untuk setiap titik akhir.speed_factor digunakan ketika lebih dari satu titik akhir tersedia. Hal ini memungkinkan Anda menentukan kecepatan relatif titik akhir dibandingkan dengan titik lain yang digunakan untuk membagi data di seluruh titik akhir secara proporsional.num_parallel_processes digunakan untuk menentukan jumlah proses paralel yang akan digunakan saat menanyakan titik akhir tertentu. Semua permintaan diproses secara berurutan kecuali num_parallel_processes diatur ke nilai lebih besar dari 1 yang memungkinkan pemrosesan paralel. Seperti di atas, ketika menggunakan RadFact untuk evaluasi laporan non-grounded , misalnya naratif, RadFact terlebih dahulu mengubah laporan menjadi daftar frasa. Kami menggunakan LLM untuk langkah ini, namun tidak harus LLM yang sama seperti yang digunakan untuk verifikasi keterlibatan. Anda dapat menentukan titik akhir mana (karenanya LLM) yang digunakan untuk setiap tugas dalam konfigurasi berikut, di bawah override endpoints: :
configs/report_to_phrases.yaml -- konversi laporan menjadi daftar frasa. Di MAIRA-2, kami menggunakan GPT-4 untuk ini yang dapat dikueri sebagai model AzureChatOpenAI.configs/radfact.yaml -- verifikasi persyaratan. Di MAIRA-2, kami menggunakan LLama-3-70B-Instruct untuk ini yang dapat ditanyakan sebagai model ChatOpenAI. LLM back-end yang berbeda mungkin berperilaku berbeda dan menghasilkan hasil metrik yang berbeda. Secara khusus, model yang berkinerja buruk dalam verifikasi persyaratan tidak boleh digunakan untuk RadFact. Untuk mengonfirmasi bahwa verifikasi persyaratan berfungsi seperti yang diharapkan, jalankan python src/radfact/cli/run_radfact_test_examples.py dan konfirmasikan bahwa hasilnya serupa dengan yang diharapkan. Hasil yang diharapkan diperoleh dengan menggunakan model LLama-3-70b-Instruct .
Perhatikan bahwa ini tidak menguji perilaku langkah laporkan ke frasa.
Kelas LLMEngine memungkinkan pemrosesan paralel di beberapa titik akhir. Jika Anda memiliki akses ke beberapa titik akhir dengan throughput berbeda, mesin dapat membagi data ke seluruh titik akhir secara proporsional dengan kecepatannya. Mesin ini juga memungkinkan pemrosesan permintaan secara paralel ke satu titik akhir. Ini digunakan secara default berapa pun jumlah titik akhir. Lihat file konfigurasi titik akhir untuk opsi speed_factor dan num_parallel_processes . Selain itu, mesin menangani pemrosesan batch dan penyimpanan hasil dalam cache perantara. Semua hasil antara disimpan dalam direktori outputs/radfact di bawah folder run id yang ditandai dengan stempel waktu awal, misalnya outputs/radfact/run_20240814_075225 . Struktur foldernya adalah sebagai berikut:
outputs/radfact/run_20240814_075225
├── batch_outputs
│ ├── outputs_0_100.json
| ├── .
| ├── .
| ├── .
│ └── outputs_1000_1100.json
├── progress
│ ├── subset_0_240.csv
| ├── .
| ├── .
| ├── .
│ └── subset_800_1100.csv
├── skipped
│ ├── subset_0_240.csv
| ├── .
| ├── .
| ├── .
│ └── subset_800_1100.csv
├── outputs.json
├── progress.csv
└── skipped.csv
outputs.json berisi hasil akhir untuk semua titik data. progress.csv berisi kemajuan pemrosesan untuk setiap titik akhir. batch_outputs berisi hasil antara per ukuran batch. skipped berisi titik data yang dilewati karena kesalahan.
Anda dapat merujuk ke buku catatan getting_started untuk melihat cara menjalankan RadFact pada data Anda sendiri. Kami sangat menyarankan untuk membaca buku catatan terlebih dahulu untuk memahami alur kerja RadFact dan cara menggunakannya. Kami juga menyediakan skrip untuk menjalankan RadFact pada data Anda. Pastikan Anda telah menyiapkan titik akhir seperti dijelaskan di atas sebelum menjalankan skrip. perintah run_radfact menjalankan skrip python src/radfact/cli/run_radfact.py di bawah tenda. Anda dapat mengganti perilaku default melalui argumen baris perintah yang dijelaskan di bawah dengan menjalankan run_radfact --help . Anda harus menginstal paket secara lokal untuk menjalankan skrip.
$ run_radfact --help
usage: run_radfact [-h] [--radfact_config_name RADFACT_CONFIG_NAME] [--phrases_config_name PHRASES_CONFIG_NAME] --input_path INPUT_PATH [--is_narrative_text] [--output_dir OUTPUT_DIR] [--bootstrap_samples BOOTSTRAP_SAMPLES]
Compute RadFact metric for a set of samples and saves the results to a json file.
options:
-h, --help show this help message and exit
--input_path INPUT_PATH
The path to the csv or json file containing the samples to compute RadFact for. For finding generation samples, the csv file should have columns ' example_id ' ,
' prediction ' , and ' target ' similar to the example in ` examples/findings_generation_examples.csv ` . For grounded reporting samples, provide a json file in the
same format as ` examples/grounded_reporting_examples.json ` .
--is_narrative_text Whether the input samples are narrative text or not. If true, the input samples are expected to be narrative text, otherwise they are expected to be grounded
phrases.
--radfact_config_name RADFACT_CONFIG_NAME
The name of the config file for RadFact processing. We use the default config file but you can provide a custom config. Make sure the config follows the same
structure as ` configs/radfact.yaml ` and is saved in the ` configs ` directory. This is necessary for hydra initialization from the ` configs ` directory.
--phrases_config_name PHRASES_CONFIG_NAME
The name of the config file for reports to phrases conversion. We use the default config file but you can provide a custom config. Make sure the config follows
the same structure as ` configs/report_to_phrases.yaml ` and is saved in the ` configs ` directory. This is necessary for hydra initialization from the ` configs `
directory.
--output_dir OUTPUT_DIR
Path to the directory where the results will be saved as a json file.
--bootstrap_samples BOOTSTRAP_SAMPLES
Number of bootstrap samples to use for computing the confidence intervals. Set to 0 to disable bootstrapping. run_radfact --input_path < path_to_input_file.csv > --is_narrative_text run_radfact --input_path < path_to_input_file.json > Lihat contoh file input di direktori examples untuk format file input yang diharapkan. File masukan harus dalam format file CSV untuk laporan non-grounded temuan_generasi_examples.csv dan file JSON untuk laporan grounded_reporting_examples.json.
Skrip menghitung interval kepercayaan untuk metrik menggunakan bootstrapping. Jumlah sampel bootstrap dapat dikontrol menggunakan argumen --bootstrap_samples . Nilai defaultnya adalah 500. Untuk menonaktifkan bootstrap, setel --bootstrap_samples 0 .
num_llm_failures . Skrip akan mencetak jumlah kueri yang dilewati di akhir proses, dan menyimpannya di directroy skipped di bawah folder run id. Anda juga akan melihat pesan peringatan di log untuk setiap kueri yang gagal. WARNING: No response for example {query_id}. Setting as NOT ENTAILED .
Kami juga menyediakan skrip untuk mengubah laporan menjadi frasa. Ini berguna ketika Anda memiliki laporan naratif dan ingin mengubahnya menjadi daftar frasa untuk evaluasi RadFact. Anda dapat menjalankan langkah ini secara offline dan kemudian menggunakan file keluaran sebagai masukan ke RadFact. Pastikan Anda telah menyiapkan titik akhir seperti dijelaskan di atas sebelum menjalankan skrip. Perintah run_report_to_phrases menjalankan skrip python src/radfact/cli/run_report_to_phrases.py di bawah tenda.
run_report_to_phrases dataset.csv_path= < your_path_to_cxr_reports > Skrip ini dapat dikonfigurasi menggunakan file konfigurasi report_to_phrases.yaml . Anda dapat menentukan file masukan, file keluaran, dan titik akhir yang akan digunakan untuk konversi.

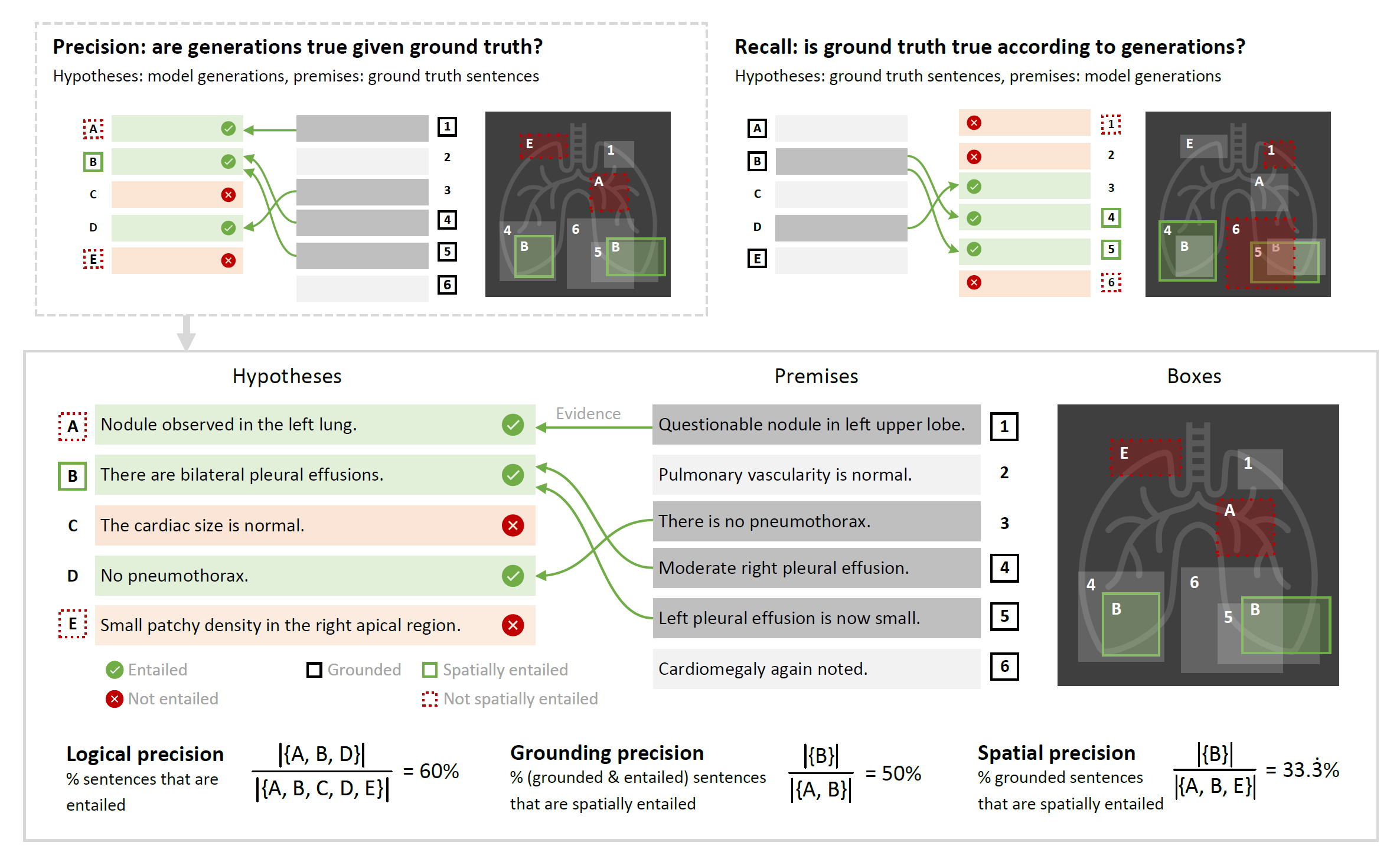
Jika perlu, RadFact pertama-tama memecah laporan menjadi kalimat-kalimat individual yang menggambarkan paling banyak satu temuan. Kemudian menggunakan kemampuan inferensi logis dari model bahasa besar untuk menentukan apakah kalimat-kalimat ini didukung secara logis ('entailed') berdasarkan laporan referensi. Kami menghitungnya dalam dua arah, pertama menggunakan laporan kebenaran dasar (asli) sebagai referensi, dan sebaliknya, menggunakan laporan yang dihasilkan model sebagai referensi. Hal ini memungkinkan dilakukannya kuantifikasi kebenaran dan kelengkapan.
Secara keseluruhan, RadFact menyediakan enam ukuran kualitas laporan (yang membumi):
| Metrik | Definisi | Apa yang disampaikannya kepada kita? | Pembumian? |
|---|---|---|---|
| Presisi logis | Bagian dari kalimat yang dihasilkan yang terkandung dalam laporan kebenaran dasar. | Betapa jujurnya generasi teladan: generasi yang salah akan dihukum. | ❌ |
| Ingatan yang logis | Bagian dari kalimat kebenaran dasar yang terkandung dalam laporan yang dihasilkan. | Seberapa lengkap laporan yang dihasilkan: akan memberikan sanksi jika ada kelalaian. | ❌ |
| Presisi pembumian | Bagian dari kalimat-kalimat yang dihasilkan secara logis dan membumi yang juga memerlukan ruang. | Seberapa sering temuan yang dihasilkan dengan benar juga memiliki dasar yang benar? | ✔️ |
| Penarikan kembali landasan | Bagian dari kalimat-kalimat kebenaran dasar yang membumi secara logis yang juga terkandung secara spasial. | Seberapa sering temuan yang ditangkap dengan benar juga didasarkan pada kebenaran? | ✔️ |
| Presisi spasial | Bagian dari semua kalimat yang dihasilkan berdasarkan logika dan spasial. | Skor yang rendah berarti model telah menghasilkan kotak-kotak yang tidak perlu untuk kalimat yang salah. | ✔️ |
| Penarikan kembali spasial | Bagian dari semua kalimat kebenaran dasar yang terkandung secara logis dan spasial. | Skor yang rendah berarti model gagal membuat kotak untuk temuan dalam referensi, kemungkinan karena mendeskripsikan temuan secara salah atau tidak mendeskripsikan temuan sama sekali. | ✔️ |
Spasial {precision, recall} kurang mudah diinterpretasikan dibandingkan metrik lainnya, namun kami menyertakan metrik tersebut untuk mengontrol penyebut yang tersirat dalam grounding {precision, recall}: Jika kami hanya menilai kualitas kotak kalimat yang mengandung logika yang diukur dengan grounding {precision, recall}, kami tidak menangkap kegagalan landasan yang timbul dari kotak asing yang terkait dengan kalimat yang salah (misalnya temuan yang sepenuhnya dibuat-buat), atau kotak hilang yang terkait dengan temuan yang terlewat.
RadFact menggunakan LLM dalam dua langkah. Dalam kedua kasus tersebut, kami menggunakan sekitar 10 contoh beberapa contoh.
Verifikasi keterlibatan satu arah (bagian dari langkah 2) berfungsi sebagai berikut:
Hal ini memungkinkan kami memberi label pada setiap kalimat sebagai yang diwajibkan secara logis (atau tidak) dan diwajibkan secara spasial (atau tidak), dan karenanya menghitung metrik RadFact yang tercantum di atas. Perhatikan bahwa keterlibatan spasial hanya didefinisikan untuk kalimat dengan kotak.
Untuk mengonversi laporan menjadi kalimat individual, kami membuat contoh sintetik dalam gaya laporan MIMIC-CXR, menggunakan bagian FINDINGS . Laporan MIMIC asli dilindungi berdasarkan perjanjian penggunaan data yang melarang redistribusi. Kami secara manual membagi laporan naratif menjadi kalimat-kalimat tersendiri. Contoh dan pesan sistem dapat dilihat di llm_utils.report_to_phrases.prompts .
Untuk verifikasi persyaratan, beberapa contoh diambil dari kumpulan data pribadi ("USMix"). Setiap contoh berisi kalimat dari dua laporan, yang kami pilih serupa tetapi tidak identik menggunakan statistik tf-idf. Bekerja sama dengan konsultan ahli radiologi, kami kemudian memberi label secara manual dengan status keterlibatan dan bukti. Meskipun merupakan tugas inferensi logis, terdapat tingkat subjektivitas dalam verifikasi keterlibatan, yang timbul dari seberapa ketat konsep-konsep tertentu ditafsirkan. Oleh karena itu, beberapa contoh di atas dapat ditentang. Contoh dan pesan sistem tersedia di llm_utils.nli.prompts .
Untuk mengutip RadFact, Anda dapat menggunakan:
@article { Bannur2024MAIRA2GR ,
title = { MAIRA-2: Grounded Radiology Report Generation } ,
author = { Shruthi Bannur and Kenza Bouzid and Daniel C. Castro and Anton Schwaighofer and Sam Bond-Taylor and Maximilian Ilse and Fernando P'erez-Garc'ia and Valentina Salvatelli and Harshita Sharma and Felix Meissen and Mercy Prasanna Ranjit and Shaury Srivastav and Julia Gong and Fabian Falck and Ozan Oktay and Anja Thieme and Matthew P. Lungren and Maria T. A. Wetscherek and Javier Alvarez-Valle and Stephanie L. Hyland } ,
journal = { arXiv } ,
year = { 2024 } ,
volume = { abs/2406.04449 } ,
url = { https://arxiv.org/abs/2406.04449 }
}RadFact disediakan untuk penggunaan penelitian saja. RadFact tidak dirancang, dimaksudkan, atau disediakan untuk digunakan dalam diagnosis, pencegahan, mitigasi, atau pengobatan suatu penyakit atau kondisi medis atau untuk menjalankan fungsi medis apa pun, dan kinerja RadFact untuk tujuan tersebut belum ditetapkan. Anda bertanggung jawab penuh atas segala penggunaan RadFact, termasuk penggabungan ke dalam produk apa pun yang ditujukan untuk tujuan medis.
Proyek ini menyambut baik kontribusi dan saran. Sebagian besar kontribusi mengharuskan Anda menyetujui Perjanjian Lisensi Kontributor (CLA) yang menyatakan bahwa Anda berhak, dan memang benar, memberi kami hak untuk menggunakan kontribusi Anda. Untuk detailnya, kunjungi https://cla.opensource.microsoft.com.
Saat Anda mengirimkan permintaan tarik, bot CLA akan secara otomatis menentukan apakah Anda perlu memberikan CLA dan menghiasi PR dengan tepat (misalnya, pemeriksaan status, komentar). Cukup ikuti instruksi yang diberikan oleh bot. Anda hanya perlu melakukan ini sekali di seluruh repo menggunakan CLA kami.
Proyek ini telah mengadopsi Kode Etik Sumber Terbuka Microsoft. Untuk informasi lebih lanjut lihat FAQ Pedoman Perilaku atau hubungi [email protected] jika ada pertanyaan atau komentar tambahan.
Proyek ini mungkin berisi merek dagang atau logo untuk proyek, produk, atau layanan. Penggunaan resmi atas merek dagang atau logo Microsoft tunduk dan harus mengikuti Pedoman Merek Dagang & Merek Microsoft. Penggunaan merek dagang atau logo Microsoft dalam versi modifikasi proyek ini tidak boleh menimbulkan kebingungan atau menyiratkan sponsor Microsoft. Segala penggunaan merek dagang atau logo pihak ketiga tunduk pada kebijakan pihak ketiga tersebut.