Awesome Attention Heads
vey on LLM attention heads
Penting
Tentang repo ini. Ini adalah platform untuk mendapatkan penelitian terbaru tentang berbagai jenis Kepala Perhatian LLM. Kami juga merilis survei berdasarkan karya-karya fantastis ini.
Jika Anda ingin mengutip karya kami , berikut entri bibtex kami: CITATION.bib.
Jika Anda hanya ingin melihat daftar makalah terkait, silakan langsung lompat ke sini.
Jika Anda ingin berkontribusi pada repo ini, lihat di sini.
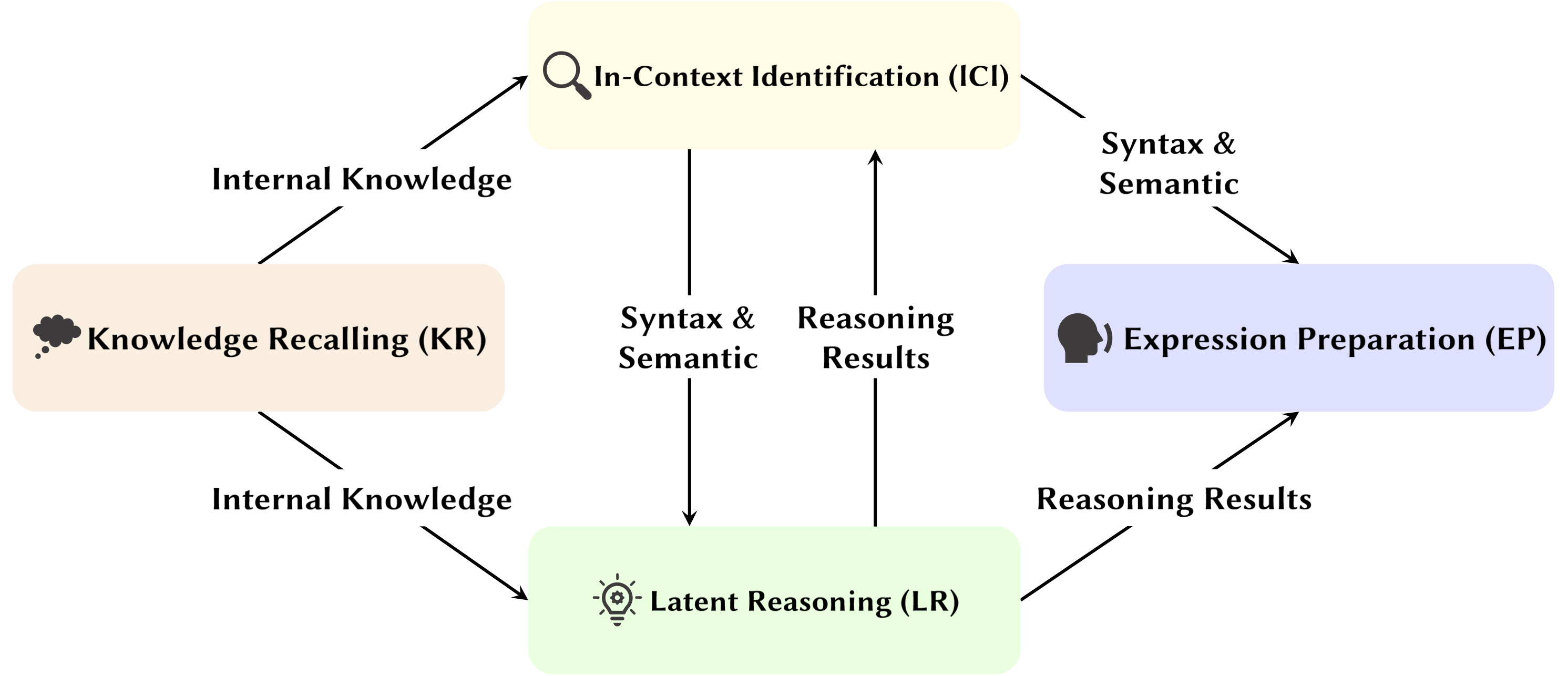
Dengan berkembangnya Large Language Model (LLM), struktur jaringan yang mendasarinya, Transformer, sedang dipelajari secara ekstensif. Meneliti struktur Transformer membantu kita meningkatkan pemahaman kita tentang "kotak hitam" ini dan meningkatkan kemampuan interpretasi model. Baru-baru ini, semakin banyak penelitian yang menunjukkan bahwa model tersebut berisi dua partisi berbeda: mekanisme perhatian yang digunakan untuk perilaku, inferensi, dan analisis, dan Jaringan Feed-Forward (FFN) untuk penyimpanan pengetahuan. Yang pertama sangat penting untuk mengungkapkan kemampuan fungsional model, yang mengarah pada serangkaian penelitian yang mengeksplorasi berbagai fungsi dalam mekanisme perhatian, yang kami sebut sebagai Attention Head Mining .
Dalam survei ini, kami menyelidiki mekanisme potensial tentang bagaimana perhatian kepala di LLM berkontribusi pada proses penalaran.
Highlight:
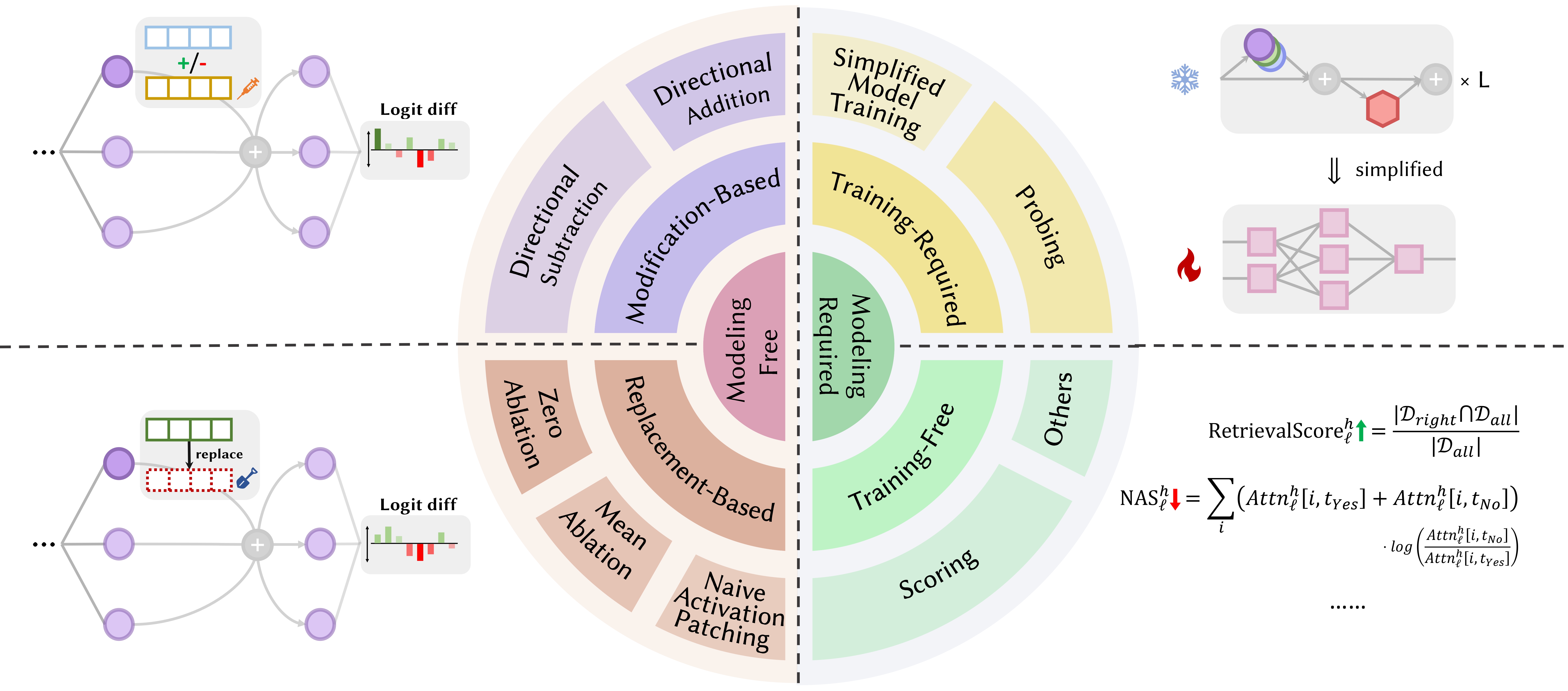
Makalah di bawah ini diurutkan berdasarkan tanggal publikasi :
Tahun 2024
| Tanggal | Makalah & Ringkasan | Tag | Tautan |
| 15-11-2024 | SEEKR: Retensi Pengetahuan yang Dipandu Perhatian Selektif untuk Pembelajaran Berkelanjutan Model Bahasa Besar | ||
| • Mengusulkan SEEKR, metode retensi pengetahuan yang dipandu perhatian selektif untuk pembelajaran berkelanjutan di LLM, dengan fokus pada kepala perhatian utama untuk distilasi yang efisien. • Dievaluasi berdasarkan tolok ukur pembelajaran berkelanjutan TRACE dan SuperNI. • SEEKR mencapai kinerja yang sebanding atau lebih baik dengan hanya 1% data replay dibandingkan metode lain. | |||
| 06-11-2024 | Bagaimana Transformers Memecahkan Masalah Logika Proposisional: Analisis Mekanistik | ||
| • Mengidentifikasi rangkaian perhatian khusus pada transformator yang memecahkan masalah logika proposisional, dengan fokus pada mekanisme "perencanaan" dan "penalaran". • Menganalisis trafo kecil dan Mistral-7B, menggunakan patch aktivasi untuk mengungkap jalur penalaran. • Menemukan kepala perhatian berbeda yang mengkhususkan diri pada lokasi aturan, pemrosesan fakta, dan pengambilan keputusan dalam penalaran logis. | |||
| 01-11-2024 | Pelacak Perhatian: Mendeteksi Serangan Injeksi Segera di LLM | ||
| • Usulan Attention Tracker, penjaga bebas pelatihan sederhana namun efektif yang mendeteksi serangan injeksi cepat berdasarkan Kepala Penting yang teridentifikasi. • Mengidentifikasi kepala-kepala penting hanya dengan menggunakan sekumpulan kecil kalimat acak yang dihasilkan LLM yang dikombinasikan dengan serangan pengabaian yang naif. • Attention Tracker efektif pada LM kecil dan besar, mengatasi keterbatasan signifikan metode deteksi bebas pelatihan sebelumnya. | |||
| 28-10-2024 | Aritmatika Tanpa Algoritma: Model Bahasa Menyelesaikan Matematika Dengan Sekantong Heuristik | ||
| • Mengidentifikasi subset model (rangkaian) yang menjelaskan sebagian besar perilaku model untuk logika aritmatika dasar dan memeriksa fungsinya. • Menganalisis pola perhatian menggunakan perintah aritmatika dua operan dengan angka Arab dan empat operator dasar (+, −, ×, ÷). • Untuk penjumlahan, pengurangan, dan pembagian, 6 kepala perhatian menghasilkan kesetiaan yang tinggi (rata-rata 97%), sedangkan perkalian membutuhkan 20 kepala untuk melebihi 90% kesetiaan. | |||
| 21-10-2024 | Evaluasi Psikolinguistik Sensitivitas Model Bahasa terhadap Peran Argumen | ||
| • Mengamati kepala subjek dalam suasana yang lebih umum. • Menganalisis pola perhatian dalam kondisi argumen tukar dan argumen ganti. • Meskipun mampu membedakan peran, model mungkin kesulitan menggunakan informasi peran argumen dengan benar, karena masalahnya terletak pada bagaimana informasi ini dikodekan ke dalam representasi kata kerja, sehingga sensitivitas peran menjadi lebih lemah. | |||
| 17-10-2024 | Kepala Perhatian Aktif-Tidak Aktif: Secara Mekanis Mengungkap Fenomena Token Ekstrim di LLM | ||
| • Mendemonstrasikan bahwa fenomena token ekstrem muncul dari mekanisme aktif-tidak aktif di kepala perhatian, ditambah dengan mekanisme saling menguatkan selama pra-pelatihan. • Menggunakan transformator sederhana yang dilatih pada tugas Bigram-Backcopy (BB) untuk menganalisis fenomena token ekstrem dan memperluasnya ke LLM yang telah dilatih sebelumnya. • Banyak sifat statis dan dinamis dari fenomena token ekstrem yang diprediksi oleh tugas BB selaras dengan observasi di LLM yang telah dilatih sebelumnya. | |||
| 17-10-2024 | Tentang Peran Kepala Perhatian dalam Keamanan Model Bahasa Besar | ||
| • Mengusulkan metrik baru yang disesuaikan untuk perhatian multi-kepala, Safety Head ImPortant Score (Ships), untuk menilai kontribusi masing-masing kepala terhadap keselamatan model. • Melakukan analisis terhadap fungsi kepala perhatian keselamatan ini, mengeksplorasi karakteristik dan mekanismenya. • Kepala perhatian tertentu sangat penting untuk keselamatan, kepala keselamatan tumpang tindih di seluruh model yang telah disesuaikan, dan menghilangkan kepala ini akan berdampak minimal pada kegunaannya. | |||
| 14-10-2024 | DuoAttention: Inferensi LLM Konteks Panjang yang Efisien dengan Kepala Pengambilan dan Streaming | ||
| • Memperkenalkan DuoAttention, sebuah kerangka kerja yang mengurangi decoding dan memori serta latensi pra-pengisian LLM tanpa mengorbankan kemampuan konteks panjangnya, berdasarkan penemuan Retrieval Heads dan Streaming Heads dalam LLM. • Menguji dampak kerangka kerja terhadap kinerja LLM dalam tugas konteks pendek dan konteks panjang, serta efisiensi inferensinya. • Dengan menerapkan cache KV penuh hanya pada kepala pengambilan, DuoAttention secara signifikan mengurangi penggunaan memori dan latensi untuk decoding dan pra-pengisian dalam aplikasi konteks panjang. | |||
| 14-10-2024 | Mengunci Keamanan LLM yang Disempurnakan | ||
| • Memperkenalkan SafetyLock, sebuah metode baru dan efisien untuk menjaga keamanan model bahasa besar yang telah disesuaikan di berbagai tingkat risiko dan skenario serangan, berdasarkan penemuan Kepala Keselamatan dalam LLM. • Mengevaluasi efektivitas SafetyLock dalam meningkatkan keamanan model dan efisiensi inferensi. • Dengan menerapkan vektor intervensi pada kepala keselamatan, SafetyLock dapat memodifikasi aktivasi internal model menjadi tidak berbahaya selama inferensi, sehingga mencapai keselarasan keselamatan yang tepat dengan dampak minimal pada respons. | |||
| 2024-10-11 | Sama Tapi Berbeda: Persamaan dan Perbedaan Struktural dalam Pemodelan Bahasa Multibahasa | ||
| • Melakukan studi mendalam tentang komponen spesifik yang diandalkan oleh model multibahasa saat melakukan tugas yang memerlukan proses morfologi spesifik bahasa. • Selidiki perbedaan fungsional komponen model internal ketika melakukan tugas dalam bahasa Inggris dan Cina. • Copy head memiliki frekuensi aktivasi yang sama tinggi di kedua bahasa sedangkan past tense head hanya sering diaktifkan dalam bahasa Inggris. | |||
| 08-10-2024 | Berputar-putar Kita Bergerak! Apa yang membuat Pengodean Posisi Putar berguna? | ||
| • Memberikan analisis mendalam tentang internal model Gemma 7B yang terlatih untuk memahami bagaimana RoPE digunakan pada tingkat mekanis. • Memahami penggunaan frekuensi yang berbeda dalam kueri dan kunci. • Menemukan bahwa frekuensi tertinggi di RoPE secara cerdik digunakan oleh Gemma 7B untuk membuat kepala perhatian 'posisi' khusus (Kepala diagonal, Kepala token sebelumnya), sedangkan frekuensi rendah digunakan oleh kepala Apostrof. | |||
| 06-10-2024 | Meninjau Kembali Sirkuit Inferensi Pembelajaran Dalam Konteks dalam Model Bahasa Besar | ||
| • Mengusulkan rangkaian inferensi 3 langkah yang komprehensif untuk mengkarakterisasi proses inferensi ICL. • Membagi ICL menjadi tiga tahap: Meringkas, Penggabungan Semantik, dan Pengambilan dan Penyalinan Fitur, menganalisis peran setiap tahap dalam ICL dan mekanisme operasionalnya. • Ditemukan bahwa sebelum kepala Induksi, Kepala Token Forerunner terlebih dahulu menggabungkan representasi teks demonstrasi dari token pendahulu ke dalam token label yang sesuai, secara selektif berdasarkan kompatibilitas antara demonstrasi dan semantik label. | |||
| 01-10-2024 | Dekomposisi Perhatian Jarang Diterapkan pada Pelacakan Sirkuit | ||
| • Memperkenalkan Dekomposisi Sparse Attention, menggunakan SVD pada matriks kepala perhatian untuk melacak jalur komunikasi dalam model GPT-2. • Diterapkan pada penelusuran sirkuit di GPT-2 kecil untuk tugas Identifikasi Objek Tidak Langsung (IOI). • Mengidentifikasi sinyal komunikasi yang jarang dan signifikan secara fungsional antara kepala perhatian, sehingga meningkatkan kemampuan interpretasi. | |||
| 09-09-2024 | Mengungkap Kepala Induksi: Dinamika Pelatihan dan Pembelajaran Fitur yang Terbukti di Transformers | ||
| • Makalah ini memperkenalkan mekanisme kepala induksi umum, menjelaskan bagaimana komponen transformator berkolaborasi untuk melakukan pembelajaran dalam konteks (ICL) pada rantai Markov n-gram. • Menganalisis trafo dua lapisan perhatian dengan aliran gradien untuk memprediksi token dalam rantai Markov. • Aliran gradien menyatu, memungkinkan ICL melalui mekanisme kepala induksi berbasis fitur yang dipelajari. | |||
| 16-08-2024 | Interpretasi Mekanistik Penalaran Silogistik dalam Model Bahasa Auto-Regresif | ||
| • Studi ini memperkenalkan interpretasi mekanistik terhadap penalaran silogistik dalam LM, dengan mengidentifikasi rangkaian penalaran yang tidak bergantung pada konten. • Penemuan sirkuit untuk penalaran dan penyelidikan kontaminasi bias keyakinan di kepala perhatian. • Mengidentifikasi rangkaian penalaran penting yang dapat ditransfer ke seluruh skema silogistik, namun rentan terhadap kontaminasi oleh pengetahuan dunia yang telah dilatih sebelumnya. | |||
| 01-08-2024 | Meningkatkan Konsistensi Semantik Model Bahasa Besar melalui Pengeditan Model: Pendekatan Berorientasi Interpretabilitas | ||
| • Memperkenalkan pendekatan pengeditan model hemat biaya yang berfokus pada perhatian untuk meningkatkan konsistensi semantik dalam LLM tanpa perubahan parameter yang ekstensif. • Menganalisis perhatian utama, memasukkan bias, dan menguji kumpulan data NLU dan NLG. • Mencapai peningkatan penting dalam konsistensi semantik dan kinerja tugas, dengan generalisasi yang kuat di seluruh tugas tambahan. | |||
| 31-07-2024 | Mengoreksi Bias Negatif dalam Model Bahasa Besar melalui Penyelarasan Skor Perhatian Negatif | ||
| • Memperkenalkan Skor Perhatian Negatif (NAS) untuk mengukur dan memperbaiki bias negatif dalam model bahasa. • Mengidentifikasi kepala perhatian yang bias negatif dan mengusulkan Penyelarasan Skor Perhatian Negatif (NASA) untuk penyesuaian. • NASA secara efektif mengurangi kesenjangan presisi-recall sambil mempertahankan generalisasi dalam tugas pengambilan keputusan biner. | |||
| 29-07-2024 | Mendeteksi dan Memahami Kerentanan dalam Model Bahasa melalui Interpretabilitas Mekanistik | ||
| • Memperkenalkan metode yang menggunakan Mechanistic Interpretability (MI) untuk mendeteksi dan memahami kerentanan dalam LLM, khususnya serangan permusuhan. • Menganalisis GPT-2 Small untuk mengetahui kerentanan dalam memprediksi akronim 3 huruf. • Berhasil mengidentifikasi dan menjelaskan kerentanan spesifik dalam model yang terkait dengan tugas. | |||
| 22-07-2024 | RazorAttention: Kompresi Cache KV yang Efisien Melalui Retrieval Heads | ||
| • Memperkenalkan RazorAttention, teknik kompresi cache KV tanpa pelatihan menggunakan kepala pengambilan dan token kompensasi untuk menyimpan informasi token penting. • Mengevaluasi RazorAttention pada model bahasa besar (LLM) untuk efisiensi. • Mencapai pengurangan ukuran cache KV lebih dari 70% tanpa dampak kinerja yang nyata. | |||
| 21-07-2024 | Answer, Assemble, Ace: Memahami Bagaimana Transformers Menjawab Pertanyaan Pilihan Ganda | ||
| • Makalah ini memperkenalkan proyeksi kosakata dan patch aktivasi untuk melokalisasi status tersembunyi yang memprediksi jawaban MCQA yang benar. • Mengidentifikasi kepala dan lapisan perhatian utama yang bertanggung jawab atas pemilihan jawaban di transformator. • Kepala perhatian lapisan menengah sangat penting untuk prediksi jawaban yang akurat, dengan sekelompok kepala yang jarang memainkan peran yang unik. | |||
| 09-07-2024 | Kepala Induksi sebagai Mekanisme Penting untuk Pencocokan Pola dalam Pembelajaran Dalam Konteks | ||
| • Artikel ini mengidentifikasi kepala induksi sebagai hal yang penting untuk pencocokan pola dalam pembelajaran dalam konteks (ICL). • Mengevaluasi Llama-3-8B dan InternLM2-20B pada pengenalan pola abstrak dan tugas NLP. • Mengablasi kepala induksi mengurangi kinerja ICL hingga ~32%, menjadikannya hampir acak untuk pengenalan pola. | |||
| 02-07-2024 | Menafsirkan Mekanisme Aritmatika dalam Model Bahasa Besar melalui Analisis Neuron Komparatif | ||
| • Memperkenalkan Analisis Neuron Komparatif (CNA) untuk memetakan mekanisme aritmatika pada kepala model bahasa besar. • Menganalisis kemampuan aritmatika, pemangkasan model untuk tugas aritmatika, dan pengeditan model untuk mengurangi bias gender. • Mengidentifikasi neuron spesifik yang bertanggung jawab atas aritmatika, memungkinkan peningkatan kinerja dan mitigasi bias melalui manipulasi neuron yang ditargetkan. | |||
| 01-07-2024 | Mengarahkan Model Bahasa Besar untuk Pengambilan Informasi Lintas Bahasa | ||
| • Memperkenalkan Activation Steered Multilingual Retrieval (ASMR), menggunakan aktivasi pengarah untuk memandu LLM guna meningkatkan pengambilan informasi lintas bahasa. • Mengidentifikasi kepala perhatian di LLM yang mempengaruhi akurasi dan koherensi bahasa, dan menerapkan aktivasi kemudi. • ASMR mencapai kinerja tercanggih pada benchmark CLIR seperti XOR-TyDi QA dan MKQA. | |||
| 25-06-2024 | Bagaimana Transformers Mempelajari Struktur Kausal dengan Penurunan Gradien | ||
| • Memberikan penjelasan tentang bagaimana transformator mempelajari struktur sebab akibat melalui algoritma pelatihan berbasis gradien. • Menganalisis kinerja trafo dua lapis pada tugas yang disebut barisan acak dengan struktur sebab akibat. • Penurunan gradien pada transformator dua lapisan yang disederhanakan mempelajari penyelesaian tugas ini dengan menyandikan grafik sebab akibat laten pada lapisan perhatian pertama. Sebagai kasus khusus, ketika rangkaian dihasilkan dari rantai Markov dalam konteks, transformator belajar mengembangkan kepala induksi. | |||
| 21-06-2024 | MoA: Campuran Perhatian Jarang untuk Kompresi Model Bahasa Besar Otomatis | ||
| • Makalah ini memperkenalkan Mixture of Attention (MoA), yang menyesuaikan konfigurasi perhatian jarang yang berbeda untuk head dan lapisan yang berbeda, mengoptimalkan memori, throughput, dan trade-off akurasi-latensi. • Model profil MoA, mengeksplorasi konfigurasi perhatian, dan meningkatkan kompresi LLM. • MoA meningkatkan panjang konteks efektif sebesar 3,9×, sekaligus mengurangi penggunaan memori GPU sebesar 1,2-1,4×. | |||
| 19-06-2024 | Tentang Kesulitan Penalaran Rantai Pemikiran yang Setia dalam Model Bahasa Besar | ||
| • Memperkenalkan strategi baru untuk pembelajaran dalam konteks, penyesuaian, dan pengeditan aktivasi untuk meningkatkan kesetiaan penalaran Chain-of-Thought (CoT) dalam LLM. • Menguji strategi ini pada berbagai tolok ukur untuk mengevaluasi efektivitasnya. • Hanya menemukan sedikit keberhasilan dalam meningkatkan kesetiaan CoT, menyoroti tantangan dalam mencapai penalaran yang benar-benar setia dalam LLM. | |||
| 04-06-2024 | Kepala Iterasi: Studi Mekanistik Rantai Pemikiran | ||
| • Memperkenalkan "kepala iterasi", kepala perhatian khusus yang memungkinkan penalaran berulang dalam transformator untuk tugas-tugas Chain-of-Thought (CoT). • Analisis mekanisme perhatian, pelacakan kemunculan CoT, dan pengujian kemampuan transfer keterampilan CoT antar tugas. • Kepala iterasi secara efektif mendukung penalaran CoT, meningkatkan interpretasi model dan kinerja tugas. | |||
| 03-06-2024 | LoFiT: Penyempurnaan Lokal pada Representasi LLM | ||
| • Memperkenalkan Penyempurnaan Lokal pada Representasi LLM (LoFiT), kerangka kerja dua langkah untuk mengidentifikasi kepala perhatian penting dari tugas tertentu dan mempelajari vektor offset khusus tugas untuk melakukan intervensi pada representasi kepala yang diidentifikasi. • Mengidentifikasi beberapa hal yang menjadi perhatian penting untuk meningkatkan akurasi hilir mengenai kebenaran dan penalaran. • LoFiT mengungguli metode intervensi representasi lainnya dan mencapai kinerja yang sebanding dengan metode PEFT pada TruthfulQA, CLUTRR, dan MQuAKE, meskipun hanya melakukan intervensi pada 10% dari total perhatian kepala di LLM. | |||
| 28-05-2024 | Sirkuit Pengetahuan di Transformers Terlatih | ||
| • Memperkenalkan "sirkuit pengetahuan" dalam transformator, mengungkapkan bagaimana pengetahuan spesifik dikodekan melalui interaksi antara kepala perhatian, kepala hubungan, dan MLP. • Menganalisis GPT-2 dan TinyLLAMA untuk mengidentifikasi sirkuit pengetahuan; mengevaluasi teknik pengeditan pengetahuan. • Mendemonstrasikan bagaimana sirkuit pengetahuan berkontribusi pada perilaku model seperti halusinasi dan pembelajaran dalam konteks. | |||
| 23-05-2024 | Menghubungkan Pembelajaran Dalam Konteks di Transformers dengan Memori Episodik Manusia | ||
| • Menghubungkan pembelajaran dalam konteks dalam model Transformer dengan memori episodik manusia, menyoroti kesamaan antara kepala induksi dan model pemeliharaan dan pengambilan kontekstual (CMR). • Analisis LLM berbasis Transformer untuk menunjukkan perilaku mirip CMR di kepala perhatian. • Kepala mirip CMR muncul di lapisan tengah, mencerminkan bias ingatan manusia. | |||
| 07-05-2024 | Bagaimana GPT-2 Memprediksi Akronim? Mengekstraksi dan Memahami Sirkuit melalui Interpretabilitas Mekanistik | ||
| • Studi interpretabilitas mekanistik pertama pada GPT-2 untuk memprediksi akronim multi-token menggunakan kepala perhatian. • Mengidentifikasi dan menafsirkan rangkaian 8 kepala perhatian yang bertanggung jawab atas prediksi akronim. • Mendemonstrasikan bahwa 8 kepala ini (~5% dari total) memusatkan fungsi prediksi akronim. | |||
| 02-05-2024 | Menafsirkan dan Meningkatkan Model Bahasa Besar dalam Perhitungan Aritmatika | ||
| • Memperkenalkan penyelidikan rinci mekanisme dalam LLM melalui tugas matematika, mengikuti jalur 'identifikasi-analisis-menyempurnakan'. • Menganalisis kemampuan model dalam melakukan tugas aritmatika yang melibatkan dua operan, seperti penjumlahan, pengurangan, perkalian, dan pembagian. • Menemukan bahwa LLM sering kali melibatkan sebagian kecil (<5%) kepala perhatian, yang memainkan peran penting dalam fokus pada operan dan operator selama proses perhitungan. | |||
| 02-05-2024 | Apa yang perlu dilakukan dengan benar untuk kepala induksi? Sebuah studi mekanistik tentang sirkuit pembelajaran dalam konteks dan pembentukannya | ||
| • Memperkenalkan kerangka sebab akibat yang terinspirasi dari optogenetika untuk mempelajari pembentukan kepala induksi (IH) pada transformator. • Menganalisis kemunculan IH pada transformator menggunakan data sintetik dan mengidentifikasi tiga subsirkuit mendasar yang bertanggung jawab atas pembentukan IH. • Menemukan bahwa subsirkuit ini berinteraksi untuk mendorong pembentukan IH, bertepatan dengan perubahan fase pada hilangnya model. | |||
| 24-04-2024 | Retrieval Head Secara Mekanis Menjelaskan Faktualitas Konteks Panjang | ||
| • Mengidentifikasi "kepala pengambilan" dalam model transformator yang bertanggung jawab mengambil informasi dalam konteks yang panjang. • Investigasi sistematis terhadap kepala pengambilan di berbagai model, termasuk analisis peran mereka dalam penalaran rantai pemikiran. • Memangkas kepala pengambilan menyebabkan halusinasi, sedangkan memangkas kepala yang tidak dapat mengambil tidak mempengaruhi kemampuan pengambilan. | |||
| 27-03-2024 | Intervensi Waktu Inferensi Non-Linear: Meningkatkan Kebenaran LLM | ||
| • Memperkenalkan Intervensi Waktu Inferensi Non-Linear (NL-ITI), yang meningkatkan kebenaran LLM melalui penyelidikan dan intervensi multi-token tanpa penyesuaian. • Mengevaluasi NL-ITI pada kumpulan data pilihan ganda, termasuk TruthfulQA. • Mencapai peningkatan relatif sebesar 16% dalam akurasi MC1 pada TruthfulQA dibandingkan ITI awal. | |||
| 28-02-2024 | Cara berpikir selangkah demi selangkah: Pemahaman mekanistik tentang penalaran rantai pemikiran | ||
| • Memberikan analisis mendalam tentang penalaran yang dimediasi CoT di LLM dalam hal komponen fungsional saraf. • Membedah penalaran berbasis CoT pada penalaran fiksi sebagai komposisi dari sejumlah subtugas tetap yang memerlukan pengambilan keputusan, penyalinan, dan penalaran induktif, menganalisis mekanismenya secara terpisah. • Menemukan bahwa kepala perhatian melakukan pergerakan informasi antara token yang terkait secara ontologis (atau terkait secara negatif), sehingga menghasilkan representasi yang dapat diidentifikasi secara jelas untuk pasangan token ini. | |||
| 28-02-2024 | Pemotongan Kepala Mengakhiri Konflik: Sebuah Mekanisme untuk Menafsirkan dan Mengurangi Konflik Pengetahuan dalam Model Bahasa | ||
| • Memperkenalkan metode PH3 untuk memangkas perhatian yang bertentangan, mengurangi konflik pengetahuan dalam model bahasa tanpa pembaruan parameter. • Menerapkan PH3 untuk mengontrol ketergantungan LM pada memori internal vs. konteks eksternal dan menguji efektivitasnya pada tugas QA domain terbuka. • PH3 meningkatkan penggunaan memori internal sebesar 44,0% dan penggunaan konteks eksternal sebesar 38,5%. | |||
| 27-02-2024 | Rute Arus Informasi: Menafsirkan Model Bahasa Secara Otomatis dalam Skala Besar | ||
| • Memperkenalkan "Rute Arus Informasi" menggunakan atribusi untuk interpretasi model bahasa berbasis grafik, menghindari patching aktivasi. • Eksperimen dengan Llama 2, mengidentifikasi titik perhatian utama dan pola perilaku di berbagai domain dan tugas. • Mengungkap komponen model khusus; mengidentifikasi peran yang konsisten untuk kepala perhatian, seperti menangani token dari bagian pidato yang sama. | |||
| 20-02-2024 | Mengidentifikasi Kepala Induksi Semantik untuk Memahami Pembelajaran Dalam Konteks | ||
| • Mengidentifikasi dan mempelajari "kepala induksi semantik" dalam model bahasa besar (LLM) yang berkorelasi dengan kemampuan pembelajaran dalam konteks. • Menganalisis perhatian terhadap pengkodean ketergantungan sintaksis dan hubungan grafik pengetahuan. • Kepala perhatian tertentu meningkatkan logit keluaran dengan mengingat token yang relevan, yang penting untuk memahami pembelajaran dalam konteks di LLM. | |||
| 16-02-2024 | Evolusi Kepala Induksi Statistik: Pembelajaran Dalam Konteks Rantai Markov | ||
| • Memperkenalkan tugas pemodelan rangkaian Markov Chain untuk menganalisis bagaimana kemampuan pembelajaran dalam konteks (ICL) muncul dalam transformator, membentuk "kepala induksi statistik". • Investigasi empiris dan teoritis pelatihan multi-fase pada transformator pada tugas Markov Chain. • Mendemonstrasikan transisi fase dari prediksi unigram ke bigram, yang dipengaruhi oleh interaksi lapisan transformator. | |||
| 11-02-2024 | Menyimpulkan Fakta: Mekanisme Aditif di Balik Penarikan Faktual di LLM | ||
| • Mengidentifikasi dan menjelaskan "motif aditif" dalam penarikan faktual, dimana LLM menggunakan berbagai mekanisme independen yang secara konstruktif mengganggu penarikan kembali fakta. • Memperluas atribusi logit langsung untuk menganalisis perhatian kepala dan membongkar perilaku kepala campuran. • Menunjukkan bahwa penarikan faktual dalam LLM dihasilkan dari penjumlahan beberapa kontribusi yang tidak mencukupi dan independen. | |||
| 05-02-2024 | Bagaimana Model Bahasa Besar Belajar Dalam Konteks? Kueri dan Matriks Kunci dari In-Context Heads adalah Dua Menara untuk Pembelajaran Metrik | ||
| • Memperkenalkan konsep bahwa kueri dan matriks kunci dalam kepala dalam konteks beroperasi sebagai "dua menara" untuk pembelajaran metrik, memfasilitasi penghitungan kesamaan antara fitur label. • Menganalisis mekanisme pembelajaran dalam konteks; mengidentifikasi perhatian khusus yang penting bagi ICL. • Mengurangi akurasi ICL dari 87,6% menjadi 24,4% dengan melakukan intervensi hanya pada 1% head tersebut. | |||
| 23-01-2024 | Pembelajaran Bahasa Dalam Konteks: Arsitektur dan Algoritma | ||
| • Pengenalan "n-gram head," kepala perhatian Transformer khusus, meningkatkan pembelajaran bahasa dalam konteks (ICLL) melalui prediksi token bersyarat masukan. • Mengevaluasi model saraf pada bahasa reguler dari automata terbatas acak. • Head n-gram dengan kabel keras meningkatkan kebingungan sebesar 6,7% pada dataset SlimPajama. | |||
| 16-01-2024 | Dasar mekanistik dari ketergantungan data dan pembelajaran mendadak dalam tugas klasifikasi dalam konteks | ||
| • Makalah ini memodelkan dasar mekanistik pembelajaran dalam konteks (ICL) melalui pembentukan kepala induksi secara tiba-tiba dalam jaringan perhatian saja. • Simulasi tugas ICL menggunakan data masukan yang disederhanakan dan jaringan berbasis perhatian dua lapis. • Pembentukan kepala induksi mendorong transisi mendadak ke ICL, yang ditelusuri melalui non-linearitas yang tersarang. | |||
| 16-01-2024 | Penggunaan Kembali Komponen Sirkuit di Seluruh Tugas dalam Model Bahasa Transformer | ||
| • Makalah ini menunjukkan bahwa rangkaian tertentu di GPT-2 dapat digeneralisasikan untuk berbagai tugas, sehingga menantang anggapan bahwa rangkaian tersebut bersifat khusus untuk tugas tertentu. • Ini menguji penggunaan kembali sirkuit dari tugas Identifikasi Objek Tidak Langsung (IOI) dalam tugas Objek Berwarna. • Menyesuaikan empat kepala perhatian akan meningkatkan akurasi dari 49,6% menjadi 93,7% dalam tugas Objek Berwarna. | |||
| 16-01-2024 | Kepala Penerus: Kepala Perhatian yang Berulang dan Dapat Ditafsirkan Di Alam Liar | ||
| • Makalah ini memperkenalkan "Kepala Penerus," kepala perhatian di LLM yang menambah token dengan urutan alami, seperti hari atau angka. • Analisis ini menganalisis pembentukan kepala penerus di berbagai ukuran model dan arsitektur, seperti GPT-2 dan Llama-2. • Kepala penerus ditemukan dalam model dengan rentang parameter 31M hingga 12B, yang menampilkan representasi numerik berulang dan abstrak. | |||
| 16-01-2024 | Vektor Fungsi dalam Model Bahasa Besar | ||
| • Artikel ini memperkenalkan "Function Vectors (FVs)," representasi tugas yang ringkas dan kausal dalam model transformator autoregresif. • FV diuji pada beragam tugas, model, dan lapisan pembelajaran dalam konteks (ICL). • FV dapat dijumlahkan untuk membuat vektor yang memicu tugas baru dan kompleks, yang menunjukkan komposisi vektor internal. | |||
| Tanggal | Makalah & Ringkasan | Tag | Tautan |
| 23-12-2023 | Pencarian Fakta: Mencoba Merekayasa Balik Pengingat Faktual pada Tingkat Neuron | ||
| • Menyelidiki bagaimana lapisan MLP awal di Pythia 2.8B menyandikan ingatan faktual menggunakan sirkuit terdistribusi, dengan fokus pada superposisi dan penyematan multi-token. • Menjelajahi pencarian faktual di lapisan MLP, menguji hipotesis tentang mekanisme detokenisasi dan hashing. • Fungsi penarikan faktual seperti tabel pencarian terdistribusi tanpa mekanisme internal yang mudah diinterpretasikan. | |||
| 07-11-2023 | Menuju Kelanjutan Urutan yang Dapat Ditafsirkan: Menganalisis Sirkuit Bersama dalam Model Bahasa Besar | ||
| • Mendemonstrasikan keberadaan sirkuit bersama untuk tugas kelanjutan urutan serupa. • Menganalisis dan membandingkan rangkaian untuk tugas kelanjutan urutan serupa, yang mencakup peningkatan urutan angka Arab, kata bilangan, dan bulan. • Urutan yang terkait secara semantik bergantung pada subgraf sirkuit bersama dengan peran analog dan penemuan sub-sirkuit serupa di seluruh model dengan fungsi analog. | |||
| 23-10-2023 | Representasi Sentimen Linier dalam Model Bahasa Besar | ||
| • Makalah ini mengidentifikasi arah linier dalam ruang aktivasi yang menangkap representasi sentimen dalam Model Bahasa Besar (LLM). • Mereka mengisolasi arah sentimen ini dan mengujinya pada tugas-tugas termasuk Stanford Sentiment Treebank. • Menghapus arah sentimen ini menyebabkan penurunan akurasi klasifikasi sebesar 76%, sehingga menyoroti pentingnya hal ini. | |||
| 06-10-2023 | Copy Suppression: Memahami Kepala Perhatian Secara Komprehensif | ||
| • Makalah ini memperkenalkan konsep penekanan penyalinan pada kepala perhatian kecil GPT-2 (L10H7), yang mengurangi penyalinan token yang naif, sehingga meningkatkan kalibrasi model. • Makalah ini menyelidiki dan menjelaskan mekanisme penindasan salinan dan perannya dalam perbaikan mandiri . • 76,9% dampak L10H7 di GPT-2 Kecil telah dijelaskan, menjadikannya deskripsi paling komprehensif tentang peran kepala perhatian. | |||
| 22-09-2023 | Intervensi Waktu Inferensi: Memunculkan Jawaban yang Benar dari Model Bahasa | ||
| • Memperkenalkan Intervensi Waktu Inferensi (ITI) untuk meningkatkan kebenaran LLM dengan menyesuaikan aktivasi model di kepala perhatian tertentu. • Peningkatan kinerja model LLaMA pada benchmark TruthfulQA. • ITI meningkatkan kebenaran model Alpaca dari 32,5% menjadi 65,1%. | |||
| 22-09-2023 | Kelahiran Transformer: Sudut Pandang Memori | ||
| • Makalah ini menyajikan perspektif berbasis memori pada transformator, menyoroti memori asosiatif dalam matriks bobot dan pembelajaran berbasis gradiennya. • Analisis empiris dinamika pelatihan pada model transformator yang disederhanakan dengan data sintetik. • Penemuan pembelajaran bigram global yang cepat dan munculnya "kepala induksi" yang lebih lambat untuk bigram dalam konteks. | |||
| 13-09-2023 | Penurunan Tiba-tiba dalam Kerugian: Akuisisi Sintaks, Transisi Fase, dan Bias Kesederhanaan dalam MLM | ||
| • Mengidentifikasi Struktur Perhatian Sintaksis (SAS) sebagai properti yang muncul secara alami dalam model bahasa bertopeng (MLM) dan perannya dalam perolehan sintaksis. • Menganalisis SAS selama pelatihan dan memanipulasinya untuk mempelajari efek sebab akibat terhadap kemampuan tata bahasa. • SAS diperlukan untuk pengembangan tata bahasa, namun menekannya secara singkat akan meningkatkan kinerja model. | |||
| 18-07-2023 | Apakah Skala Interpretabilitas Analisis Sirkuit? Bukti Kemampuan Pilihan Ganda pada Chinchilla | ||
| • Analisis rangkaian terukur diterapkan pada model bahasa Chinchilla 70B untuk memahami jawaban pertanyaan pilihan ganda. • Atribusi logit, visualisasi pola perhatian, dan patch aktivasi untuk mengidentifikasi dan mengkategorikan kepala perhatian utama. • Mengidentifikasi fitur "Item ke-N dalam enumerasi" di kepala perhatian, meskipun ini hanya sebagian penjelasan. | |||
| 02-02-2023 | Interpretabilitas di Alam Liar: Sirkuit Identifikasi Objek Tidak Langsung di GPT-2 kecil | ||
| • Makalah ini memperkenalkan penjelasan rinci tentang bagaimana GPT-2 kecil melakukan identifikasi objek tidak langsung (IOI) menggunakan sirkuit besar yang melibatkan 28 kepala perhatian yang dikelompokkan ke dalam 7 kelas. • Mereka merekayasa balik tugas IOI di GPT-2 skala kecil dengan menggunakan intervensi dan proyeksi kausal. • Studi ini menunjukkan bahwa interpretasi mekanistik model bahasa besar dapat dilakukan. | |||
| Tanggal | Makalah & Ringkasan | Tag | Tautan |
| 08-03-2022 | Kepala Pembelajaran dan Induksi dalam Konteks | ||
| • Makalah ini mengidentifikasi "kepala induksi" dalam model Transformer, yang memungkinkan pembelajaran dalam konteks dengan mengenali dan menyalin pola secara berurutan. • Menganalisis pola perhatian dan kepala induksi di berbagai lapisan dalam model Transformer yang berbeda. • Menemukan bahwa kepala induksi sangat penting untuk memungkinkan Transformers menggeneralisasi dan melakukan tugas pembelajaran dalam konteks secara efektif. | |||
| 22-12-2021 | Kerangka Matematika untuk Rangkaian Transformator | ||
| • Memperkenalkan kerangka matematis untuk merekayasa balik trafo kecil yang hanya memerlukan perhatian, dengan fokus pada pemahaman kepala perhatian sebagai komponen tambahan yang independen. • Menganalisis trafo lapis nol, satu, dan dua untuk mengidentifikasi peran kepala perhatian dalam pergerakan dan komposisi informasi. • Menemukan "kepala induksi", yang penting untuk pembelajaran dalam konteks pada transformator dua lapis. | |||
| 18-05-2021 | Hipotesis The Heads: Pendekatan Statistik yang Menyatukan Untuk Memahami Perhatian Multi-Headed di BERT | ||
| • Makalah ini mengusulkan metode baru yang disebut "Sparse Attention" yang mengurangi kompleksitas komputasi mekanisme perhatian dengan secara selektif berfokus pada token penting. • Metode ini dievaluasi pada tugas terjemahan mesin dan klasifikasi teks. • Model perhatian yang jarang menghasilkan akurasi yang sebanding dengan perhatian yang padat sekaligus mengurangi biaya komputasi secara signifikan. | |||
| 01-04-2021 | Apakah Kepala Perhatian di BERT Mempelajari Tata Bahasa Konstituensi? | ||
| • Penelitian ini memperkenalkan metode jarak sintaksis untuk menganalisis tata bahasa konstituensi di kepala perhatian BERT dan RoBERTa. • Tata bahasa konstituensi diekstraksi dan dianalisis sebelum dan sesudah penyesuaian pada tugas-tugas SMS dan NLI. • Tugas-tugas NLI meningkatkan kemampuan mendorong tata bahasa konstituensi, sementara tugas-tugas SMS menurunkannya di lapisan atas. | |||
| 27-11-2019 | Apakah Attention Heads di BERT Melacak Ketergantungan Sintaksis? | ||
| • Makalah ini menyelidiki apakah kepala perhatian individu di BERT menangkap ketergantungan sintaksis, menggunakan bobot perhatian untuk mengekstrak hubungan ketergantungan. • Menganalisis kepala perhatian BERT menggunakan bobot perhatian maksimum dan pohon rentang maksimum, membandingkannya dengan pohon Ketergantungan Universal. • Beberapa kepala perhatian melacak ketergantungan sintaksis tertentu lebih baik daripada garis dasar, namun tidak ada kepala yang melakukan penguraian holistik dengan lebih baik secara signifikan. | |||
| 01-11-2019 | Transformer Jarang Secara Adaptif | ||
| • Memperkenalkan transformator jarang adaptif menggunakan alpha-entmax untuk memungkinkan sparsity yang fleksibel dan tergantung pada konteks di kepala perhatian. • Diterapkan pada set data terjemahan mesin untuk menilai interpretabilitas dan keanekaragaman kepala. • Mencapai distribusi perhatian yang beragam dan peningkatan interpretabilitas tanpa mengurangi akurasi. | |||
| 01-08-2019 | Apa yang terlihat Bert? Analisis perhatian Bert | ||
| • Makalah ini memperkenalkan metode untuk menganalisis mekanisme perhatian Bert, mengungkapkan pola yang sejalan dengan struktur linguistik seperti sintaks dan coreference. • Analisis kepala perhatian, identifikasi pola sintaksis dan koreferensial, dan pengembangan classifier probing berbasis perhatian. • Kepala perhatian Bert menangkap informasi sintaksis yang substansial, terutama dalam tugas -tugas seperti mengidentifikasi objek langsung dan coreference. | |||
| 2019-07-01 | Menganalisis Multi-Head Self-Itention: Kepala Khusus melakukan pengangkatan berat, sisanya dapat dipangkas | ||
| • Makalah ini memperkenalkan metode pemangkasan baru untuk perhatian multi-kepala yang secara selektif menghilangkan kepala yang kurang penting tanpa kehilangan kinerja besar. • Analisis kepala perhatian individu, identifikasi peran khusus mereka, dan penerapan metode pemangkasan pada model transformator. • Pemangkasan 38 dari 48 kepala dalam enkoder menyebabkan hanya penurunan skor 0,15 Bleu. | |||
| 01-11-2018 | Analisis representasi enkoder dalam terjemahan mesin berbasis transformator | ||
| • Makalah ini menganalisis representasi internal lapisan encoder transformator, dengan fokus pada informasi sintaksis dan semantik yang dipelajari oleh kepala perhatian diri. • Tugas menyelidik, ekstraksi hubungan ketergantungan, dan skenario pembelajaran transfer. • Lapisan yang lebih rendah menangkap sintaks, sementara lapisan yang lebih tinggi menyandikan lebih banyak informasi semantik. | |||
| 21-03-2016 | Menggabungkan mekanisme penyalinan dalam pembelajaran urutan ke urutan | ||
| • Memperkenalkan mekanisme penyalinan ke dalam model urutan-ke-urutan untuk memungkinkan penyalinan langsung token input, meningkatkan penanganan kata-kata langka. • Diterapkan pada tugas terjemahan dan ringkasan mesin. • Mencapai peningkatan substansial dalam akurasi terjemahan, terutama pada terjemahan kata langka, dibandingkan dengan model urutan-ke-urutan standar. | |||
Template masalah:
Title: [paper's title]
Head: [head name1] (, [head name2] ...)
Published: [arXiv / ACL / ICLR / NIPS / ...]
Summary:
- Innovation:
- Tasks:
- Significant Result:


