bulk
1.0.0
Massal adalah alat pengembang cepat untuk menerapkan beberapa label massal. Mengingat kumpulan data yang telah disiapkan dengan penyematan 2d, ini dapat menghasilkan antarmuka yang memungkinkan Anda dengan cepat menambahkan beberapa anotasi massal, meskipun lebih murah.
python -m pip install --upgrade pip
python -m pip install bulk
Masa depan massal adalah menawarkan widget yang dapat membantu Anda dalam buku catatan. Saat ini, BaseTextExplorer adalah widget utama yang didukung. Mengingat beberapa data yang telah diproses sebelumnya, Anda dapat menggunakan penjelajah untuk melihat-lihat UMAP 2D dari penyematan teks.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
umap = UMAP ()
text_emb_pipeline = make_pipeline (
enc , umap
)
# Load sentences
sentences = list ( pd . read_csv ( "tests/data/text.csv" )[ 'text' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]Untuk menggunakan widget ini, Anda hanya perlu menjalankan ini:
from bulk . widgets import BaseTextExplorer
widget = BaseTextExplorer ( df )
widget . show ()Ini akan memungkinkan kami menjelajahi cluster yang muncul di data kami dengan cepat. Anda dapat menahan kursor mouse untuk masuk ke mode pemilihan dan ketika Anda memilih item, Anda akan melihat subset acak muncul di sebelah kanan. Anda dapat mengambil sampel ulang dari pilihan Anda dengan mengklik tombol sampel ulang.
Saat Anda membuat pilihan, Anda dapat melihat widget di pembaruan yang tepat, namun Anda juga dapat mengambil data dari atribut Python.
widget . selected_idx
widget . selected_texts
widget . selected_dataframeMampu menjelajahi cluster ini memang bagus, tetapi rasanya kita bisa lebih mudah menjelajahi semuanya jika kita memiliki lebih banyak alat yang bisa kita gunakan. Secara khusus, kami ingin memiliki encoder sehingga kami dapat menggunakan kueri di ruang tertanam kami. UI di bawah ini akan memungkinkan kita menjelajah lebih interaktif dengan memperbarui warna dengan perintah teks.
from embetter . text import SentenceEncoder
enc = SentenceEncoder ( 'all-MiniLM-L6-v2' )
# Pay attention here! The rows in df needs to align with the rows in X!
widget = BaseTextExplorer ( df , X = X , encoder = enc )
widget . show ()Berkat alat seperti ipywidget dan anywidget, kami benar-benar dapat mulai membuat beberapa alat agar notebook tetap menjadi tempat yang tepat untuk kebutuhan data Anda. Dengan adanya beberapa widget yang tepat, Anda tidak akan pernah bisa mengungguli notebook Jupyter!
Minat utama proyek ini adalah mengerjakan alat untuk kualitas data. Mampu memilih titik data secara massal sepertinya merupakan awal yang bagus. Mungkin Anda bisa menemukan subset yang menarik untuk diberi anotasi terlebih dahulu, mungkin Anda akan terkejut saat melihat dua cluster berbeda yang seharusnya menjadi satu. Semua hal bagus itu bisa terjadi di buku catatan!
Massal juga dilengkapi dengan aplikasi web kecil yang menggunakan Bokeh untuk memberi Anda antarmuka anotasi berdasarkan representasi penyematan UMAP. Ini menawarkan antarmuka untuk teks. Antarmuka ini adalah antarmuka/fitur asli proyek ini.
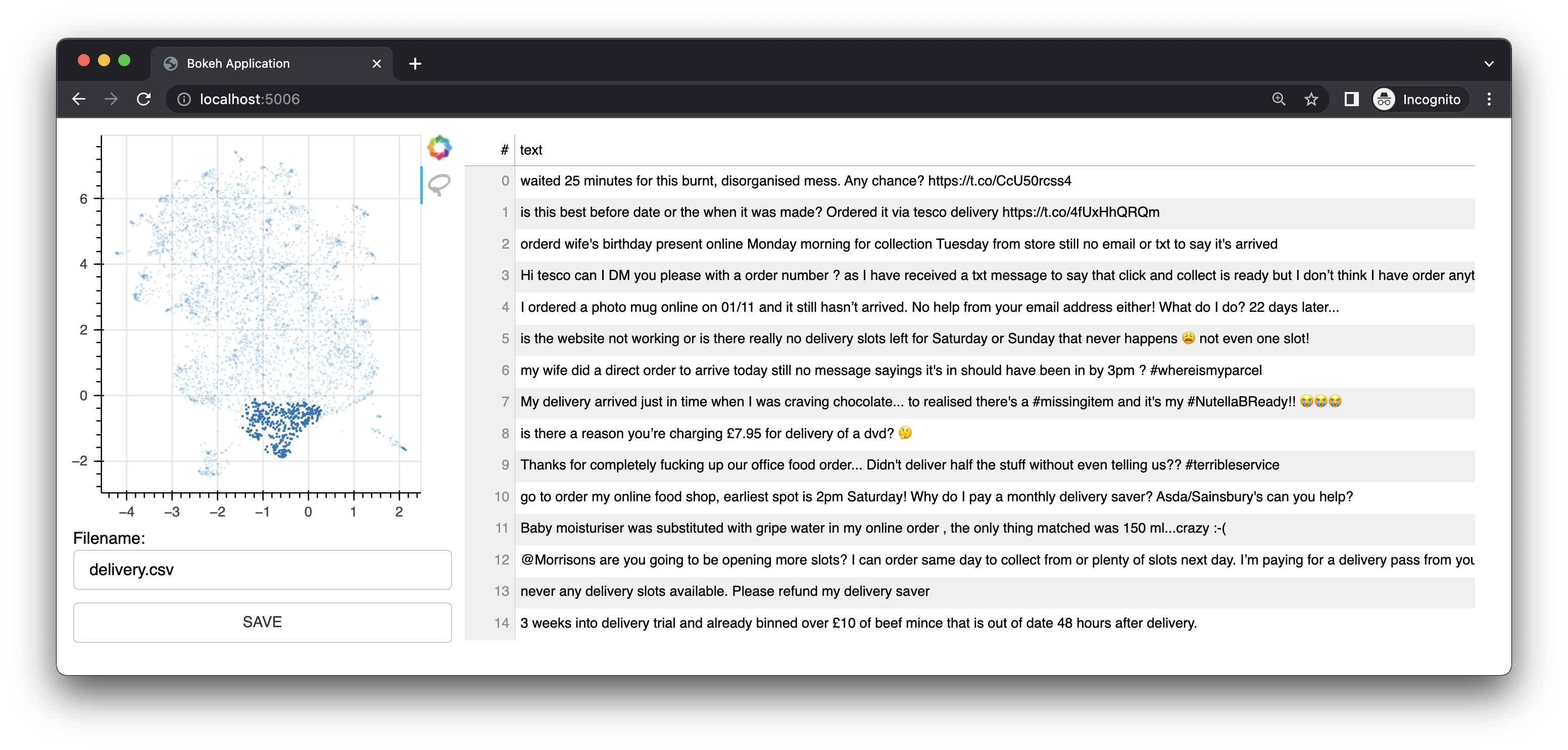
Ia juga dilengkapi antarmuka gambar.
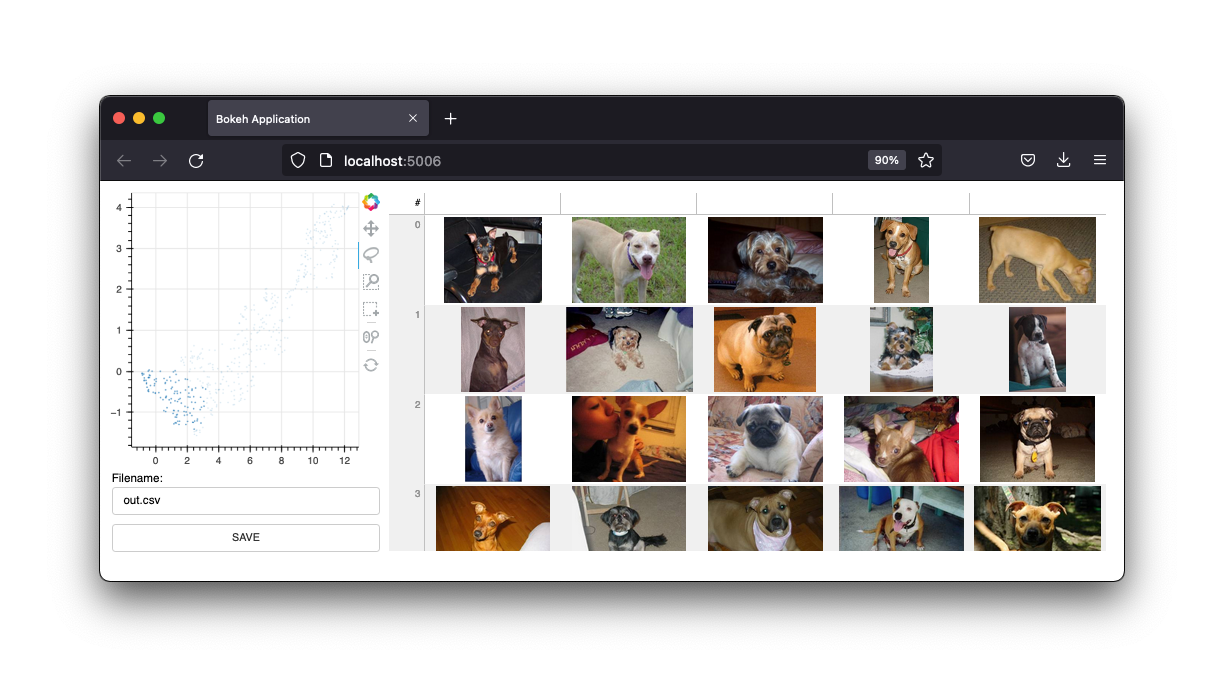
Kami akan mempertahankan antarmuka ini, tetapi masa depan proyek ini adalah widget dari notebook Jupyter. Namun demikian, aplikasi web ini tentu saja masih berguna.
Jika Anda penasaran untuk mempelajari lebih lanjut, Anda mungkin menghargai video ini di YouTube untuk teks dan video ini di YouTube untuk computer vision.
Untuk menggunakan teks secara massal, Anda harus menyiapkan file csv terlebih dahulu.
Catatan
Contoh di bawah ini menggunakan embetter untuk menghasilkan embeddings dan umap untuk mengurangi dimensi. Namun Anda benar-benar bebas menggunakan alat penyematan teks apa pun yang Anda suka. Anda perlu menginstal alat-alat ini secara terpisah. Perhatikan bahwa embetter menggunakan pengubah kalimat di balik terpalnya.
import pandas as pd
from umap import UMAP
from sklearn . pipeline import make_pipeline
# pip install "embetter[text]"
from embetter . text import SentenceEncoder
# Build a sentence encoder pipeline with UMAP at the end.
text_emb_pipeline = make_pipeline (
SentenceEncoder ( 'all-MiniLM-L6-v2' ),
UMAP ()
)
# Load sentences
sentences = list ( pd . read_csv ( "original.csv" )[ 'sentences' ])
# Calculate embeddings
X_tfm = text_emb_pipeline . fit_transform ( sentences )
# Write to disk. Note! Text column must be named "text"
df = pd . DataFrame ({ "text" : sentences })
df [ 'x' ] = X_tfm [:, 0 ]
df [ 'y' ] = X_tfm [:, 1 ]
df . to_csv ( "ready.csv" , index = False ) Anda sekarang dapat menggunakan file ready.csv ini untuk menerapkan beberapa pelabelan massal.
python -m bulk text ready.csv
Jika Anda mencari contoh file untuk dimainkan, Anda dapat mengunduh file demo .csv di repositori ini. Kumpulan data ini berisi subkumpulan kumpulan data yang ditemukan di Kaggle. Anda dapat menemukan yang asli di sini.
Anda juga dapat memberikan kolom tambahan ke file csv Anda yang disebut "warna". Kolom ini kemudian akan digunakan untuk mewarnai titik-titik pada antarmuka.
Anda juga dapat meneruskan --keywords ke aplikasi baris perintah untuk menyorot elemen yang berisi kata kunci tertentu.
python -m bulk text ready.csv --keywords "deliver,card,website,compliment"
Contoh di bawah ini menggunakan pustaka embetter untuk membuat kumpulan data untuk pelabelan gambar secara massal.
Catatan
Contoh di bawah ini menggunakan embetter untuk menghasilkan embeddings dan umap untuk mengurangi dimensi. Namun Anda benar-benar bebas menggunakan alat penyematan teks apa pun yang Anda suka. Anda perlu menginstal alat-alat ini secara terpisah. Perhatikan bahwa embetter menggunakan TIMM di bawah tenda.
import pathlib
import pandas as pd
from sklearn . pipeline import make_pipeline
from umap import UMAP
from sklearn . preprocessing import MinMaxScaler
# pip install "embetter[vision]"
from embetter . grab import ColumnGrabber
from embetter . vision import ImageLoader , TimmEncoder
# Build image encoding pipeline
image_emb_pipeline = make_pipeline (
ColumnGrabber ( "path" ),
ImageLoader ( convert = "RGB" ),
TimmEncoder ( 'xception' ),
UMAP (),
MinMaxScaler ()
)
# Make dataframe with image paths
img_paths = list ( pathlib . Path ( "downloads" , "pets" ). glob ( "*" ))
dataf = pd . DataFrame ({
"path" : [ str ( p ) for p in img_paths ]
})
# Make csv file with Umap'ed model layer
# Note! Bulk assumes the image path column to be called "path"!
X = image_emb_pipeline . fit_transform ( dataf )
dataf [ 'x' ] = X [:, 0 ]
dataf [ 'y' ] = X [:, 1 ]
dataf . to_csv ( "ready.csv" , index = False )Ini menghasilkan file csv yang dapat dimuat secara massal melalui;
python -m bulk image ready.csv
Anda juga dapat membuat sekumpulan thumbnail untuk gambar Anda. Ini bisa berguna jika Anda bekerja dengan kumpulan data yang besar.
python -m bulk util resize ready.csv ready2.csv temp
Ini akan membuat folder bernama temp dengan semua gambar yang diubah ukurannya. Anda kemudian dapat menggunakan folder ini sebagai argumen --thumbnail-path .
python -m bulk image ready2.csv --thumbnail-path temp
Anda juga dapat menggunakan massal untuk mengunduh beberapa kumpulan data untuk dimainkan. Untuk informasi lebih lanjut:
python -m bulk download --help
Antarmukanya mungkin membantu Anda memberi label dengan sangat cepat, namun labelnya sendiri mungkin cukup berisik. Kasus penggunaan yang dimaksudkan untuk alat ini adalah untuk menyiapkan subset yang menarik untuk digunakan nanti di prodi.gy.


