
Xuan Ju 1* , Yiming Gao 1* , Zhaoyang Zhang 1*# , Ziyang Yuan 1 , Xintao Wang 1 , Zeng Sakit, Yu Xiong, Qiang Xu, Ying Shan 1
1 ARC Lab, Tencent PCG 2 Chinese University of Hong Kong * Kontribusi Setara # Pimpinan Proyek
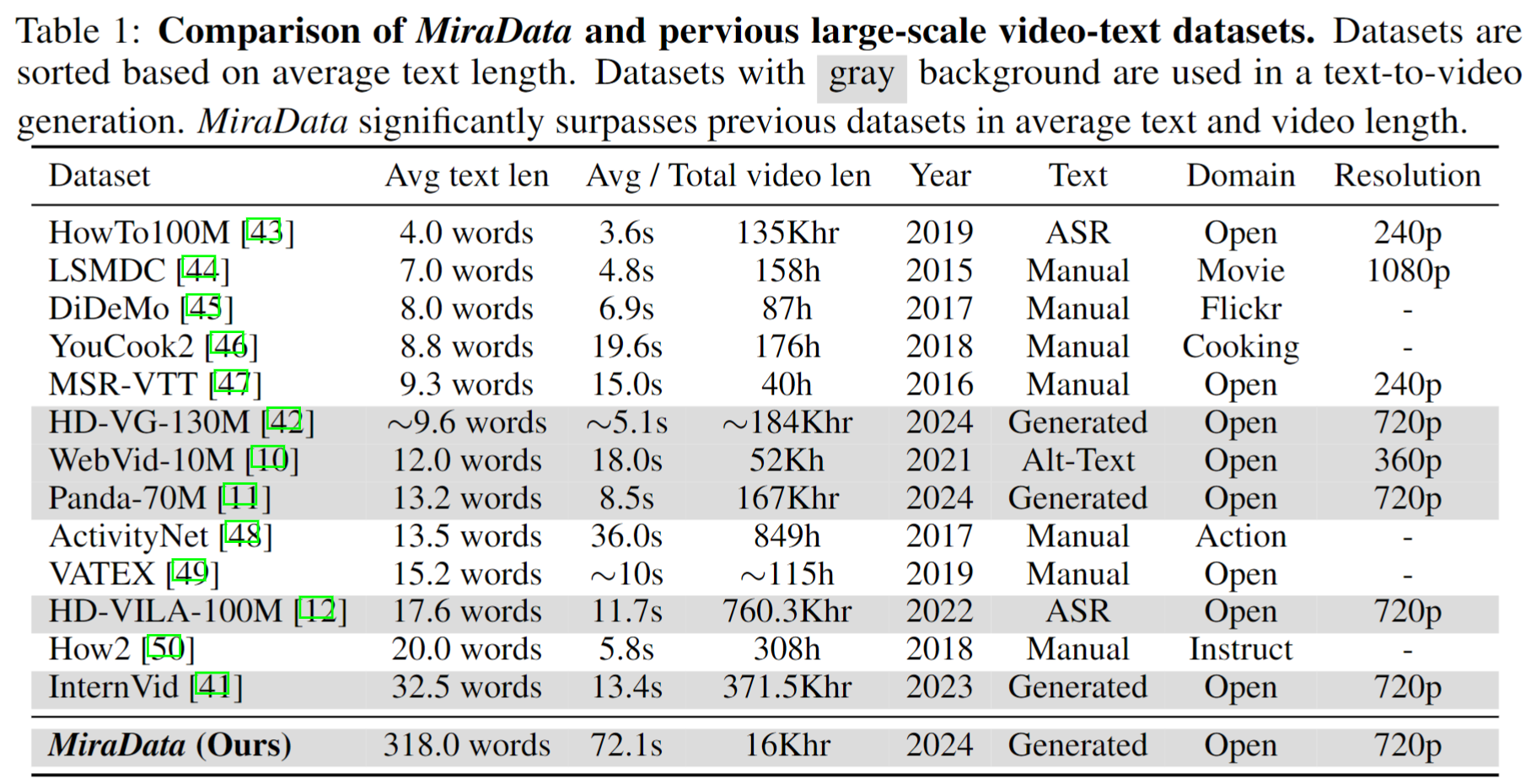
Kumpulan data video memainkan peran penting dalam pembuatan video seperti Sora. Namun, kumpulan data teks-video yang ada sering kali gagal dalam menangani rangkaian video panjang dan menangkap transisi pengambilan gambar . Untuk mengatasi keterbatasan ini, kami memperkenalkan MiraData , kumpulan data video yang dirancang khusus untuk tugas pembuatan video berdurasi panjang. Selain itu, untuk menilai konsistensi temporal dan intensitas gerakan dalam pembuatan video dengan lebih baik, kami memperkenalkan MiraBench , yang menyempurnakan tolok ukur yang ada dengan menambahkan konsistensi 3D dan metrik kekuatan gerakan berbasis pelacakan. Anda dapat menemukan rincian lebih lanjut di makalah penelitian kami.
Kami merilis empat versi MiraData, berisi data 330K, 93K, 42K, 9K.
File meta untuk versi MiraData ini disediakan di Google Drive dan Kumpulan Data HuggingFace. Selain itu, untuk pemahaman yang lebih baik dan lebih cepat tentang komposisi file meta kami, kami secara acak mengambil sampel 100 klip video, yang dapat diakses di sini. File meta berisi informasi indeks berikut:
{download_id}.{clip_id}Untuk mengunduh video dan membaginya menjadi klip, mulailah dengan mengunduh file meta dari Google Drive atau Kumpulan Data HuggingFace. Setelah Anda memiliki file meta, Anda dapat menggunakan skrip berikut untuk mengunduh sampel video:
python download_data.py --meta_csv {meta file} --download_start_id {the start of download id} --download_end_id {the end of download id} --raw_video_save_dir {the path of saving raw videos} --clip_video_save_dir {the path of saving cutted video}
Kami akan menghapus sampel video dari kumpulan data/Github/halaman web proyek kami selama Anda membutuhkannya. Silakan hubungi kami untuk permintaan tersebut.
Untuk mengumpulkan MiraData, pertama-tama kami memilih saluran youtube secara manual dalam berbagai skenario dan menyertakan video dari HD-VILA-100M, Videovo, Pixabay, dan Pexels. Kemudian, semua video di saluran terkait diunduh dan dipisahkan menggunakan PySceneDetect. Kami kemudian menggunakan beberapa model untuk menyatukan klip pendek dan memfilter video berkualitas rendah. Setelah itu, kami memilih klip video dengan durasi panjang. Terakhir, kami memberi caption pada semua klip video menggunakan GPT-4V.

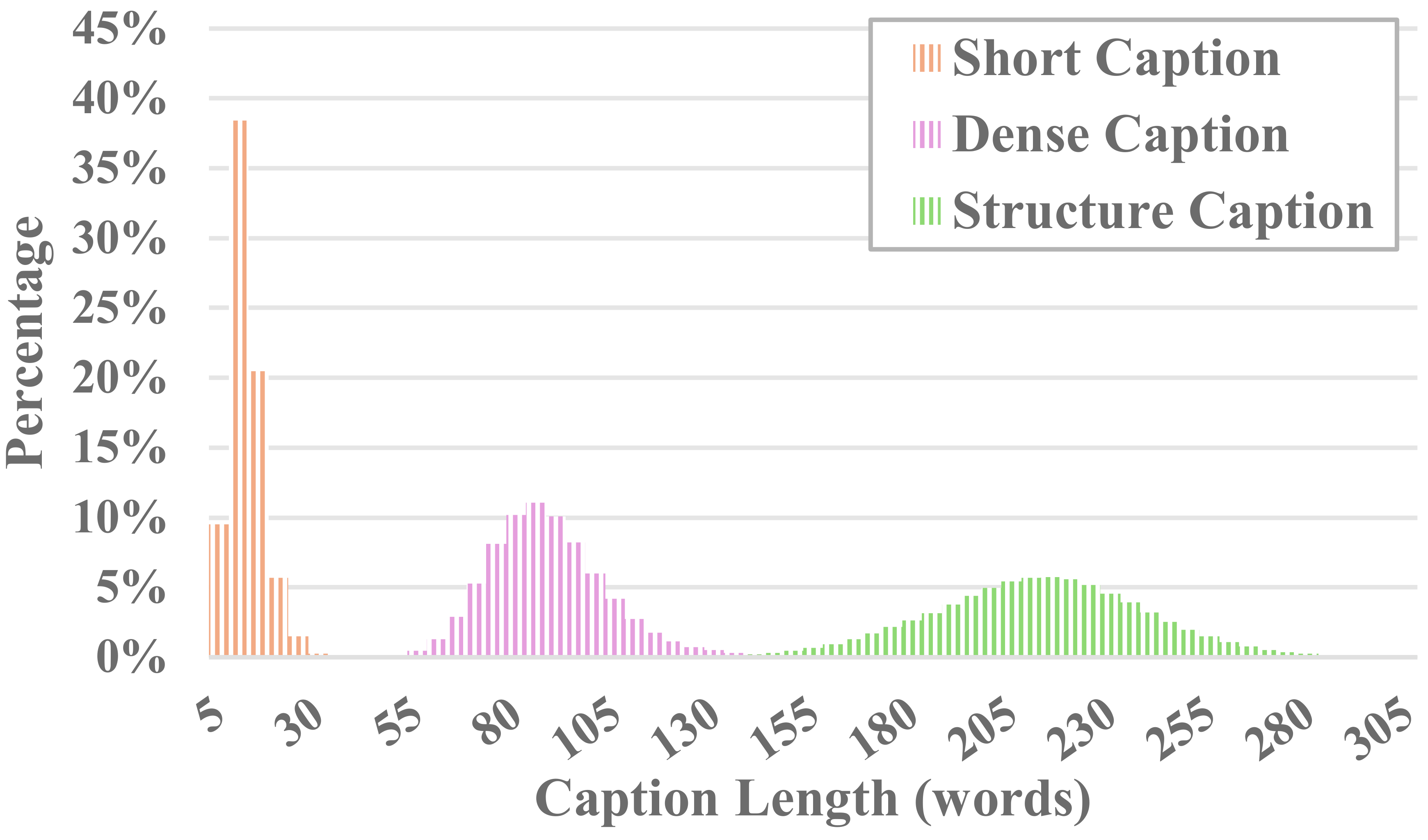
Setiap video di MiraData disertai dengan teks terstruktur. Keterangan ini memberikan deskripsi rinci dari berbagai perspektif, sehingga meningkatkan kekayaan kumpulan data.
Enam Jenis Teks
Kami menguji metode LLM visual sumber terbuka dan GPT-4V yang ada, dan menemukan bahwa teks GPT-4V menunjukkan akurasi dan koherensi yang lebih baik dalam pemahaman semantik dalam hal urutan temporal.
Untuk menyeimbangkan biaya anotasi dan keakuratan teks, kami mengambil sampel 8 bingkai secara seragam untuk setiap video dan menyusunnya ke dalam kotak 2x4 yang berisi satu gambar besar. Kemudian, kami menggunakan model teks Panda-70M untuk memberi anotasi pada setiap video dengan teks satu kalimat, yang berfungsi sebagai petunjuk untuk konten utama, dan memasukkannya ke dalam perintah yang telah kami sesuaikan. Dengan memasukkan perintah yang telah disesuaikan dan gambar besar 2x4 ke GPT-4V, kami dapat secara efisien mengeluarkan teks untuk beberapa dimensi hanya dalam satu putaran percakapan. Konten permintaan spesifik dapat ditemukan di caption_gpt4v.py, dan kami menyambut semua orang untuk berkontribusi pada data teks-video yang lebih berkualitas tinggi. ?

Untuk mengevaluasi pembuatan video berdurasi panjang, kami merancang 17 metrik evaluasi di MiraBench dari 6 perspektif, termasuk konsistensi temporal, kekuatan gerakan temporal, konsistensi 3D, kualitas visual, penyelarasan teks-video, dan konsistensi distribusi. Metrik ini mencakup sebagian besar standar evaluasi umum yang digunakan pada model pembuatan video sebelumnya dan tolok ukur teks-ke-video.
Untuk mengevaluasi video yang dihasilkan, harap siapkan lingkungan python terlebih dahulu melalui:
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
Kemudian, jalankan evaluasi melalui:
python calculate_score.py --meta_file data/evaluation_example/meta_generated.csv --frame_dir data/evaluation_example/frames_generated --gt_meta_file data/evaluation_example/meta_gt.csv --gt_frame_dir data/evaluation_example/frames_gt --output_folder data/evaluation_example/results --ckpt_path data/ckpt --device cuda
Anda dapat mengikuti contoh di data/evaluation_example untuk mengevaluasi video yang Anda buat sendiri.
Silakan lihat LISENSI.
Jika Anda merasa proyek ini berguna untuk penelitian Anda, silakan kutip makalah kami. ?
@misc{ju2024miradatalargescalevideodataset,
title={MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions},
author={Xuan Ju and Yiming Gao and Zhaoyang Zhang and Ziyang Yuan and Xintao Wang and Ailing Zeng and Yu Xiong and Qiang Xu and Ying Shan},
year={2024},
eprint={2407.06358},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2407.06358},
}
Untuk pertanyaan apa pun, silakan kirim email [email protected] .
MiraData berada di bawah Lisensi GPL-v3 dan didukung untuk penggunaan komersial. Jika Anda memerlukan lisensi komersial untuk MiraData, jangan ragu untuk menghubungi kami.


