MagicMix
1.0.0
Implementasi MagicMix: Pencampuran Semantik dengan makalah Model Difusi.
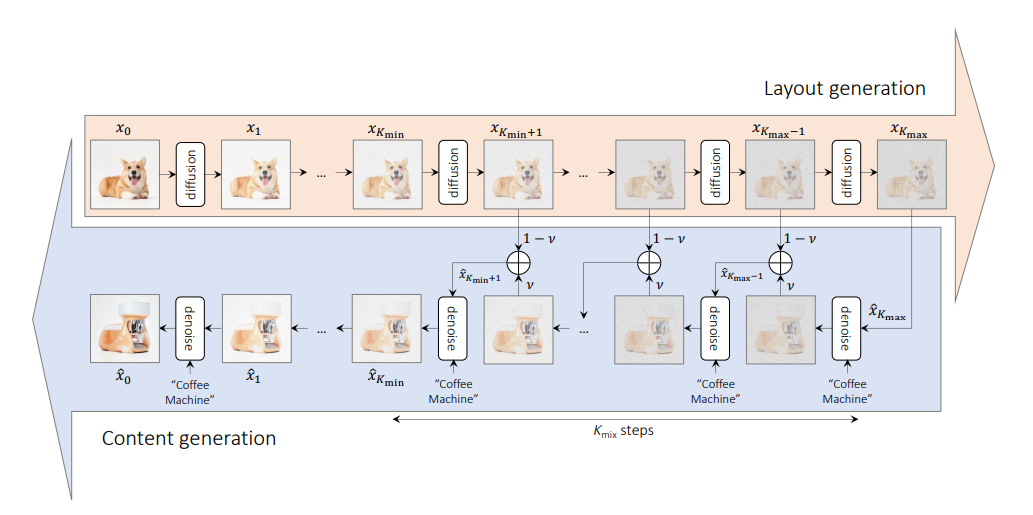
Tujuan dari metode ini adalah untuk menggabungkan dua konsep berbeda secara semantik untuk mensintesis konsep baru dengan tetap menjaga tata ruang dan geometri.
Metode ini mengambil gambar yang menyediakan semantik tata letak dan prompt yang menyediakan semantik konten untuk proses pencampuran.
Ada 3 parameter untuk metode-
v : Ini adalah konstanta interpolasi yang digunakan dalam fase pembuatan tata letak. Semakin besar nilai v maka semakin besar pengaruh prompt terhadap proses pembuatan layout.kmax dan kmin : Ini menentukan rentang tata letak dan proses pembuatan konten. Nilai kmax yang lebih tinggi mengakibatkan hilangnya lebih banyak informasi tentang tata letak gambar asli dan nilai kmin yang lebih tinggi menghasilkan lebih banyak langkah untuk proses pembuatan konten. from PIL import Image
from magic_mix import magic_mix
img = Image . open ( 'phone.jpg' )
out_img = magic_mix ( img , 'bed' , kmax = 0.5 )
out_img . save ( "mix.jpg" ) python3 magic_mix.py
"phone.jpg"
"bed"
"mix.jpg"
--kmin 0.3
--kmax 0.6
--v 0.5
--steps 50
--seed 42
--guidance_scale 7.5
Lihat juga buku catatan demo untuk mengetahui contoh penggunaan implementasi untuk mereproduksi contoh dari makalah.
Anda juga dapat menggunakan saluran komunitas di perpustakaan diffuser.
from diffusers import DiffusionPipeline , DDIMScheduler
from PIL import Image
pipe = DiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
custom_pipeline = "magic_mix" ,
scheduler = DDIMScheduler . from_pretrained ( "CompVis/stable-diffusion-v1-4" , subfolder = "scheduler" ),
). to ( 'cuda' )
img = Image . open ( 'phone.jpg' )
mix_img = pipe (
img ,
prompt = 'bed' ,
kmin = 0.3 ,
kmax = 0.5 ,
mix_factor = 0.5 ,
)
mix_img . save ( 'mix.jpg' )







Saya bukan penulis makalah ini, dan ini bukan implementasi resmi


