gpt neox
GPT-NeoX 2.0
Repositori ini mencatat perpustakaan EleutherAI untuk melatih model bahasa skala besar pada GPU. Kerangka kerja kami saat ini didasarkan pada Model Bahasa Megatron NVIDIA dan telah ditambah dengan teknik dari DeepSpeed serta beberapa optimasi baru. Kami bertujuan menjadikan repo ini sebagai tempat terpusat dan mudah diakses untuk mengumpulkan teknik pelatihan model bahasa autoregresif skala besar, dan mempercepat penelitian dalam pelatihan skala besar. Perpustakaan ini digunakan secara luas di laboratorium akademik, industri, dan pemerintah, termasuk oleh para peneliti di Oak Ridge National Lab, CarperAI, Stability AI, Together.ai, Korea University, Carnegie Mellon University, dan University of Tokyo. Uniknya di antara perpustakaan serupa, GPT-NeoX mendukung beragam sistem dan perangkat keras, termasuk peluncuran melalui Slurm, MPI, dan IBM Job Step Manager, dan telah dijalankan dalam skala besar di AWS, CoreWeave, ORNL Summit, ORNL Frontier, LUMI, dan yang lain.
Jika Anda tidak ingin melatih model dengan miliaran parameter dari awal, kemungkinan besar ini adalah pustaka yang salah untuk digunakan. Untuk kebutuhan inferensi umum, sebaiknya gunakan pustaka transformers Hugging Face yang mendukung model GPT-NeoX.
GPT-NeoX memanfaatkan banyak fitur dan teknologi yang sama dengan perpustakaan Megatron-DeepSpeed yang populer namun dengan kegunaan yang jauh lebih baik dan optimalisasi baru. Fitur utama meliputi:
[9/9/2024] Kami sekarang mendukung pembelajaran preferensi melalui DPO, KTO, dan pemodelan penghargaan
[9/9/2024] Kami sekarang mendukung integrasi dengan Comet ML, platform pemantauan pembelajaran mesin
[21/5/2024] Kami sekarang mendukung RWKV dengan paralelisme pipa!. Lihat PR untuk saluran RWKV dan RWKV+
[21/3/2024] Kini kami mendukung Mixture-of-Experts (MoE)
[17/3/2024] Kami sekarang mendukung GPU AMD MI250X
[15/3/2024] Kami sekarang mendukung Mamba dengan paralelisme tensor! Lihat PRnya
[8/10/2023] Kami sekarang mendukung pos pemeriksaan dengan AWS S3! Aktifkan dengan opsi konfigurasi s3_path (untuk lebih jelasnya lihat PR)
[20/9/2023] Mulai #1035, kami tidak lagi menggunakan Flash Attention 0.x dan 1.x, serta memigrasikan dukungan ke Flash Attention 2.x. Kami tidak yakin hal ini akan menimbulkan masalah, namun jika Anda memiliki kasus penggunaan khusus yang memerlukan dukungan flash lama menggunakan GPT-NeoX terbaru, harap ajukan masalah.
[8/10/2023] Kami memiliki dukungan eksperimental untuk LLaMA 2 dan Flash Attention v2 yang didukung dalam proyek film matematika kami yang akan di-upstream akhir bulan ini.
[17/5/2023] Setelah memperbaiki beberapa bug lain-lain, kami sekarang mendukung penuh bf16.
[4/11/2023] Kami telah meningkatkan implementasi Flash Attention kami agar sekarang mendukung penyematan posisi Alibi.
[3/9/2023] Kami telah merilis GPT-NeoX 2.0.0, versi yang ditingkatkan yang dibangun pada DeepSpeed terbaru yang akan disinkronkan secara berkala di masa mendatang.
Sebelum 9/3/2023, GPT-NeoX mengandalkan DeeperSpeed, yang didasarkan pada DeepSpeed versi lama (0.3.15). Untuk bermigrasi ke versi upstream DeepSpeed terbaru sekaligus memungkinkan pengguna mengakses versi lama GPT-NeoX dan DeeperSpeed, kami telah memperkenalkan dua rilis berversi untuk kedua perpustakaan:
Basis kode ini terutama dikembangkan dan diuji untuk Python 3.8-3.10, dan PyTorch 1.8-2.0. Ini bukan persyaratan yang ketat, dan versi serta kombinasi pustaka lain mungkin berfungsi.
Untuk menginstal dependensi dasar yang tersisa, jalankan:
pip install -r requirements/requirements.txt
pip install -r requirements/requirements-wandb.txt # optional, if logging using WandB
pip install -r requirements/requirements-tensorboard.txt # optional, if logging via tensorboard
pip install -r requirements/requirements-comet.txt # optional, if logging via Cometdari root repositori.
Peringatan
Basis kode kami mengandalkan DeeperSpeed, cabang perpustakaan DeepSpeed kami dengan beberapa perubahan tambahan. Kami sangat menyarankan penggunaan Anaconda, mesin virtual, atau bentuk isolasi lingkungan lainnya sebelum melanjutkan. Kegagalan untuk melakukan hal ini dapat menyebabkan kerusakan pada repositori lain yang mengandalkan DeepSpeed.
Kami sekarang mendukung GPU AMD (MI100, MI250X) melalui kompilasi kernel gabungan JIT. Kernel yang menyatu akan dibuat dan dimuat sesuai kebutuhan. Untuk menghindari menunggu selama peluncuran tugas, Anda juga dapat melakukan hal berikut untuk pra-pembuatan manual:
python
from megatron . fused_kernels import load
load () Ini secara otomatis akan mengadaptasi proses pembangunan pada vendor GPU yang berbeda (AMD, NVIDIA) tanpa perubahan kode spesifik platform. Untuk menguji lebih lanjut kernel yang menyatu menggunakan pytest , gunakan pytest tests/model/test_fused_kernels.py
Untuk menggunakan Flash-Attention, instal dependensi tambahan di ./requirements/requirements-flashattention.txt dan atur jenis perhatian dalam konfigurasi Anda (lihat konfigurasi). Hal ini dapat memberikan peningkatan yang signifikan dibandingkan perhatian rutin pada arsitektur GPU tertentu, termasuk GPU Ampere (seperti A100); lihat repositori untuk lebih jelasnya.
NeoX dan Deep(er)Speed mendukung pelatihan pada beberapa node berbeda dan Anda memiliki opsi untuk menggunakan berbagai peluncur berbeda untuk mengatur pekerjaan multi-node.
Secara umum perlu ada "hostfile" di suatu tempat yang dapat diakses dengan format:
node1_ip slots=8
node2_ip slots=8 dimana kolom pertama berisi alamat IP untuk setiap node dalam pengaturan Anda dan jumlah slot adalah jumlah GPU yang dapat diakses oleh node tersebut. Dalam konfigurasi Anda, Anda harus memasukkan jalur ke file host dengan "hostfile": "/path/to/hostfile" . Alternatifnya, jalur ke file host dapat berada di variabel lingkungan DLTS_HOSTFILE .
pdsh adalah peluncur default, dan jika Anda menggunakan pdsh maka yang harus Anda lakukan (selain memastikan bahwa pdsh diinstal di lingkungan Anda) adalah menyetel {"launcher": "pdsh"} di file konfigurasi Anda.
Jika menggunakan MPI maka Anda harus menentukan perpustakaan MPI (DeepSpeed/GPT-NeoX saat ini mendukung mvapich , openmpi , mpich , dan impi , meskipun openmpi adalah yang paling umum digunakan dan diuji) serta meneruskan tanda deepspeed_mpi di file konfigurasi Anda:
{
"launcher" : " openmpi " ,
"deepspeed_mpi" : true
} Dengan lingkungan Anda yang sudah diatur dengan benar dan file konfigurasi yang benar, Anda dapat menggunakan deepy.py seperti skrip python biasa dan memulai (misalnya) pekerjaan pelatihan dengan:
python3 deepy.py train.py /path/to/configs/my_model.yml
Menggunakan Slurm bisa sedikit lebih terlibat. Seperti halnya MPI, Anda harus menambahkan yang berikut ini ke konfigurasi Anda:
{
"launcher" : " slurm " ,
"deepspeed_slurm" : true
} Jika Anda tidak memiliki akses ssh ke node komputasi di cluster Slurm, Anda perlu menambahkan {"no_ssh_check": true}
Ada banyak kasus dimana opsi peluncuran default di atas tidak cukup
Dalam kasus ini, Anda perlu memodifikasi utilitas pelari multinode DeepSpeed untuk mendukung kasus penggunaan Anda. Secara umum, peningkatan ini terbagi dalam dua kategori:
Dalam hal ini, Anda harus menambahkan kelas pelari multinode baru ke deepspeed/launcher/multinode_runner.py dan mengeksposnya sebagai opsi konfigurasi di GPT-NeoX. Contoh bagaimana kami melakukan ini untuk Summit JSRun masing-masing terdapat dalam penerapan DeeperSpeed dan penerapan GPT-NeoX ini.
Kami telah menemukan banyak kasus di mana kami ingin memodifikasi perintah MPI/Slurm run untuk optimasi atau untuk debug (misalnya untuk memodifikasi pengikatan CPU Slurm srun atau untuk menandai log MPI dengan peringkat). Dalam hal ini, Anda harus memodifikasi perintah run kelas multinode runner di bawah metode get_cmd (misalnya mpirun_cmd untuk OpenMPI). Contoh bagaimana kami melakukan ini untuk menyediakan perintah jalankan yang dioptimalkan dan diberi tag peringkat menggunakan Slurm dan OpenMPI untuk kluster Stabilitas ada di cabang DeeperSpeed ini
Secara umum Anda tidak akan dapat memiliki satu file host tetap, jadi Anda perlu memiliki skrip untuk membuatnya secara dinamis saat pekerjaan Anda dimulai. Contoh skrip untuk menghasilkan file host secara dinamis menggunakan Slurm dan 8 GPU per node adalah:
#! /bin/bash
GPUS_PER_NODE=8
mkdir -p /sample/path/to/hostfiles
# need to add the current slurm jobid to hostfile name so that we don't add to previous hostfile
hostfile=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# be extra sure we aren't appending to a previous hostfile
rm $hostfile & > /dev/null
# loop over the node names
for i in ` scontrol show hostnames $SLURM_NODELIST `
do
# add a line to the hostfile
echo $i slots= $GPUS_PER_NODE >> $hostfile
done $SLURM_JOBID dan $SLURM_NODELIST menjadi variabel lingkungan yang akan dibuat Slurm untuk Anda. Lihat dokumentasi sbatch untuk daftar lengkap variabel lingkungan Slurm yang tersedia yang ditetapkan pada waktu pembuatan pekerjaan.
Kemudian Anda dapat membuat skrip sbatch untuk memulai pekerjaan GPT-NeoX Anda. Skrip sbatch sederhana pada cluster berbasis Slurm dengan 8 GPU per node akan terlihat seperti ini:
#! /bin/bash
# SBATCH --job-name="neox"
# SBATCH --partition=your-partition
# SBATCH --nodes=1
# SBATCH --ntasks-per-node=8
# SBATCH --gres=gpu:8
# Some potentially useful distributed environment variables
export HOSTNAMES= ` scontrol show hostnames " $SLURM_JOB_NODELIST " `
export MASTER_ADDR= $( scontrol show hostnames " $SLURM_JOB_NODELIST " | head -n 1 )
export MASTER_PORT=12802
export COUNT_NODE= ` scontrol show hostnames " $SLURM_JOB_NODELIST " | wc -l `
# Your hostfile creation script from above
./write_hostfile.sh
# Tell DeepSpeed where to find our generated hostfile via DLTS_HOSTFILE
export DLTS_HOSTFILE=/sample/path/to/hostfiles/hosts_ $SLURM_JOBID
# Launch training
python3 deepy.py train.py /sample/path/to/your/configs/my_model.yml
Anda kemudian dapat memulai latihan dengan sbatch my_sbatch_script.sh
Kami juga menyediakan konfigurasi Dockerfile dan docker-compose jika Anda lebih suka menjalankan NeoX dalam sebuah container.
Persyaratan untuk menjalankan container adalah memiliki driver GPU yang sesuai, instalasi Docker terbaru, dan nvidia-container-toolkit diinstal. Untuk menguji apakah instalasi Anda bagus, Anda dapat menggunakan "contoh beban kerja", yaitu:
docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
Asalkan itu akan berjalan, Anda perlu mengekspor NEOX_DATA_PATH dan NEOX_CHECKPOINT_PATH di lingkungan Anda untuk menentukan direktori data dan direktori untuk menyimpan dan memuat pos pemeriksaan:
export NEOX_DATA_PATH=/mnt/sda/data/enwiki8 #or wherever your data is stored on your system
export NEOX_CHECKPOINT_PATH=/mnt/sda/checkpoints
Dan kemudian, dari direktori gpt-neox, Anda dapat membuat image dan menjalankan shell dalam sebuah container dengan
docker compose run gpt-neox bash
Setelah build, Anda seharusnya dapat melakukan ini:
mchorse@537851ed67de:~$ echo $(pwd)
/home/mchorse
mchorse@537851ed67de:~$ ls -al
total 48
drwxr-xr-x 1 mchorse mchorse 4096 Jan 8 05:33 .
drwxr-xr-x 1 root root 4096 Jan 8 04:09 ..
-rw-r--r-- 1 mchorse mchorse 220 Feb 25 2020 .bash_logout
-rw-r--r-- 1 mchorse mchorse 3972 Jan 8 04:09 .bashrc
drwxr-xr-x 4 mchorse mchorse 4096 Jan 8 05:35 .cache
drwx------ 3 mchorse mchorse 4096 Jan 8 05:33 .nv
-rw-r--r-- 1 mchorse mchorse 807 Feb 25 2020 .profile
drwxr-xr-x 2 root root 4096 Jan 8 04:09 .ssh
drwxrwxr-x 8 mchorse mchorse 4096 Jan 8 05:35 chk
drwxrwxrwx 6 root root 4096 Jan 7 17:02 data
drwxr-xr-x 11 mchorse mchorse 4096 Jan 8 03:52 gpt-neox
Untuk pekerjaan jangka panjang, Anda harus menjalankannya
docker compose up -d
untuk menjalankan kontainer dalam mode terpisah, dan kemudian, dalam sesi terminal terpisah, jalankan
docker compose exec gpt-neox bash
Anda kemudian dapat menjalankan pekerjaan apa pun yang Anda inginkan dari dalam wadah.
Kekhawatiran saat berjalan dalam waktu lama atau dalam mode terpisah antara lain
Jika Anda lebih suka menjalankan image container bawaan dari dockerhub, Anda dapat menjalankan perintah docker composer dengan -f docker-compose-dockerhub.yml , misalnya,
docker compose run -f docker-compose-dockerhub.yml gpt-neox bash
Semua fungsionalitas harus diluncurkan menggunakan deepy.py , pembungkus di sekitar peluncur deepspeed .
Saat ini kami menawarkan tiga fungsi utama:
train.py digunakan untuk pelatihan dan penyempurnaan model.eval.py digunakan untuk mengevaluasi model yang dilatih menggunakan memanfaatkan evaluasi model bahasa.generate.py digunakan untuk mengambil sampel teks dari model terlatih.yang dapat diluncurkan dengan:
./deepy.py [script.py] [./path/to/config_1.yml] [./path/to/config_2.yml] ... [./path/to/config_n.yml]Misalnya untuk melancarkan latihan, Anda bisa berlari
./deepy.py train.py ./configs/20B.yml ./configs/local_cluster.ymlUntuk detail selengkapnya tentang setiap titik masuk, lihat masing-masing Pelatihan dan Penyempurnaan, Inferensi, dan Evaluasi.
Parameter GPT-NeoX ditentukan dalam file konfigurasi YAML yang diteruskan ke peluncur deepy.py. Kami telah menyediakan beberapa contoh file .yml dalam konfigurasi, yang menunjukkan beragam fitur dan ukuran model.
File-file ini umumnya lengkap, namun belum optimal. Misalnya, bergantung pada konfigurasi GPU spesifik Anda, Anda mungkin perlu mengubah beberapa pengaturan seperti pipe-parallel-size , model-parallel-size untuk menambah atau mengurangi derajat paralelisasi, train_micro_batch_size_per_gpu atau gradient-accumulation-steps untuk mengubah ukuran batch pengaturan terkait, atau dikt zero_optimization untuk mengubah cara status pengoptimal diparalelkan di seluruh pekerja.
Untuk panduan lebih rinci tentang fitur yang tersedia dan cara mengonfigurasinya, lihat konfigurasi README, dan untuk dokumentasi setiap argumen yang mungkin, lihat configs/neox_arguments.md.
GPT-NeoX mencakup beberapa implementasi ahli untuk MoE. Untuk memilih di antara keduanya, tentukan moe_type of megablocks (default) atau deepspeed .
Keduanya didasarkan pada kerangka paralelisme DeepSpeed MoE, yang mendukung paralelisme data pakar tensor. Keduanya memungkinkan Anda untuk beralih antara token-dropping dan dropless (default, dan untuk itulah Megablock dirancang). Perutean Sinkhorn akan segera hadir!
Untuk contoh konfigurasi dasar lengkap, lihat configs/125M-dmoe.yml (untuk Megablocks dropless) atau configs/125M-moe.yml.
Sebagian besar argumen konfigurasi terkait MoE diawali dengan moe . Beberapa parameter konfigurasi umum dan defaultnya adalah sebagai berikut:
moe_type: megablocks
moe_num_experts: 1 # 1 disables MoE. 8 is a reasonable value.
moe_loss_coeff: 0.1
expert_interval: 2 # See details below
enable_expert_tensor_parallelism: false # See details below
moe_expert_parallel_size: 1 # See details below
moe_token_dropping: false
DeepSpeed dapat dikonfigurasi lebih lanjut dengan yang berikut ini:
moe_top_k: 1
moe_min_capacity: 4
moe_train_capacity_factor: 1.0 # Setting to 1.0
moe_eval_capacity_factor: 1.0 # Setting to 1.0
Satu lapisan MoE hadir di setiap lapisan transformator expert_interval termasuk yang pertama, sehingga totalnya ada 12 lapisan:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11
Para ahli akan berada di lapisan berikut:
0, 2, 4, 6, 8, 10
Secara default, kami menggunakan paralelisme data pakar, sehingga paralelisme tensor apa pun yang tersedia ( model_parallel_size ) akan digunakan untuk perutean pakar. Misalnya, diberikan hal berikut:
expert_parallel_size: 4
model_parallel_size: 2 # aka tensor parallelism
Dengan 32 GPU, perilakunya akan terlihat seperti:
expert_parallel_size == model_parallel_size . Menyetel enable_expert_tensor_parallelism mengaktifkan paralelisme tensor-expert-data (TED). Cara menafsirkan hal di atas adalah:
expert_parallel_size == 1 atau model_parallel_size == 1 .Jadi perlu diperhatikan bahwa DP harus habis dibagi (MP*EP). Untuk lebih jelasnya, lihat makalah TED.
Paralelisme saluran pipa belum didukung - segera hadir!
Beberapa kumpulan data yang telah dikonfigurasi sebelumnya tersedia, termasuk sebagian besar komponen dari Pile, serta kumpulan rangkaian kereta Pile itu sendiri, untuk tokenisasi langsung menggunakan titik masuk prepare_data.py .
Misalnya, untuk mengunduh dan memberi token pada kumpulan data enwik8 dengan Tokenizer GPT2, menyimpannya ke ./data Anda dapat menjalankan:
python prepare_data.py -d ./data
atau satu pecahan tumpukan ( pile_subset ) dengan tokenizer GPT-NeoX-20B (dengan asumsi Anda menyimpannya di ./20B_checkpoints/20B_tokenizer.json ):
python prepare_data.py -d ./data -t HFTokenizer --vocab-file ./20B_checkpoints/20B_tokenizer.json pile_subset
Data yang diberi token akan disimpan ke dua file: [data-dir]/[dataset-name]/[dataset-name]_text_document.bin dan [data-dir]/[dataset-name]/[dataset-name]_text_document.idx . Anda perlu menambahkan awalan yang dibagikan oleh kedua file ini ke file konfigurasi pelatihan Anda di bawah bidang data-path . MISALNYA:
" data-path " : " ./data/enwik8/enwik8_text_document " , Untuk mempersiapkan kumpulan data Anda sendiri untuk pelatihan dengan data khusus, formatlah sebagai satu file besar berformat jsonl dengan setiap item dalam daftar kamus menjadi dokumen terpisah. Teks dokumen harus dikelompokkan dalam satu kunci JSON, yaitu "text" . Data tambahan apa pun yang disimpan di bidang lain tidak akan digunakan.
Selanjutnya pastikan untuk mendownload vocab tokenizer GPT2, dan gabungkan file dari link berikut:
Atau gunakan tokenizer 20B (yang hanya memerlukan satu file Vocab):
(sebagai alternatif, Anda dapat menyediakan file tokenizer apa pun yang dapat dimuat oleh pustaka tokenizer Hugging Face dengan perintah Tokenizer.from_pretrained() )
Anda sekarang dapat melakukan pretokenisasi data Anda menggunakan tools/datasets/preprocess_data.py , argumennya dirinci di bawah ini:
usage: preprocess_data.py [-h] --input INPUT [--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]] [--num-docs NUM_DOCS] --tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer} [--vocab-file VOCAB_FILE] [--merge-file MERGE_FILE] [--append-eod] [--ftfy] --output-prefix OUTPUT_PREFIX
[--dataset-impl {lazy,cached,mmap}] [--workers WORKERS] [--log-interval LOG_INTERVAL]
optional arguments:
-h, --help show this help message and exit
input data:
--input INPUT Path to input jsonl files or lmd archive(s) - if using multiple archives, put them in a comma separated list
--jsonl-keys JSONL_KEYS [JSONL_KEYS ...]
space separate listed of keys to extract from jsonl. Default: text
--num-docs NUM_DOCS Optional: Number of documents in the input data (if known) for an accurate progress bar.
tokenizer:
--tokenizer-type {HFGPT2Tokenizer,HFTokenizer,GPT2BPETokenizer,CharLevelTokenizer}
What type of tokenizer to use.
--vocab-file VOCAB_FILE
Path to the vocab file
--merge-file MERGE_FILE
Path to the BPE merge file (if necessary).
--append-eod Append an <eod> token to the end of a document.
--ftfy Use ftfy to clean text
output data:
--output-prefix OUTPUT_PREFIX
Path to binary output file without suffix
--dataset-impl {lazy,cached,mmap}
Dataset implementation to use. Default: mmap
runtime:
--workers WORKERS Number of worker processes to launch
--log-interval LOG_INTERVAL
Interval between progress updates
Misalnya:
python tools/datasets/preprocess_data.py
--input ./data/mydataset.jsonl.zst
--output-prefix ./data/mydataset
--vocab ./data/gpt2-vocab.json
--merge-file gpt2-merges.txt
--dataset-impl mmap
--tokenizer-type GPT2BPETokenizer
--append-eodAnda kemudian akan menjalankan pelatihan dengan pengaturan berikut ditambahkan ke file konfigurasi Anda:
" data-path " : " data/mydataset_text_document " , Pelatihan diluncurkan menggunakan deepy.py , pembungkus peluncur DeepSpeed, yang meluncurkan skrip yang sama secara paralel di banyak GPU/node.
Pola penggunaan umumnya adalah:
python ./deepy.py train.py [path/to/config1.yml] [path/to/config2.yml] ...Anda dapat meneruskan sejumlah konfigurasi yang semuanya akan digabungkan saat runtime.
Anda juga dapat memasukkan awalan konfigurasi secara opsional, yang akan menganggap semua konfigurasi Anda berada di folder yang sama dan menambahkan awalan tersebut ke jalurnya.
Misalnya:
python ./deepy.py train.py -d configs 125M.yml local_setup.yml Ini akan menerapkan skrip train.py di semua node dengan satu proses per GPU. Node pekerja dan jumlah GPU ditentukan dalam file /job/hostfile (lihat dokumentasi parameter), atau dapat dengan mudah diteruskan sebagai argumen num_gpus jika berjalan pada pengaturan node tunggal.
Meskipun hal ini tidak sepenuhnya diperlukan, kami merasa berguna untuk menentukan parameter model dalam satu file konfigurasi (misalnya configs/125M.yml ) dan parameter jalur data di file lain (misalnya configs/local_setup.yml ).
GPT-NeoX-20B adalah model bahasa autoregresif dengan 20 miliar parameter yang dilatih di Pile. Detail teknis tentang GPT-NeoX-20B dapat ditemukan di makalah terkait. File konfigurasi untuk model ini tersedia di ./configs/20B.yml dan disertakan dalam tautan unduhan di bawah.
Bobot ramping - (Tidak ada status pengoptimal, untuk inferensi atau penyempurnaan, 39 GB)
Untuk mengunduh dari baris perintah ke folder bernama 20B_checkpoints , gunakan perintah berikut:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/slim_weights/ -P 20B_checkpointsBobot penuh - (Termasuk status pengoptimal, 268GB)
Untuk mengunduh dari baris perintah ke folder bernama 20B_checkpoints , gunakan perintah berikut:
wget --cut-dirs=5 -nH -r --no-parent --reject " index.html* " https://the-eye.eu/public/AI/models/GPT-NeoX-20B/full_weights/ -P 20B_checkpointsBobot alternatif dapat diunduh menggunakan klien BitTorrent. File torrent dapat diunduh di sini: bobot ramping, bobot penuh.
Kami juga memiliki 150 pos pemeriksaan yang disimpan selama pelatihan, satu pos pemeriksaan setiap 1.000 langkah. Kami sedang berupaya mencari cara terbaik untuk melayani pos-pos ini dalam skala besar, namun sementara itu orang-orang yang tertarik untuk bekerja dengan pos-pos pemeriksaan yang sebagian terlatih dapat mengirim email kepada kami di [email protected] untuk mengatur akses.
Pythia Scaling Suite adalah rangkaian model mulai dari 70 juta parameter hingga 12 miliar parameter yang dilatih di Pile yang dimaksudkan untuk mempromosikan penelitian tentang kemampuan interpretasi dan dinamika pelatihan model bahasa besar. Rincian lebih lanjut tentang proyek dan tautan ke model dapat ditemukan di makalah dan di GitHub proyek.
Proyek Polyglot adalah upaya untuk melatih model bahasa non-Inggris yang telah dilatih sebelumnya untuk mempromosikan aksesibilitas teknologi ini kepada para peneliti di luar pusat pembelajaran mesin yang dominan. EleutherAI telah melatih dan merilis model bahasa Korea dengan parameter 1,3B, 3,8B, dan 5,8B, yang terbesar mengungguli semua model bahasa lain yang tersedia untuk umum dalam tugas-tugas bahasa Korea. Rincian lebih lanjut tentang proyek dan tautan ke model dapat ditemukan di sini.
Untuk sebagian besar penggunaan, kami merekomendasikan penerapan model yang dilatih menggunakan pustaka GPT-NeoX melalui pustaka Hugging Face Transformers yang lebih dioptimalkan untuk inferensi.
Kami mendukung tiga jenis pembangkitan dari model yang telah dilatih sebelumnya:
Ketiga jenis pembuatan teks dapat diluncurkan melalui python ./deepy.py generate.py -d configs 125M.yml local_setup.yml text_generation.yml dengan nilai yang sesuai yang ditetapkan dalam configs/text_generation.yml .
GPT-NeoX mendukung evaluasi tugas hilir melalui pemanfaatan evaluasi model bahasa.
Untuk mengevaluasi model terlatih pada memanfaatkan evaluasi, cukup jalankan:
python ./deepy.py eval.py -d configs your_configs.yml --eval_tasks task1 task2 ... taskn di mana --eval_tasks adalah daftar tugas evaluasi yang diikuti dengan spasi, misalnya --eval_tasks lambada hellaswag piqa sciq . Untuk detail semua tugas yang tersedia, lihat repo lm-evaluation-harness.
GPT-NeoX sangat dioptimalkan untuk pelatihan saja, dan pos pemeriksaan model GPT-NeoX tidak kompatibel dengan pustaka pembelajaran mendalam lainnya. Untuk membuat model mudah dimuat dan dibagikan dengan pengguna akhir, dan untuk diekspor lebih lanjut ke berbagai kerangka kerja lainnya, GPT-NeoX mendukung konversi pos pemeriksaan ke format Hugging Face Transformers.
Meskipun NeoX mendukung sejumlah konfigurasi arsitektur yang berbeda, termasuk penyematan posisi AliBi, tidak semua konfigurasi ini terpetakan dengan rapi ke konfigurasi yang didukung dalam Hugging Face Transformers.
NeoX mendukung ekspor model yang kompatibel ke arsitektur berikut:
Melatih model yang tidak sesuai dengan salah satu arsitektur Hugging Face Transformers ini memerlukan penulisan kode pemodelan khusus untuk model yang diekspor.
Untuk mengonversi pos pemeriksaan perpustakaan GPT-NeoX ke format Hugging Face-loadable, jalankan:
python ./tools/ckpts/convert_neox_to_hf.py --input_dir /path/to/model/global_stepXXX --config_file your_config.yml --output_dir hf_model/save/location --precision {auto,fp16,bf16,fp32} --architecture {neox,mistral,llama}Kemudian untuk mengunggah model ke Hugging Face Hub, jalankan:
huggingface-cli login
python ./tools/ckpts/upload.pydan masukkan informasi yang diminta, termasuk token pengguna hub HF.
NeoX menyediakan beberapa utilitas untuk mengubah pos pemeriksaan model yang telah dilatih sebelumnya menjadi format yang dapat dilatih di dalam perpustakaan.
Model atau rangkaian model berikut dapat dimuat di GPT-NeoX:
Kami menyediakan dua utilitas untuk mengonversi dari dua format pos pemeriksaan berbeda ke format yang kompatibel dengan GPT-NeoX.
Untuk mengonversi pos pemeriksaan Llama 1 atau Llama 2 yang didistribusikan oleh Meta AI dari format file aslinya (dapat diunduh di sini atau di sini) ke perpustakaan GPT-NeoX, jalankan
python tools/ckpts/convert_raw_llama_weights_to_neox.py --input_dir /path/to/model/parent/dir/7B --model_size 7B --output_dir /path/to/save/ckpt --num_output_shards <TENSOR_PARALLEL_SIZE> (--pipeline_parallel if pipeline-parallel-size >= 1)
Untuk mengkonversi dari model Hugging Face menjadi NeoX-loadable, jalankan tools/ckpts/convert_hf_to_sequential.py . Lihat dokumentasi dalam file tersebut untuk opsi lebih lanjut.
Selain menyimpan log secara lokal, kami menyediakan dukungan bawaan untuk dua kerangka pemantauan eksperimen populer: Bobot & Bias, TensorBoard, dan Comet
Bobot & Bias untuk mencatat eksperimen kami adalah platform pemantauan pembelajaran mesin. Untuk menggunakan tongkat sihir untuk memantau eksperimen gpt-neox Anda:
wandb login —perjalanan Anda akan direkam secara otomatis../requirements/requirements-wandb.txt . Contoh konfigurasi disediakan di ./configs/local_setup_wandb.yml .wandb_group memungkinkan Anda memberi nama grup proses dan wandb_team memungkinkan Anda menetapkan proses ke akun organisasi atau tim. Contoh konfigurasi disediakan di ./configs/local_setup_wandb.yml . Kami mendukung penggunaan TensorBoard melalui kolom tensorboard-dir . Dependensi yang diperlukan untuk pemantauan TensorBoard dapat ditemukan dan diinstal dari ./requirements/requirements-tensorboard.txt .
Comet adalah platform pemantauan pembelajaran mesin. Untuk menggunakan komet guna memantau eksperimen gpt-neox Anda:
comet login atau meneruskan export COMET_API_KEY=<your-key-here>comet_ml dan pustaka ketergantungan apa pun melalui pip install -r requirements/requirements-comet.txtuse_comet: True . Anda juga dapat menyesuaikan lokasi pencatatan data dengan comet_workspace dan comet_project . Contoh lengkap konfigurasi dengan komet diaktifkan disediakan di configs/local_setup_comet.yml . Jika Anda perlu menyediakan file host untuk digunakan dengan peluncur DeepSpeed berbasis MPI, Anda dapat mengatur variabel lingkungan DLTS_HOSTFILE agar mengarah ke file host.
Kami mendukung pembuatan profil dengan Nsight Systems, PyTorch Profiler, dan PyTorch Memory Profiling.
Untuk menggunakan pembuatan profil Sistem Nsight, atur opsi konfigurasi profile , profile_step_start , dan profile_step_stop (lihat di sini untuk penggunaan argumen, dan di sini untuk contoh konfigurasi).
Untuk mengisi metrik nsys, luncurkan pelatihan dengan:
nsys profile -s none -t nvtx,cuda -o <path/to/profiling/output> --force-overwrite true
--capture-range=cudaProfilerApi --capture-range-end=stop python $TRAIN_PATH/deepy.py
$TRAIN_PATH/train.py --conf_dir configs <config files>
File keluaran yang dihasilkan kemudian dapat dilihat dengan GUI Sistem Nsight:
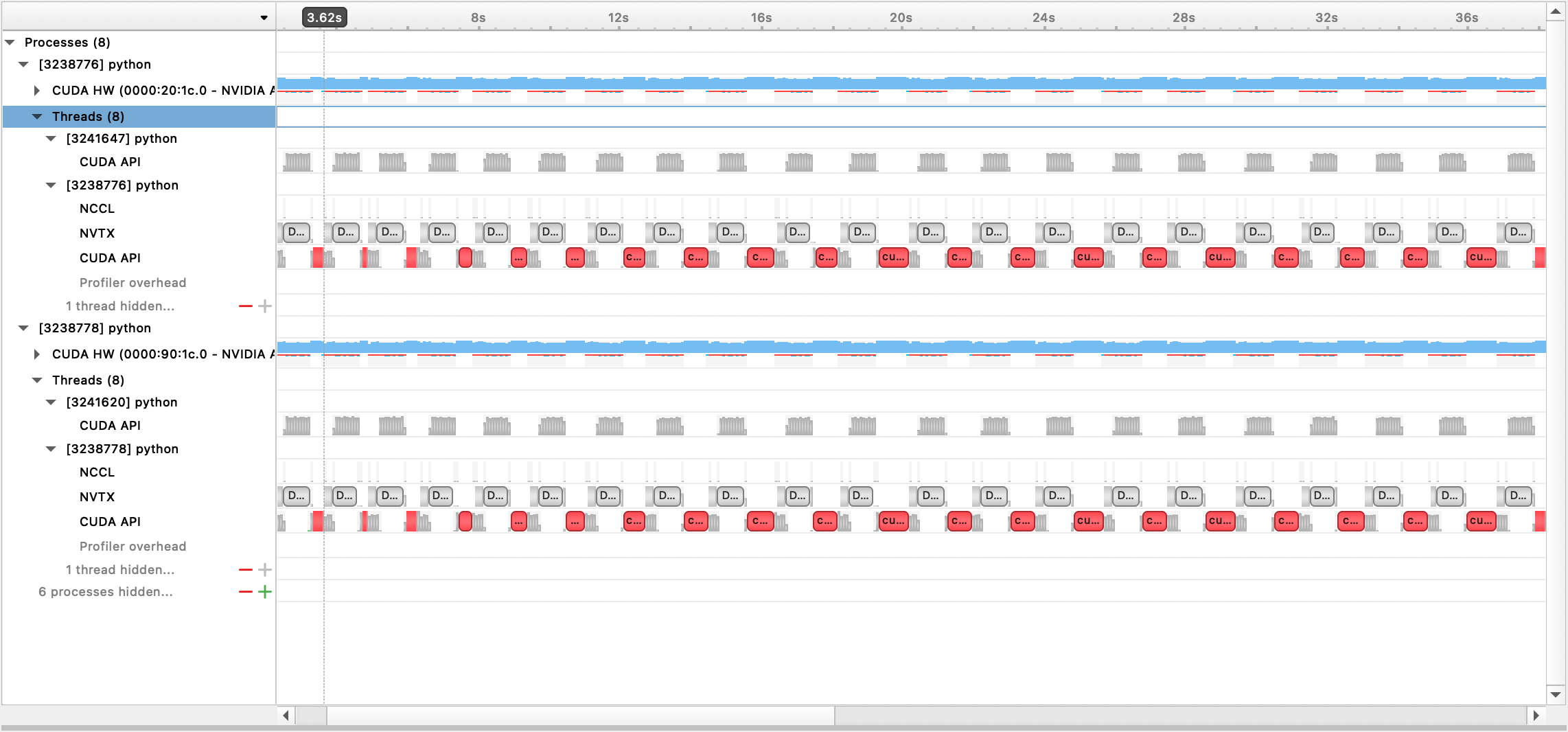
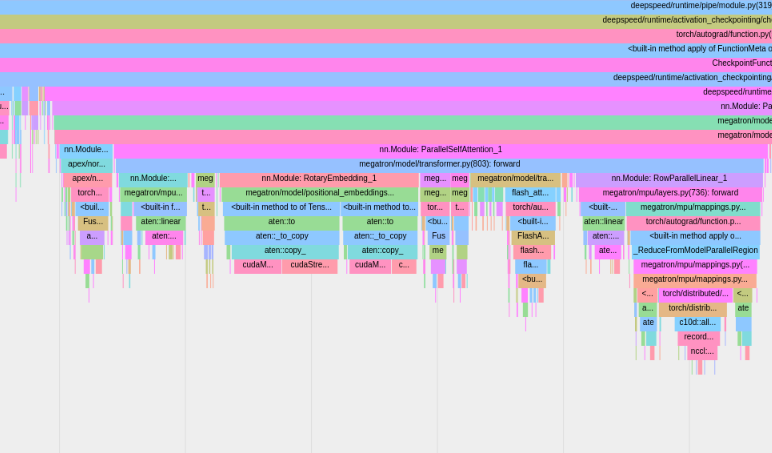
Untuk menggunakan profiler PyTorch bawaan, atur opsi konfigurasi profile , profile_step_start , dan profile_step_stop (lihat di sini untuk penggunaan argumen, dan di sini untuk contoh konfigurasi).
Profiler PyTorch akan menyimpan jejak ke direktori log tensorboard Anda. Anda dapat melihat jejak ini dalam TensorBoard dengan mengikuti langkah-langkah di sini.
Untuk menggunakan Profil Memori PyTorch, setel opsi konfigurasi memory_profiling dan memory_profiling_path (lihat di sini untuk penggunaan argumen, dan di sini untuk contoh konfigurasi).
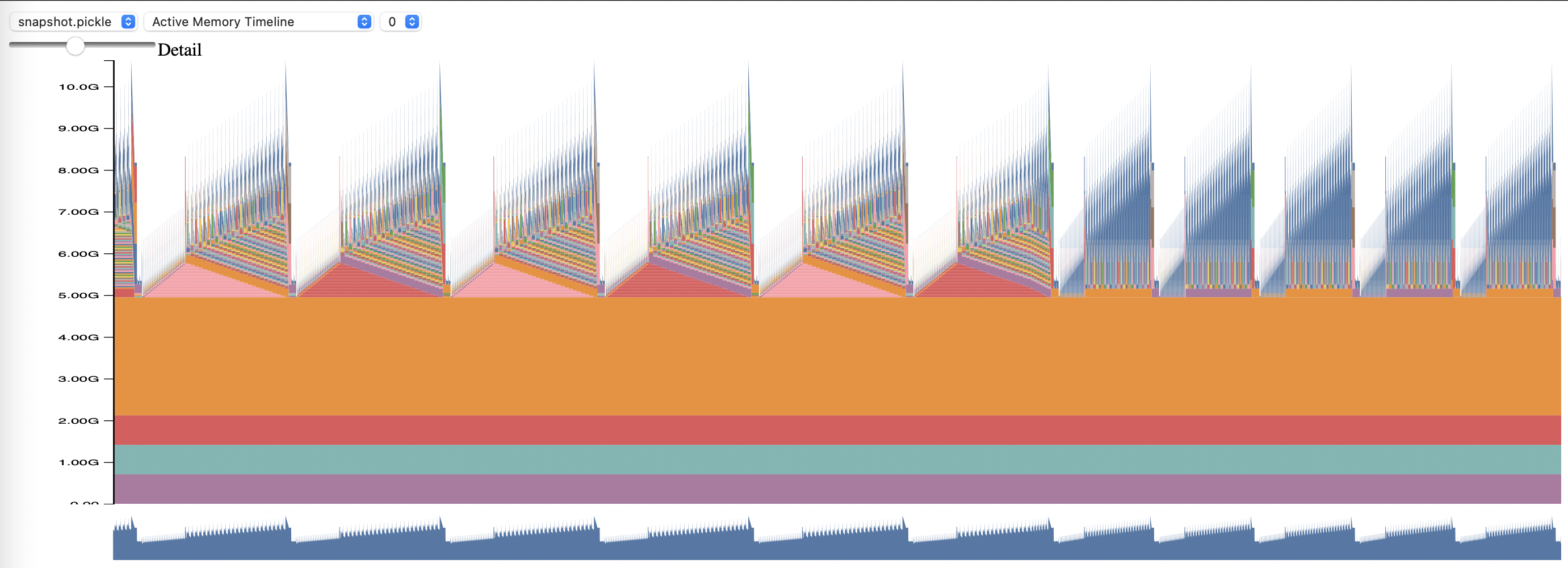
Lihat profil yang dihasilkan dengan skrip memory_viz.py. Jalankan dengan:
python _memory_viz.py trace_plot <generated_profile> -o trace.html
Pustaka GPT-NeoX telah diadopsi secara luas oleh peneliti akademis dan industri dan diterapkan ke banyak sistem HPC.
Jika Anda merasa perpustakaan ini berguna dalam penelitian Anda, silakan hubungi kami dan beri tahu kami! Kami ingin menambahkan Anda ke daftar kami.
EleutherAI dan kolaborator kami telah menggunakannya dalam publikasi berikut:
Publikasi berikut oleh kelompok penelitian lain menggunakan perpustakaan ini:


