storm
v1.0.0 & EMNLP 2024 Paper Accepted!
| Pratinjau penelitian | Kertas BADAI | Makalah Co-STORM | Situs web |
Berita Terbaru
[2024/09] Basis kode Co-STORM kini dirilis dan diintegrasikan ke dalam paket python knowledge-storm v1.0.0. Jalankan pip install knowledge-storm --upgrade untuk memeriksanya.
[2024/09] Kami memperkenalkan STORM kolaboratif (Co-STORM) untuk mendukung kurasi pengetahuan kolaboratif manusia-AI! Makalah Co-STORM telah diterima di konferensi utama EMNLP 2024.
[2024/07] Sekarang Anda dapat menginstal paket kami dengan pip install knowledge-storm !
[2024/07] Kami menambahkan VectorRM untuk mendukung landasan pada dokumen yang disediakan pengguna, melengkapi dukungan mesin pencari yang sudah ada ( YouRM , BingSearch ). (lihat #58)
[2024/07] Kami merilis lampu demo untuk pengembang antarmuka pengguna minimal yang dibangun dengan kerangka streamlit dengan Python, berguna untuk pengembangan lokal dan hosting demo (checkout #54)
[2024/06] Kami akan mempersembahkan STORM di NAACL 2024! Temukan kami di Poster Session 2 pada tanggal 17 Juni atau cek materi presentasi kami.
[2024/05] Kami menambahkan dukungan Pencarian Bing di rm.py. Uji STORM dengan GPT-4o - sekarang kami mengonfigurasi bagian pembuatan artikel di demo kami menggunakan model GPT-4o .
[2024/04] Kami merilis versi basis kode STORM yang telah difaktorkan ulang! Kami mendefinisikan antarmuka untuk pipeline STORM dan mengimplementasikan ulang STORM-wiki (lihat src/storm_wiki ) untuk mendemonstrasikan cara membuat instance pipeline. Kami menyediakan API untuk mendukung penyesuaian model bahasa yang berbeda dan integrasi pengambilan/pencarian.
Meskipun sistem ini tidak dapat menghasilkan artikel siap publikasi yang sering kali memerlukan banyak pengeditan, para editor Wikipedia yang berpengalaman merasakan manfaatnya dalam tahap pra-penulisan.
Lebih dari 70.000 orang telah mencoba pratinjau penelitian langsung kami. Cobalah untuk melihat bagaimana STORM dapat membantu perjalanan eksplorasi pengetahuan Anda dan berikan masukan untuk membantu kami meningkatkan sistem!
STORM membagi pembuatan artikel panjang dengan kutipan menjadi dua langkah:
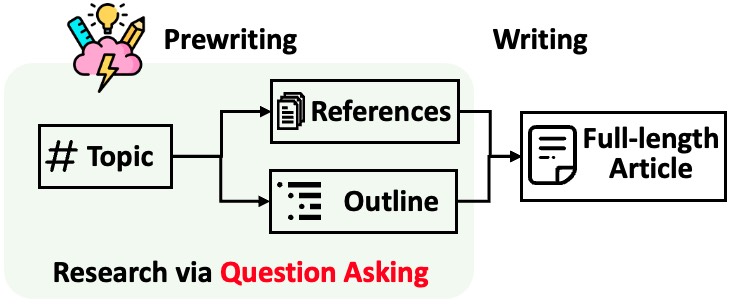
STORM mengidentifikasi inti dari otomatisasi proses penelitian sebagai pertanyaan yang bagus untuk diajukan secara otomatis. Mendorong model bahasa untuk mengajukan pertanyaan secara langsung tidak berhasil dengan baik. Untuk meningkatkan kedalaman dan keluasan pertanyaan, STORM mengadopsi dua strategi:
Co-STORM mengusulkan protokol wacana kolaboratif yang menerapkan kebijakan manajemen giliran untuk mendukung kelancaran kolaborasi antar
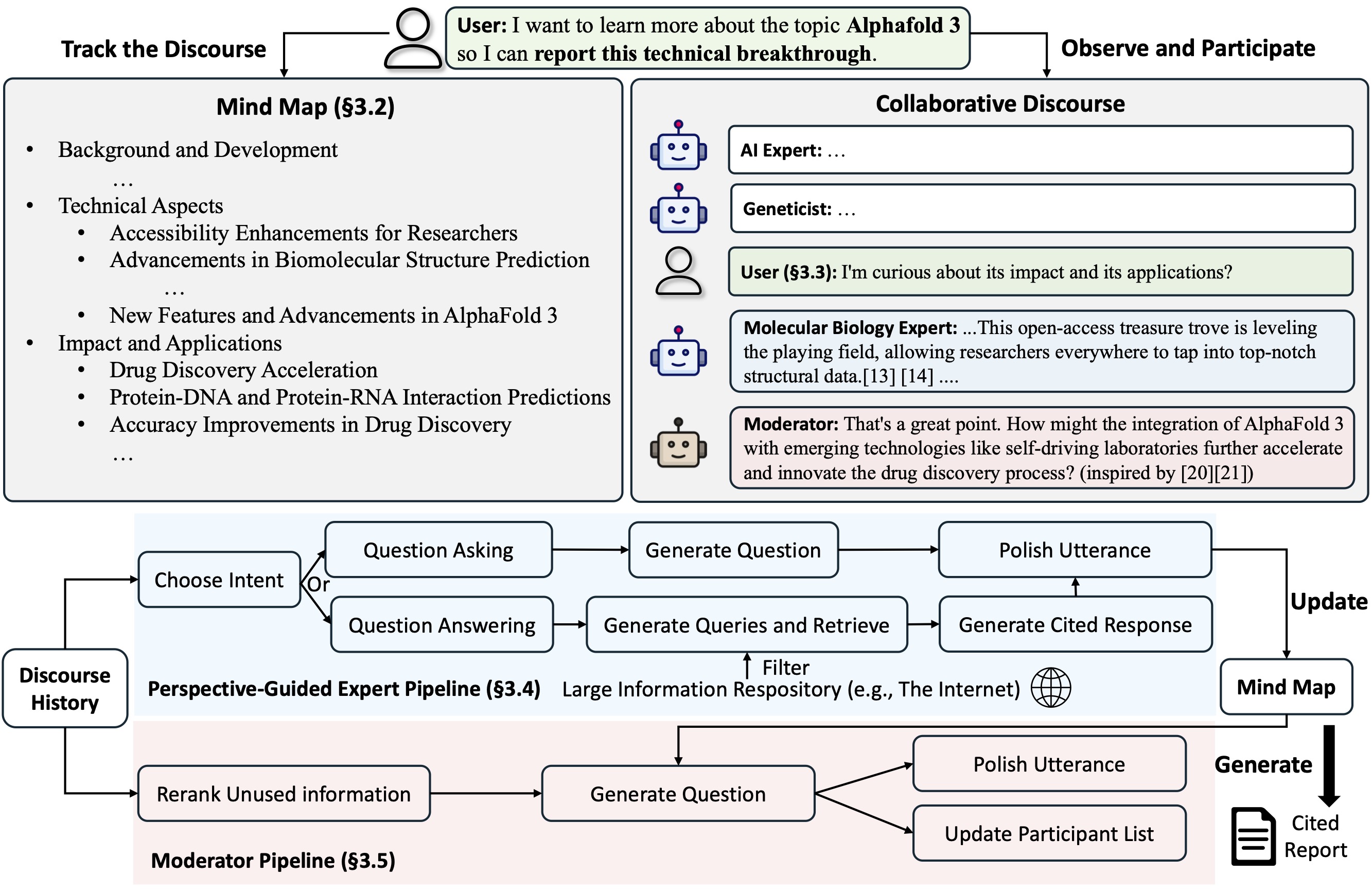
Co-STORM juga memelihara peta pikiran dinamis yang diperbarui, yang mengatur informasi yang dikumpulkan ke dalam struktur konsep hierarki, yang bertujuan untuk membangun ruang konseptual bersama antara pengguna manusia dan sistem . Peta pikiran terbukti membantu mengurangi beban mental ketika wacana berlangsung panjang dan mendalam.
Baik STORM dan Co-STORM diimplementasikan dengan cara yang sangat modular menggunakan dspy.
Untuk menginstal perpustakaan badai pengetahuan, gunakan pip install knowledge-storm .
Anda juga dapat menginstal kode sumber yang memungkinkan Anda mengubah perilaku mesin STORM secara langsung.
Kloning repositori git.
git clone https://github.com/stanford-oval/storm.git
cd stormInstal paket yang diperlukan.
conda create -n storm python=3.11
conda activate storm
pip install -r requirements.txtSaat ini, dukungan paket kami:
OpenAIModel , AzureOpenAIModel , ClaudeModel , VLLMClient , TGIClient , TogetherClient , OllamaClient , GoogleModel , DeepSeekModel , GroqModel sebagai komponen model bahasaYouRM , BingSearch , VectorRM , SerperRM , BraveRM , SearXNG , DuckDuckGoSearchRM , TavilySearchRM , GoogleSearch , dan AzureAISearch sebagai komponen modul pengambilan? PR untuk mengintegrasikan lebih banyak model bahasa ke dalam Knowledge_storm/lm.py dan mesin pencari/retriever ke dalam Knowledge_storm/rm.py sangat dihargai!
Baik STORM dan Co-STORM bekerja di lapisan kurasi informasi, Anda perlu menyiapkan modul pengambilan informasi dan modul model bahasa untuk membuat kelas Runner masing-masing.
Mesin kurasi pengetahuan STORM didefinisikan sebagai kelas Python STORMWikiRunner sederhana. Berikut adalah contoh penggunaan mesin pencari You.com dan model OpenAI.
import os
from knowledge_storm import STORMWikiRunnerArguments , STORMWikiRunner , STORMWikiLMConfigs
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . rm import YouRM
lm_configs = STORMWikiLMConfigs ()
openai_kwargs = {
'api_key' : os . getenv ( "OPENAI_API_KEY" ),
'temperature' : 1.0 ,
'top_p' : 0.9 ,
}
# STORM is a LM system so different components can be powered by different models to reach a good balance between cost and quality.
# For a good practice, choose a cheaper/faster model for `conv_simulator_lm` which is used to split queries, synthesize answers in the conversation.
# Choose a more powerful model for `article_gen_lm` to generate verifiable text with citations.
gpt_35 = OpenAIModel ( model = 'gpt-3.5-turbo' , max_tokens = 500 , ** openai_kwargs )
gpt_4 = OpenAIModel ( model = 'gpt-4o' , max_tokens = 3000 , ** openai_kwargs )
lm_configs . set_conv_simulator_lm ( gpt_35 )
lm_configs . set_question_asker_lm ( gpt_35 )
lm_configs . set_outline_gen_lm ( gpt_4 )
lm_configs . set_article_gen_lm ( gpt_4 )
lm_configs . set_article_polish_lm ( gpt_4 )
# Check out the STORMWikiRunnerArguments class for more configurations.
engine_args = STORMWikiRunnerArguments (...)
rm = YouRM ( ydc_api_key = os . getenv ( 'YDC_API_KEY' ), k = engine_args . search_top_k )
runner = STORMWikiRunner ( engine_args , lm_configs , rm ) Contoh STORMWikiRunner dapat dibangkitkan dengan metode run sederhana:
topic = input ( 'Topic: ' )
runner . run (
topic = topic ,
do_research = True ,
do_generate_outline = True ,
do_generate_article = True ,
do_polish_article = True ,
)
runner . post_run ()
runner . summary ()do_research : jika Benar, simulasikan percakapan dengan perspektif berbeda untuk mengumpulkan informasi tentang topik; jika tidak, muat hasilnya.do_generate_outline : jika Benar, buatlah garis besar topik; jika tidak, muat hasilnya.do_generate_article : jika Benar, buat artikel untuk topik tersebut berdasarkan garis besar dan informasi yang dikumpulkan; jika tidak, muat hasilnya.do_polish_article : jika Benar, sempurnakan artikel dengan menambahkan bagian ringkasan dan (opsional) menghapus konten duplikat; jika tidak, muat hasilnya. Mesin kurasi pengetahuan Co-STORM didefinisikan sebagai kelas Python CoStormRunner sederhana. Berikut adalah contoh penggunaan mesin pencari Bing dan model OpenAI.
from knowledge_storm . collaborative_storm . engine import CollaborativeStormLMConfigs , RunnerArgument , CoStormRunner
from knowledge_storm . lm import OpenAIModel
from knowledge_storm . logging_wrapper import LoggingWrapper
from knowledge_storm . rm import BingSearch
# Co-STORM adopts the same multi LM system paradigm as STORM
lm_config : CollaborativeStormLMConfigs = CollaborativeStormLMConfigs ()
openai_kwargs = {
"api_key" : os . getenv ( "OPENAI_API_KEY" ),
"api_provider" : "openai" ,
"temperature" : 1.0 ,
"top_p" : 0.9 ,
"api_base" : None ,
}
question_answering_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
discourse_manage_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
utterance_polishing_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 2000 , ** openai_kwargs )
warmstart_outline_gen_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 500 , ** openai_kwargs )
question_asking_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 300 , ** openai_kwargs )
knowledge_base_lm = OpenAIModel ( model = gpt_4o_model_name , max_tokens = 1000 , ** openai_kwargs )
lm_config . set_question_answering_lm ( question_answering_lm )
lm_config . set_discourse_manage_lm ( discourse_manage_lm )
lm_config . set_utterance_polishing_lm ( utterance_polishing_lm )
lm_config . set_warmstart_outline_gen_lm ( warmstart_outline_gen_lm )
lm_config . set_question_asking_lm ( question_asking_lm )
lm_config . set_knowledge_base_lm ( knowledge_base_lm )
# Check out the Co-STORM's RunnerArguments class for more configurations.
topic = input ( 'Topic: ' )
runner_argument = RunnerArgument ( topic = topic , ...)
logging_wrapper = LoggingWrapper ( lm_config )
bing_rm = BingSearch ( bing_search_api_key = os . environ . get ( "BING_SEARCH_API_KEY" ),
k = runner_argument . retrieve_top_k )
costorm_runner = CoStormRunner ( lm_config = lm_config ,
runner_argument = runner_argument ,
logging_wrapper = logging_wrapper ,
rm = bing_rm ) Instance CoStormRunner dapat dibangkitkan dengan metodewarmstart warmstart() dan step(...) .
# Warm start the system to build shared conceptual space between Co-STORM and users
costorm_runner . warm_start ()
# Step through the collaborative discourse
# Run either of the code snippets below in any order, as many times as you'd like
# To observe the conversation:
conv_turn = costorm_runner . step ()
# To inject your utterance to actively steer the conversation:
costorm_runner . step ( user_utterance = "YOUR UTTERANCE HERE" )
# Generate report based on the collaborative discourse
costorm_runner . knowledge_base . reorganize ()
article = costorm_runner . generate_report ()
print ( article )Kami menyediakan skrip di folder contoh kami sebagai awal cepat untuk menjalankan STORM dan Co-STORM dengan konfigurasi berbeda.
Kami menyarankan penggunaan secrets.toml untuk menyiapkan kunci API. Buat file secrets.toml di bawah direktori root dan tambahkan konten berikut:
# Set up OpenAI API key.
OPENAI_API_KEY= " your_openai_api_key "
# If you are using the API service provided by OpenAI, include the following line:
OPENAI_API_TYPE= " openai "
# If you are using the API service provided by Microsoft Azure, include the following lines:
OPENAI_API_TYPE= " azure "
AZURE_API_BASE= " your_azure_api_base_url "
AZURE_API_VERSION= " your_azure_api_version "
# Set up You.com search API key.
YDC_API_KEY= " your_youcom_api_key " Untuk menjalankan STORM dengan model keluarga gpt dengan konfigurasi default:
Jalankan perintah berikut.
python examples/storm_examples/run_storm_wiki_gpt.py
--output-dir $OUTPUT_DIR
--retriever you
--do-research
--do-generate-outline
--do-generate-article
--do-polish-articleUntuk menjalankan STORM menggunakan model bahasa favorit Anda atau berdasarkan korpus Anda sendiri: Lihat contoh/storm_examples/README.md.
Untuk menjalankan Co-STORM dengan model keluarga gpt dengan konfigurasi default,
BING_SEARCH_API_KEY="xxx" dan ENCODER_API_TYPE="xxx" ke secrets.tomlpython examples/costorm_examples/run_costorm_gpt.py
--output-dir $OUTPUT_DIR
--retriever bingJika Anda telah menginstal kode sumber, Anda dapat menyesuaikan STORM berdasarkan kasus penggunaan Anda sendiri. Mesin STORM terdiri dari 4 modul:
Antarmuka untuk setiap modul ditentukan dalam knowledge_storm/interface.py , sedangkan implementasinya dibuat dalam knowledge_storm/storm_wiki/modules/* . Modul-modul ini dapat disesuaikan sesuai dengan kebutuhan spesifik Anda (misalnya, menghasilkan bagian dalam format poin-poin, bukan paragraf penuh).
Jika Anda telah menginstal kode sumber, Anda dapat menyesuaikan Co-STORM berdasarkan kasus penggunaan Anda sendiri
knowledge_storm/interface.py , sedangkan implementasinya diterapkan dalam knowledge_storm/collaborative_storm/modules/co_storm_agents.py . Kebijakan agen LLM yang berbeda dapat disesuaikan.DiscourseManager di knowledge_storm/collaborative_storm/engine.py . Itu dapat disesuaikan dan ditingkatkan lebih lanjut. Untuk memfasilitasi studi tentang kurasi pengetahuan otomatis dan pencarian informasi yang kompleks, proyek kami merilis kumpulan data berikut:
Kumpulan Data FreshWiki adalah kumpulan 100 artikel Wikipedia berkualitas tinggi yang berfokus pada halaman yang paling banyak diedit dari Februari 2022 hingga September 2023. Lihat Bagian 2.1 di makalah STORM untuk lebih jelasnya.
Anda dapat mendownload dataset dari huggingface secara langsung. Untuk meringankan masalah kontaminasi data, kami mengarsipkan kode sumber untuk alur konstruksi data yang dapat diulangi di masa mendatang.
Untuk mempelajari minat pengguna dalam tugas pencarian informasi kompleks di alam liar, kami menggunakan data yang dikumpulkan dari pratinjau riset web untuk membuat kumpulan data WildSeek. Kami melakukan downsampling data untuk memastikan keragaman topik dan kualitas data. Setiap titik data adalah pasangan yang terdiri dari topik dan tujuan pengguna melakukan pencarian mendalam pada topik tersebut. Untuk lebih jelasnya, silakan lihat Bagian 2.2 dan Lampiran A makalah Co-STORM.
Kumpulan data WildSeek tersedia di sini.
Untuk eksperimen kertas STORM, silakan beralih ke cabang NAACL-2024-code-backup di sini.
Untuk eksperimen kertas Co-STORM, silakan beralih ke EMNLP-2024-code-backup cabang (placeholder untuk saat ini, akan segera diperbarui).
Tim kami secara aktif mengerjakan:
Jika Anda memiliki pertanyaan atau saran, silakan membuka masalah atau menarik permintaan. Kami menyambut baik kontribusi untuk meningkatkan sistem dan basis kode!
Kontak person: Yijia Shao dan Yucheng Jiang
Kami ingin mengucapkan terima kasih kepada Wikipedia atas konten sumber terbukanya yang luar biasa. Kumpulan data FreshWiki bersumber dari Wikipedia, berlisensi Creative Commons Attribution-ShareAlike (CC BY-SA).
Kami sangat berterima kasih kepada Michelle Lam yang merancang logo untuk proyek ini dan Dekun Ma yang memimpin pengembangan UI.
Silakan kutip makalah kami jika Anda menggunakan kode ini atau sebagian darinya dalam pekerjaan Anda:
@misc { jiang2024unknownunknowns ,
title = { Into the Unknown Unknowns: Engaged Human Learning through Participation in Language Model Agent Conversations } ,
author = { Yucheng Jiang and Yijia Shao and Dekun Ma and Sina J. Semnani and Monica S. Lam } ,
year = { 2024 } ,
eprint = { 2408.15232 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CL } ,
url = { https://arxiv.org/abs/2408.15232 } ,
}
@inproceedings { shao2024assisting ,
title = { {Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models} } ,
author = { Yijia Shao and Yucheng Jiang and Theodore A. Kanell and Peter Xu and Omar Khattab and Monica S. Lam } ,
year = { 2024 } ,
booktitle = { Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) }
}

