DeepKE
DeepKE 2.2.7
Bahasa Inggris | 简体中文
Perangkat Ekstraksi Pengetahuan Berbasis Pembelajaran Mendalam
untuk Konstruksi Grafik Pengetahuan
DeepKE adalah perangkat ekstraksi pengetahuan untuk konstruksi grafik pengetahuan yang mendukung skenario cnSchema , sumber daya rendah , tingkat dokumen , dan multimodal untuk ekstraksi entitas , relasi , dan atribut . Kami menyediakan dokumen, demo online, makalah, slide dan poster untuk pemula.
\ di jalur file;wisemodel atau modescape .Jika Anda mengalami masalah apa pun selama instalasi DeepKE dan DeepKE-LLM, silakan periksa Tips atau segera kirimkan masalah, dan kami akan membantu Anda menyelesaikan masalah tersebut!
April, 2024 Kami merilis model ekstraksi informasi berbasis skema bilingual (Mandarin dan Inggris) baru yang disebut OneKE berdasarkan Chinese-Alpaca-2-13B.Feb, 2024 Kami merilis kumpulan data instruksi Ekstraksi Informasi (IE) bilingual (Cina dan Inggris) berkualitas tinggi (token 0,32 miliar) yang diberi nama IEPile, bersama dengan dua model yang dilatih dengan IEPile , baichuan2-13b-iepile-lora dan llama2 -13b-iepil-lora.Sep 2023 kumpulan data instruksi Ekstraksi Informasi (IE) Mandarin dan Inggris bilingual yang disebut InstructIE dirilis untuk Tugas Konstruksi Grafik Pengetahuan berbasis Instruksi (KGC berbasis instruksi), sebagaimana dirinci di sini.June, 2023 Kami memperbarui DeepKE-LLM untuk mendukung ekstraksi pengetahuan dengan KnowLM, ChatGLM, seri LLaMA, seri GPT, dll.Apr, 2023 Kami telah menambahkan model baru, termasuk CP-NER(IJCAI'23), ASP(EMNLP'22), PRGC(ACL'21), PURE(NAACL'21), menyediakan kemampuan ekstraksi peristiwa (Cina dan Inggris), dan menawarkan kompatibilitas dengan paket Python versi lebih tinggi (misalnya, Transformers).Feb, 2023 Kami telah mendukung penggunaan LLM (GPT-3) dengan pembelajaran dalam konteks (berdasarkan EasyInstruct) & pembuatan data, menambahkan model NER W2NER (AAAI'22). Nov, 2022 Tambahkan instruksi anotasi data untuk pengenalan entitas dan ekstraksi relasi, pelabelan otomatis pada data yang diawasi dengan lemah (ekstraksi entitas dan ekstraksi relasi), dan mengoptimalkan pelatihan multi-GPU.
Sept, 2022 Makalah DeepKE: Perangkat Ekstraksi Pengetahuan Berbasis Pembelajaran Mendalam untuk Populasi Basis Pengetahuan telah diterima oleh Jalur Demonstrasi Sistem EMNLP 2022.
Aug, 2022 Kami telah menambahkan dukungan augmentasi data (Bahasa Mandarin, Inggris) untuk ekstraksi relasi sumber daya rendah.
June, 2022 Kami telah menambahkan dukungan multimodal untuk ekstraksi entitas dan relasi.
May, 2022 Kami telah merilis cnschema DeepKE dengan model ekstraksi pengetahuan siap pakai.
Jan, 2022 Kami telah merilis makalah DeepKE: Perangkat Ekstraksi Pengetahuan Berbasis Pembelajaran Mendalam untuk Populasi Basis Pengetahuan
Dec, 2021 Kami telah menambahkan dockerfile untuk membuat lingkungan secara otomatis.
Nov, 2021 Demo DeepKE, yang mendukung ekstrasi real-time tanpa penerapan dan pelatihan, telah dirilis.
Dokumentasi DeepKE yang berisi detail DeepKE seperti kode sumber dan kumpulan data telah dirilis.
Oct, 2021 pip install deepke
Kode deepke-v2.0 telah dirilis.
Aug, 2019 Kode deepke-v1.0 telah dirilis.
Aug, 2018 Startup proyek DeepKE dan kode deepke-v0.1 telah dirilis.
Ada demonstrasi prediksi. File GIF dibuat oleh Terminalizer. Dapatkan kodenya. 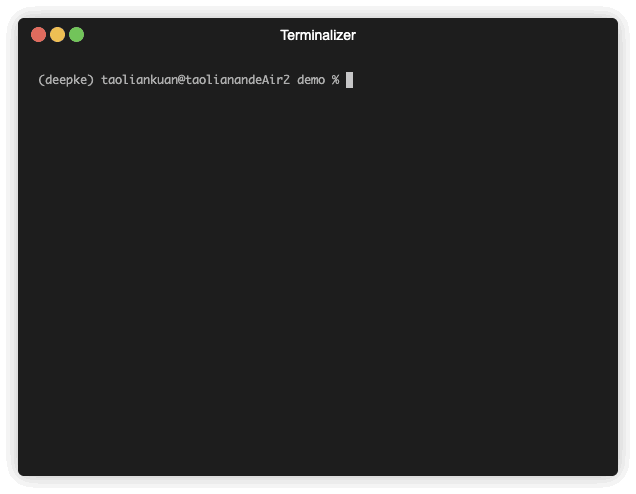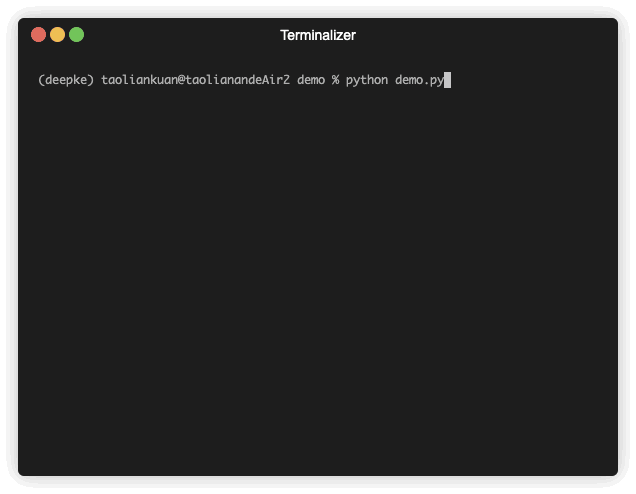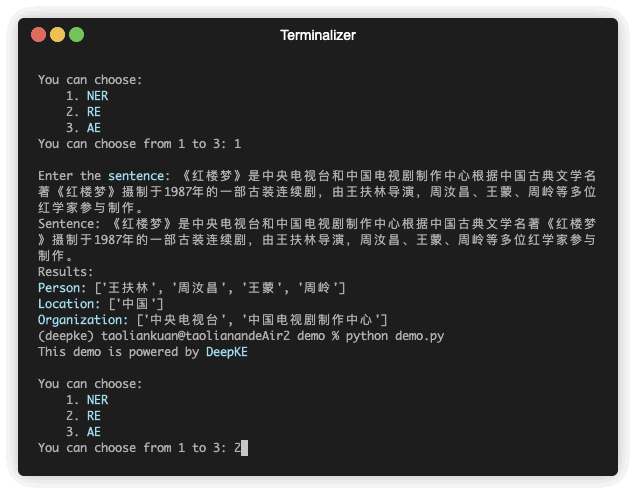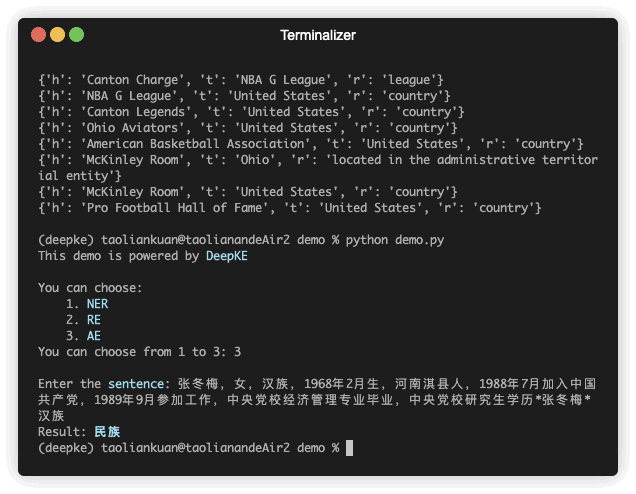
Di era model besar, DeepKE-LLM memanfaatkan ketergantungan lingkungan yang benar-benar baru.
conda create -n deepke-llm python=3.9
conda activate deepke-llm
cd example/llm
pip install -r requirements.txt
Harap dicatat bahwa file requirements.txt terletak di folder example/llm .
pip install deepke .Langkah 1 Unduh kode dasar
git clone --depth 1 https://github.com/zjunlp/DeepKE.git Langkah 2 Buat lingkungan virtual menggunakan Anaconda dan masuk ke dalamnya.
conda create -n deepke python=3.8
conda activate deepkeInstal DeepKE dengan kode sumber
pip install -r requirements.txt
python setup.py install
python setup.py develop Instal DeepKE dengan pip ( TIDAK disarankan! )
pip install deepkeStep3 Masuk ke direktori tugas
cd DeepKE/example/re/standardLangkah 4 Unduh kumpulan data, atau ikuti petunjuk anotasi untuk mendapatkan data
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gzBanyak jenis format data yang didukung, dan detailnya ada di setiap bagian.
Pelatihan Step5 (Parameter untuk pelatihan dapat diubah di folder conf )
Kami mendukung penyetelan parameter visual dengan menggunakan tongkat sihir .
python run.py Step6 Prediksi (Parameter prediksi dapat diubah di folder conf )
Ubah jalur model yang dilatih predict.yaml . Jalur absolut model perlu digunakan, seperti xxx/checkpoints/2019-12-03_ 17-35-30/cnn_ epoch21.pth .
python predict.pyLangkah 1 Instal klien Docker
Instal Docker dan mulai layanan Docker.
Step2 Tarik gambar buruh pelabuhan dan jalankan container
docker pull zjunlp/deepke:latest
docker run -it zjunlp/deepke:latest /bin/bashLangkah selanjutnya sama dengan Langkah 3 dan seterusnya di Konfigurasi Lingkungan Manual .
ular piton == 3.8
Pengenalan entitas bernama berupaya menemukan dan mengklasifikasikan entitas bernama yang disebutkan dalam teks tidak terstruktur ke dalam kategori yang telah ditentukan sebelumnya seperti nama orang, organisasi, lokasi, organisasi, dll.
Data disimpan dalam file .txt . Beberapa contoh sebagai berikut (Pengguna dapat memberi label data berdasarkan alat Doccano, MarkTool, atau mereka dapat menggunakan Pengawasan Lemah dengan DeepKE untuk mendapatkan data secara otomatis):
| Kalimat | Orang | Lokasi | Organisasi |
|---|---|---|---|
| 本报北京9月4日讯记者杨涌报道:部分省区人民日报宣传发行工作座谈会9月3日在4日在京举行。 | itu | 北京 | 人民日报 |
| 《红楼梦》由王扶林导演,周汝昌、王蒙、周岭等多位专家参与制作。 | bisnis, bisnis, bisnis, bisnis | ||
| 姦始皇兵马俑位于陕西省西安市,是世界八大奇迹之一。 | foto | 陕西省,西安市 |
Baca proses detailnya di README tertentu
STANDAR (Diawasi Penuh)
Kami mendukung LLM dan menyediakan model siap pakai, DeepKE-cnSchema-NER, yang akan mengekstraksi entitas di cnSchema tanpa pelatihan.
Langkah 1 Masukkan DeepKE/example/ner/standard . Unduh kumpulan data.
wget 120.27.214.45/Data/ner/standard/data.tar.gz
tar -xzvf data.tar.gz Pelatihan Langkah2
Kumpulan data dan parameter dapat dikustomisasi masing-masing di folder data dan folder conf .
python run.pyPrediksi Langkah3
python predict.pyBEBERAPA TEMBAKAN
Langkah 1 Masukkan DeepKE/example/ner/few-shot . Unduh kumpulan data.
wget 120.27.214.45/Data/ner/few_shot/data.tar.gz
tar -xzvf data.tar.gz Langkah 2 Pelatihan dalam pengaturan sumber daya rendah
Direktori tempat model dimuat dan disimpan serta parameter konfigurasi dapat disesuaikan di folder conf .
python run.py +train=few_shot Pengguna dapat memodifikasi load_path di conf/train/few_shot.yaml untuk menggunakan model yang sudah dimuat.
Langkah 3 Tambahkan - predict ke conf/config.yaml , ubah loda_path sebagai jalur model dan write_path sebagai jalur tempat hasil prediksi disimpan di conf/predict.yaml , lalu jalankan python predict.py
python predict.pyMULTIMODAL
Langkah 1 Masukkan DeepKE/example/ner/multimodal . Unduh kumpulan data.
wget 120.27.214.45/Data/ner/multimodal/data.tar.gz
tar -xzvf data.tar.gzKami menggunakan objek yang terdeteksi RCNN dan objek landasan visual dari gambar asli sebagai informasi lokal visual, di mana RCNN melalui fast_rcnn dan landasan visual melalui onestage_grounding.
Step2 Pelatihan dalam pengaturan multimoda
data dan folder conf .load_path di conf/train.yaml sebagai jalur penyimpanan model yang dilatih terakhir kali. Dan log penyimpanan jalur yang dihasilkan dalam pelatihan dapat dikustomisasi dengan log_dir . python run.pyPrediksi Langkah3
python predict.pyEkstraksi hubungan adalah tugas mengekstraksi hubungan semantik antar entitas dari teks tidak terstruktur.
Data disimpan dalam file .csv . Beberapa contoh sebagai berikut (Pengguna dapat memberi label data berdasarkan alat Doccano, MarkTool, atau mereka dapat menggunakan Pengawasan Lemah dengan DeepKE untuk mendapatkan data secara otomatis):
| Kalimat | Hubungan | Kepala | Head_offset | Ekor | Ekor_offset |
|---|---|---|---|---|---|
| 《岳父也是爹》是王军执导的电视剧,由马恩然、范明主演。 | 导演 | 岳父也是爹 | 1 | 王军 | 8 |
| 《九玄珠》是在纵横中文网连载的一部小说,作者是龙马。 | 连载网站 | 九玄珠 | 1 | 纵横中文网 | 7 |
| 提起杭州的美景,西湖总是第一个映入脑海的词语。 | 所在城市 | 西湖 | 8 | 杭州 | 2 |
!CATATAN: Jika ada beberapa tipe entitas untuk satu relasi, tipe entitas dapat diawali dengan relasi tersebut sebagai input.
Baca proses detailnya di README tertentu
STANDAR (Diawasi Penuh)
Kami mendukung LLM dan menyediakan model siap pakai, DeepKE-cnSchema-RE, yang akan mengekstrak relasi di cnSchema tanpa pelatihan.
Langkah 1 Masuk ke folder DeepKE/example/re/standard . Unduh kumpulan data.
wget 120.27.214.45/Data/re/standard/data.tar.gz
tar -xzvf data.tar.gz Pelatihan Langkah2
Kumpulan data dan parameter dapat dikustomisasi masing-masing di folder data dan folder conf .
python run.pyPrediksi Langkah3
python predict.pyBEBERAPA TEMBAKAN
Langkah 1 Masukkan DeepKE/example/re/few-shot . Unduh kumpulan data.
wget 120.27.214.45/Data/re/few_shot/data.tar.gz
tar -xzvf data.tar.gz Langkah 2 Pelatihan
data dan folder conf .train_from_saved_model di conf/train.yaml sebagai jalur penyimpanan model yang dilatih terakhir kali. Dan log penyimpanan jalur yang dihasilkan dalam pelatihan dapat dikustomisasi dengan log_dir . python run.pyPrediksi Langkah3
python predict.py DOKUMEN
Langkah 1 Masukkan DeepKE/example/re/document . Unduh kumpulan data.
wget 120.27.214.45/Data/re/document/data.tar.gz
tar -xzvf data.tar.gz Pelatihan Langkah2
data dan folder conf .train_from_saved_model di conf/train.yaml sebagai jalur penyimpanan model yang dilatih terakhir kali. Dan log penyimpanan jalur yang dihasilkan dalam pelatihan dapat dikustomisasi dengan log_dir . python run.pyPrediksi Langkah3
python predict.pyMULTIMODAL
Langkah 1 Masukkan DeepKE/example/re/multimodal . Unduh kumpulan data.
wget 120.27.214.45/Data/re/multimodal/data.tar.gz
tar -xzvf data.tar.gzKami menggunakan objek yang terdeteksi RCNN dan objek landasan visual dari gambar asli sebagai informasi lokal visual, di mana RCNN melalui fast_rcnn dan landasan visual melalui onestage_grounding.
Pelatihan Langkah2
data dan folder conf .load_path di conf/train.yaml sebagai jalur penyimpanan model yang dilatih terakhir kali. Dan log penyimpanan jalur yang dihasilkan dalam pelatihan dapat dikustomisasi dengan log_dir . python run.pyPrediksi Langkah3
python predict.pyEkstraksi atribut adalah mengekstraksi atribut entitas dalam teks tidak terstruktur.
Data disimpan dalam file .csv . Beberapa contoh sebagai berikut:
| Kalimat | Att | masuk | Ent_offset | Val | Val_offset |
|---|---|---|---|---|---|
| 张冬梅,女,汉族,1968年2月生,河南淇县人 | 民族 | 张冬梅 | 0 | 汉族 | 6 |
| 诸葛亮,字孔明,三国时期杰出的军事家、文学家、发明家。 | itu | 诸葛亮 | 0 | 三国时期 | 8 |
| 2014年10月1日许鞍华执导的电影《黄金时代》上映 | 上映时间 | 黄金时代 | 19 | 2014年10月1日 | 0 |
Baca proses detailnya di README tertentu
STANDAR (Diawasi Penuh)
Langkah 1 Masuk ke folder DeepKE/example/ae/standard . Unduh kumpulan data.
wget 120.27.214.45/Data/ae/standard/data.tar.gz
tar -xzvf data.tar.gz Pelatihan Langkah2
Kumpulan data dan parameter dapat dikustomisasi masing-masing di folder data dan folder conf .
python run.pyPrediksi Langkah3
python predict.py.tsv , beberapa contohnya adalah sebagai berikut:| Kalimat | Jenis acara | Pemicu | Peran | Argumen | |
|---|---|---|---|---|---|
| 据《欧洲时报》报道,当地时间27日,法国巴黎卢浮宫博物馆员工因不满工作条件恶化而罢工,导致该博物馆也因此闭门谢客一天。 | 组织行为-罢工 | 罢工 | 罢工人员 | 法国巴黎卢浮宫博物馆员工 | |
| tidak | 当地时间27日 | ||||
| 所属组织 | 法国巴黎卢浮宫博物馆 | ||||
| 2019年上半年归母净利润增长17%:收购了少数股东股权 | 财经/交易-出售/收购 | tidak | 出售方 | 少数股东 | |
| 收购方 | 中国外运 | ||||
| 交易物 | itu | ||||
| 美国亚特兰大航展13日发生一起表演机坠机事故,飞行员弹射出舱并安全着陆,事故没有造成人员伤亡。 | 灾害/意外-坠机 | 坠机 | tidak | 13 bulan | |
| 地点 | 美国亚特兰 | ||||
Baca proses detailnya di README tertentu
STANDAR (Diawasi Penuh)
Langkah 1 Masuk ke folder DeepKE/example/ee/standard . Unduh kumpulan data.
wget 120.27.214.45/Data/ee/DuEE.zip
unzip DuEE.zipLangkah 2 Pelatihan
Kumpulan data dan parameter dapat dikustomisasi masing-masing di folder data dan folder conf .
python run.pyLangkah 3 Prediksi
python predict.py 1. Using nearest mirror , KAMIS di Cina, akan mempercepat pemasangan Anaconda ; aliyun di Cina, akan mempercepat pip install XXX .
2.Saat menghadapi ModuleNotFoundError: No module named 'past' , jalankan pip install future .
3. Lambat untuk menginstal model bahasa yang telah dilatih sebelumnya secara online. Merekomendasikan untuk mengunduh model yang telah dilatih sebelumnya sebelum digunakan dan menyimpannya di folder pretrained . Baca README.md di setiap direktori tugas untuk memeriksa persyaratan spesifik untuk menyimpan model yang telah dilatih sebelumnya.
4. DeepKE versi lama ada di cabang deepke-v1.0. Pengguna dapat mengubah cabang untuk menggunakan versi lama. Versi lama telah sepenuhnya ditransfer ke ekstraksi relasi standar (contoh/re/standar).
5.Jika Anda ingin mengubah kode sumber, disarankan untuk menginstal DeepKE dengan kode sumber. Jika tidak maka modifikasi tidak akan berhasil. Lihat masalah
6. Pekerjaan ekstraksi pengetahuan sumber daya rendah yang lebih terkait dapat ditemukan di Ekstraksi Pengetahuan dalam Skenario Sumber Daya Rendah: Survei dan Perspektif.
7.Pastikan versi persyaratan yang tepat di requirements.txt .
Di versi selanjutnya, kami berencana merilis LLM yang lebih kuat untuk KE.
Sementara itu, kami akan menawarkan pemeliharaan jangka panjang untuk memperbaiki bug , menyelesaikan masalah , dan memenuhi permintaan baru . Jadi jika Anda mempunyai masalah, silakan sampaikan masalahnya kepada kami.
Konstruksi Grafik Pengetahuan yang Efisien Data, 高效知识图谱构建 (Tutorial CCKS 2022) [slide]
Konstruksi Grafik Pengetahuan yang Efisien dan Kuat (Tutorial AACL-IJCNLP 2022) [slide]
Keluarga PromptKG: Galeri Pembelajaran Cepat & Karya Penelitian terkait KG, Perangkat, dan Daftar Makalah [Sumber Daya]
Ekstraksi Pengetahuan dalam Skenario Sumber Daya Rendah: Survei dan Perspektif [Survei] [Daftar makalah]
Doccano、MarkTool、LabelStudio: Perangkat Anotasi Data
LambdaKG: Pustaka dan tolok ukur untuk penyematan KG berbasis PLM
EasyInstruct: Kerangka kerja yang mudah digunakan untuk menginstruksikan Model Bahasa Besar
Bahan Bacaan :
Konstruksi Grafik Pengetahuan yang Efisien Data, 高效知识图谱构建 (Tutorial CCKS 2022) [slide]
Konstruksi Grafik Pengetahuan yang Efisien dan Kuat (Tutorial AACL-IJCNLP 2022) [slide]
Keluarga PromptKG: Galeri Pembelajaran Cepat & Karya Penelitian terkait KG, Perangkat, dan Daftar Makalah [Sumber Daya]
Ekstraksi Pengetahuan dalam Skenario Sumber Daya Rendah: Survei dan Perspektif [Survei] [Daftar makalah]
Perangkat Terkait :
Doccano、MarkTool、LabelStudio: Perangkat Anotasi Data
LambdaKG: Pustaka dan tolok ukur untuk penyematan KG berbasis PLM
EasyInstruct: Kerangka kerja yang mudah digunakan untuk menginstruksikan Model Bahasa Besar
Silakan kutip makalah kami jika Anda menggunakan DeepKE dalam pekerjaan Anda
@inproceedings { EMNLP2022_Demo_DeepKE ,
author = { Ningyu Zhang and
Xin Xu and
Liankuan Tao and
Haiyang Yu and
Hongbin Ye and
Shuofei Qiao and
Xin Xie and
Xiang Chen and
Zhoubo Li and
Lei Li } ,
editor = { Wanxiang Che and
Ekaterina Shutova } ,
title = { DeepKE: {A} Deep Learning Based Knowledge Extraction Toolkit for Knowledge Base Population } ,
booktitle = { {EMNLP} (Demos) } ,
pages = { 98--108 } ,
publisher = { Association for Computational Linguistics } ,
year = { 2022 } ,
url = { https://aclanthology.org/2022.emnlp-demos.10 }
}Ningyu Zhang, Haofen Wang, Fei Huang, Feiyu Xiong, Liankuan Tao, Xin Xu, Honghao Gui, Zhenru Zhang, Chuanqi Tan, Qiang Chen, Xiaohan Wang, Zekun Xi, Xinrong Li, Haiyang Yu, Hongbin Ye, Shuofei Qiao, Peng Wang , Yuqi Zhu, Xin Xie, Xiang Chen, Zhoubo Li, Lei Li, Xiaozhuan Liang, Yunzhi Yao, Jing Chen, Yuqi Zhu, Shumin Deng, Wen Zhang, Guozhou Zheng, Huajun Chen
Kontributor Komunitas: thredreams, eltociear, Ziwen Xu, Rui Huang, Xiaolong Weng


