MedCalc Bench
1.0.0
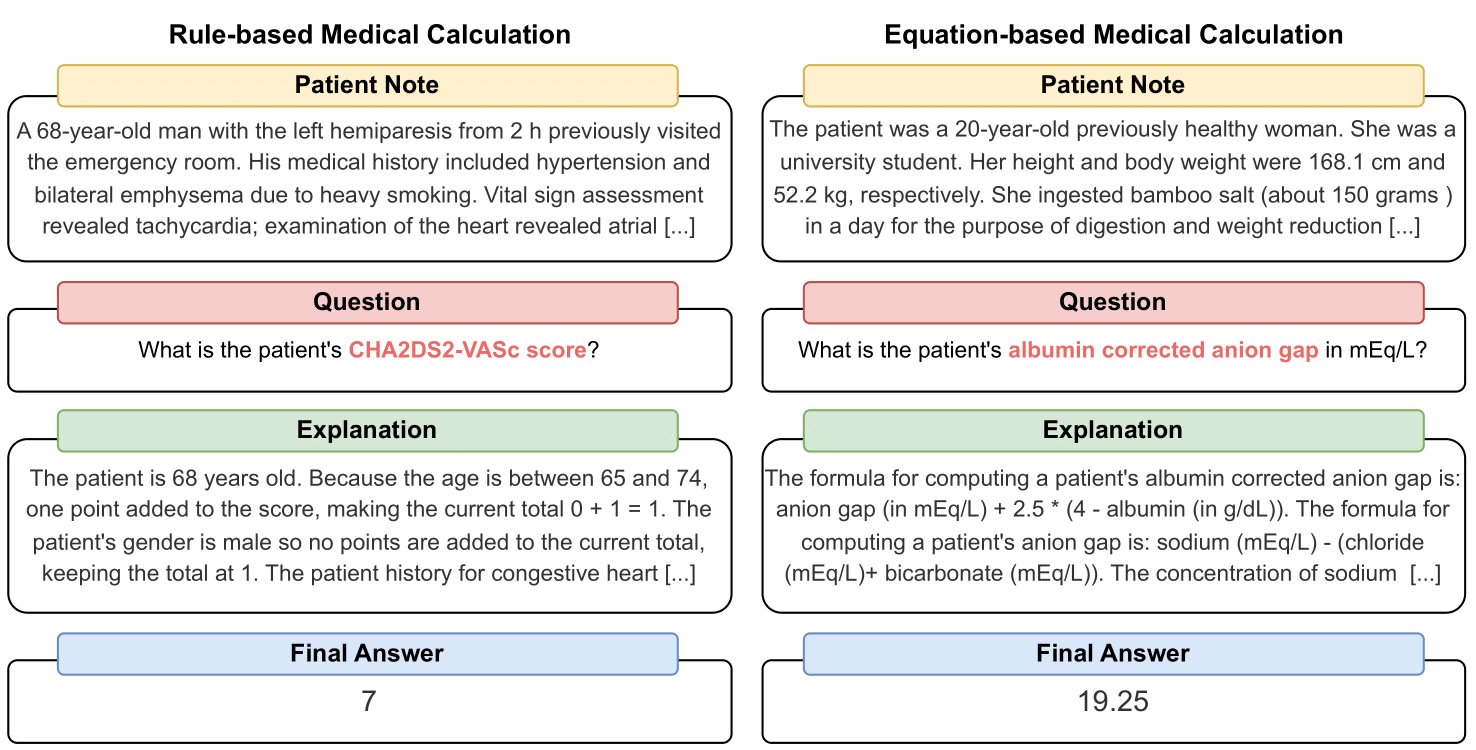
MedCalc-Bench adalah kumpulan data perhitungan medis pertama yang digunakan untuk mengukur kemampuan LLM dalam berfungsi sebagai kalkulator klinis. Setiap contoh dalam kumpulan data terdiri dari catatan pasien, pertanyaan yang meminta untuk menghitung nilai klinis tertentu, nilai jawaban akhir, dan solusi langkah demi langkah yang menjelaskan bagaimana jawaban akhir diperoleh. Kumpulan data kami mencakup 55 tugas penghitungan berbeda yang merupakan penghitungan berbasis aturan atau penghitungan berbasis persamaan. Himpunan data ini berisi himpunan data pelatihan sebanyak 10.053 instans dan himpunan data pengujian sebanyak 1.047 instans.
Secara keseluruhan, kami berharap kumpulan data dan tolok ukur kami berfungsi sebagai seruan untuk meningkatkan keterampilan penalaran komputasi LLM dalam lingkungan medis.
Pracetak kami tersedia di: https://arxiv.org/abs/2406.12036.
Untuk mengunduh CSV kumpulan data evaluasi MedCalc-Bench, silakan unduh file test_data.csv di dalam folder dataset repositori ini. Anda juga dapat mengunduh pemisahan set pengujian dari HuggingFace di https://huggingface.co/datasets/ncbi/MedCalc-Bench.
Selain 1.047 contoh evaluasi, kami juga menyediakan kumpulan data pelatihan sebanyak 10.053 contoh yang dapat digunakan untuk menyempurnakan LLM sumber terbuka (lihat Bagian C pada Lampiran). Data pelatihan dapat ditemukan di file dataset/train_data.csv.zip dan dapat di-unzip untuk mendapatkan train_data.csv . Kumpulan data pelatihan ini juga dapat ditemukan di bagian kereta pada tautan HuggingFace.
Setiap Instance dalam kumpulan data berisi informasi berikut:
Untuk menginstal semua paket yang diperlukan untuk proyek ini, jalankan perintah berikut: conda env create -f environment.yml . Perintah ini akan membuat lingkungan conda medcalc-bench . Untuk menjalankan model OpenAI, Anda perlu menyediakan kunci OpenAI Anda di lingkungan conda ini. Anda dapat melakukan ini dengan menjalankan perintah berikut di lingkungan medcalc-bench : export OPENAI_API_KEY = YOUR_API_KEY , dengan YOUR_API_KEY adalah kunci API OpenAI Anda. Anda juga perlu menyediakan token HuggingFace Anda di lingkungan ini dengan menjalankan perintah berikut: export HUGGINGFACE_TOKEN=your_hugging_face_token , dengan your_hugging_face_token adalah token huggingface Anda.
Untuk mereproduksi Tabel 2 dari makalah, cd terlebih dahulu ke dalam folder evaluation . Kemudian silahkan jalankan perintah berikut: python run.py --model <model_name> and --prompt <prompt_style> .
Opsi untuk --model ada di bawah:
Opsi untuk --prompt ada di bawah:
Dari sini, Anda akan mendapatkan satu file jsonl yang menampilkan status setiap pertanyaan: Setelah menjalankan run.py , hasilnya akan disimpan dalam file bernama <model>_<prompt>.jsonl . File ini dapat ditemukan di folder outputs .
Setiap instance di jsonl akan memiliki metadata berikut yang terkait dengannya:
{
"Row Number": Row index of the item,
"Calculator Name": Name of calculation task,
"Calculator ID": ID of the calculator,
"Category": type of calculation (risk, severity, diagnosis for rule-based calculators and lab, risk, physical, date, dosage for equation-based calculators),
"Note ID": ID of the note taken directly from MedCalc-Bench,
"Patient Note": Paragraph which is the patient note taken directly from MedCalc-Bench,
"Question": Question asking for a specific medical value to be computed,
"LLM Answer": Final Answer Value from LLM,
"LLM Explanation": Step-by-Step explanation by LLM,
"Ground Truth Answer": Ground truth answer value,
"Ground Truth Explanation": Step-by-step ground truth explanation,
"Result": "Correct" or "Incorrect"
}
Selain itu, kami memberikan persentase akurasi rata-rata dan deviasi standar untuk setiap subkategori dalam json berjudul results_<model>_<prompt_style>.json . Akurasi kumulatif dan deviasi standar di antara 1.047 instance dapat ditemukan di bawah kunci "keseluruhan" JSON. File ini dapat ditemukan di folder results .
Selain hasil Tabel 2 di makalah utama, kami juga meminta LLM menulis kode untuk melakukan aritmatika alih-alih meminta LLM melakukannya sendiri. Hasilnya dapat ditemukan di Lampiran D. Karena keterbatasan komputasi, kami hanya menjalankan hasil untuk GPT-3.5 dan GPT-4. Untuk memeriksa petunjuknya dan menjalankannya dalam pengaturan ini, harap periksa file generate_code_prompt.py di folder evaluation .
Untuk menjalankan kode ini, cukup cd ke folder evaluations dan jalankan perintah berikut: python generate_code_prompt.py --gpt <gpt_model> . Opsi untuk <gpt_model> adalah 4 untuk menjalankan GPT-4 atau 35 untuk menjalankan GPT-3.5-turbo-16k. Hasilnya kemudian akan disimpan dalam file jsonl bernama: code_exec_{model_name}.jsonl di folder outputs . Perhatikan bahwa dalam kasus ini, model_name akan menjadi gpt_4 jika Anda memilih untuk menjalankan menggunakan GPT-4. Jika tidak, model_name akan menjadi gpt_35_16k jika Anda memilih untuk menjalankan dengan GPT-3.5-turbo.
Metadata untuk setiap instance dalam file jsonl untuk hasil penafsiran kode adalah info instance yang sama yang disediakan pada bagian di atas. Satu-satunya perbedaan adalah kami menyimpan riwayat obrolan LLM antara pengguna dan asisten dan memiliki kunci "Riwayat Obrolan LLM" dan bukan kunci "Penjelasan LLM". Selain itu, subkategori dan akurasi keseluruhan disimpan dalam file JSON bernama results_<model_name>_code_augmented.json . JSON ini terletak di folder results .
Penelitian ini didukung oleh Program Penelitian Intramural NIH, Perpustakaan Kedokteran Nasional. Selain itu, kontribusi yang dibuat oleh Soren Dunn dilakukan dengan menggunakan komputasi canggih Delta dan sumber daya data yang didukung oleh National Science Foundation (penghargaan OAC tel:2005572) dan Negara Bagian Illinois. Delta adalah upaya bersama dari Universitas Illinois Urbana-Champaign (UIUC) dan Pusat Aplikasi Superkomputer Nasional (NCSA).
Untuk menyusun catatan pasien di MedCalc-Bench, kami hanya menggunakan catatan pasien yang tersedia untuk umum dari artikel laporan kasus yang dipublikasikan di PubMed Central dan sketsa pasien anonim yang dibuat oleh dokter. Dengan demikian, tidak ada informasi kesehatan pribadi yang dapat diidentifikasi yang diungkapkan dalam penelitian ini. Meskipun MedCalc-Bench dirancang untuk mengevaluasi kemampuan perhitungan medis LLM, perlu dicatat bahwa kumpulan data tidak dimaksudkan untuk penggunaan diagnostik langsung atau pengambilan keputusan medis tanpa tinjauan dan pengawasan oleh profesional klinis. Individu tidak boleh mengubah perilaku kesehatan mereka hanya berdasarkan penelitian kami.
Seperti yang dijelaskan di Bagian 1, kalkulator medis biasanya digunakan dalam lingkungan klinis. Dengan pesatnya pertumbuhan minat dalam menggunakan LLM untuk aplikasi khusus domain, praktisi layanan kesehatan mungkin secara langsung meminta chatbot seperti ChatGPT untuk melakukan tugas penghitungan medis. Namun, kemampuan LLM dalam tugas-tugas ini saat ini tidak diketahui. Karena layanan kesehatan adalah domain yang berisiko tinggi dan perhitungan medis yang salah dapat mengakibatkan konsekuensi yang parah, termasuk kesalahan diagnosis, rencana perawatan yang tidak tepat, dan potensi bahaya pada pasien, sangat penting untuk mengevaluasi kinerja LLM dalam perhitungan medis secara menyeluruh. Yang mengejutkan, hasil evaluasi pada kumpulan data MedCalc-Bench kami menunjukkan bahwa semua LLM yang diteliti kesulitan dalam tugas perhitungan medis. Model GPT-4 yang paling mumpuni hanya mencapai akurasi 50% dengan pembelajaran satu kali dan dorongan rantai pemikiran. Dengan demikian, penelitian kami menunjukkan bahwa LLM saat ini belum siap digunakan untuk perhitungan medis. Perlu dicatat bahwa meskipun skor tinggi pada MedCalc-Bench tidak menjamin keunggulan dalam tugas penghitungan medis, kegagalan dalam kumpulan data ini menunjukkan bahwa model tersebut tidak boleh dipertimbangkan untuk tujuan tersebut sama sekali. Dengan kata lain, kami percaya bahwa kelulusan MedCalc-Bench harus menjadi kondisi yang diperlukan (tetapi tidak cukup) agar model dapat digunakan untuk perhitungan medis.
Untuk perubahan apa pun pada kumpulan data ini, (yaitu menambahkan catatan atau kalkulator baru), kami akan memperbarui instruksi README, test_set.csv, dan train_set.csv. Kami masih akan menyimpan versi lama dari kumpulan data ini di archive/ folder. Kami juga akan memperbarui set pelatihan dan pengujian untuk HuggingFace.
Alat ini menunjukkan hasil penelitian yang dilakukan di Cabang Biologi Komputasi, NCBI/NLM. Informasi yang dihasilkan di situs web ini tidak dimaksudkan untuk penggunaan diagnostik langsung atau pengambilan keputusan medis tanpa tinjauan dan pengawasan oleh profesional klinis. Individu tidak boleh mengubah perilaku kesehatan mereka hanya berdasarkan informasi yang dihasilkan di situs ini. NIH tidak memverifikasi secara independen validitas atau kegunaan informasi yang dihasilkan oleh alat ini. Jika Anda memiliki pertanyaan tentang informasi yang dihasilkan di situs web ini, silakan temui ahli kesehatan. Informasi lebih lanjut tentang kebijakan penafian NCBI tersedia.
Bergantung pada kalkulator, kumpulan data kami terdiri dari catatan yang dirancang dari fungsi berbasis templat yang diterapkan dengan Python, ditulis tangan oleh dokter, atau diambil dari kumpulan data kami, Pasien Terbuka.
Open-Patients adalah kumpulan data gabungan dari 180 ribu catatan pasien yang berasal dari tiga sumber berbeda. Kami memiliki otorisasi untuk menggunakan kumpulan data dari ketiga sumber. Sumber pertama adalah soal USMLE dari MedQA yang dirilis di bawah Lisensi MIT. Sumber kedua dari dataset kami adalah Trec Clinical Decision Support dan Trec Clinical Trial yang tersedia untuk didistribusikan kembali karena keduanya merupakan dataset milik pemerintah yang dirilis ke publik. Terakhir, Pasien PMC dirilis di bawah lisensi CC-BY-SA 4.0 sehingga kami memiliki izin untuk memasukkan Pasien PMC ke dalam Pasien Terbuka dan MedCalc-Bench, namun kumpulan data harus dirilis di bawah lisensi yang sama. Oleh karena itu, sumber catatan kami, Open-Patients, dan kumpulan data yang dikurasi darinya, MedCalc-Bench, keduanya dirilis di bawah lisensi CC-BY-SA 4.0.
Berdasarkan pembenaran aturan lisensi, baik Open-Patients dan MedCalc-Bench mematuhi lisensi CC-BY-SA 4.0, namun penulis makalah ini akan memikul semua tanggung jawab jika terjadi pelanggaran hak.
@misc { khandekar2024medcalcbench ,
title = { MedCalc-Bench: Evaluating Large Language Models for Medical Calculations } ,
author = { Nikhil Khandekar and Qiao Jin and Guangzhi Xiong and Soren Dunn and Serina S Applebaum and Zain Anwar and Maame Sarfo-Gyamfi and Conrad W Safranek and Abid A Anwar and Andrew Zhang and Aidan Gilson and Maxwell B Singer and Amisha Dave and Andrew Taylor and Aidong Zhang and Qingyu Chen and Zhiyong Lu } ,
year = { 2024 } ,
eprint = { 2406.12036 } ,
archivePrefix = { arXiv } ,
primaryClass = { id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.' }
}

