AMRICA
1.0.0
AMRICA (AMR Inspector for Cross-lingual Alignments) adalah alat sederhana untuk menyelaraskan dan merepresentasikan AMR secara visual (Banarescu, 2013), baik untuk konteks bilingual maupun untuk perjanjian antar-annotator monolingual. Hal ini didasarkan pada dan memperluas sistem Smatch (Cai, 2012) untuk mengidentifikasi perjanjian antarnotator AMR.
AMRICA juga dapat digunakan untuk memvisualisasikan perataan manual yang telah Anda edit atau kompilasi sendiri (lihat Bendera Umum).
Unduh sumber python dari github.
Kami berasumsi Anda punya pip . Untuk menginstal dependensi (dengan asumsi Anda sudah memiliki dependensi graphviz yang disebutkan di bawah), jalankan saja:
pip install argparse_config networkx==1.8 pygraphviz pynlpl
pygraphviz membutuhkan graphviz agar berfungsi. Di Linux, Anda mungkin harus menginstal graphviz libgraphviz-dev pkg-config . Selain itu, untuk menyiapkan data penyelarasan bilingual Anda memerlukan GIZA++ dan mungkin JAMR.
./disagree.py -i sample.amr -o sample_out_dir/
Perintah ini akan membaca AMR di sample.amr (dipisahkan dengan baris kosong) dan meletakkan visualisasi graphviznya di file .png yang terletak di sample_out_dir/ .
Untuk menghasilkan visualisasi penyelarasan Smatch, kita memerlukan file input AMR dengan setiap kolom ::tok atau ::snt berisi kalimat yang diberi token, kolom ::id dengan ID kalimat, dan kolom ::annotator atau ::anno dengan ID annotator. Anotasi untuk kalimat tertentu dicantumkan secara berurutan, dan anotasi pertama dianggap sebagai standar emas untuk tujuan visualisasi.
Jika Anda hanya ingin memvisualisasikan anotasi tunggal per kalimat tanpa persetujuan antarnotator, Anda dapat menggunakan file AMR dengan hanya satu anotator. Dalam hal ini, bidang anotator dan ID kalimat bersifat opsional. Grafik yang dihasilkan akan berwarna hitam seluruhnya.
Untuk penyelarasan bilingual, kita mulai dengan dua file AMR, satu berisi anotasi target dan satu lagi dengan anotasi sumber dalam urutan yang sama, dengan bidang ::tok dan ::id untuk setiap anotasi. Jika kita menginginkan penyelarasan JAMR untuk kedua sisi, kita menyertakannya dalam bidang ::alignments .
Penyelarasan kalimat harus dalam bentuk dua file .NBEST penyelarasan GIZA++, satu sumber-target dan satu sumber-target. Untuk menghasilkannya, gunakan tanda --nbestalignments di file konfigurasi GIZA++ Anda yang disetel ke jumlah nbest pilihan Anda.
Bendera dapat diatur baik di baris perintah atau di file konfigurasi. Lokasi file konfigurasi dapat diatur dengan -c CONF_FILE pada baris perintah.
Selain --conf_file , ada beberapa tanda lain yang berlaku untuk teks monolingual dan bilingual. --outdir DIR adalah satu-satunya yang diperlukan, dan menentukan direktori tempat kita akan menulis file gambar.
Bendera bersama opsional adalah:
--verbose untuk mencetak kalimat saat kita menyelaraskannya.--no-verbose untuk mengganti pengaturan default verbose.--json FILE.json untuk menulis grafik penyelarasan ke file .json.--num_restarts N untuk menentukan jumlah restart acak yang harus dijalankan Smatch.--align_out FILE.csv untuk menulis perataan ke file.--align_in FILE.csv untuk membaca penyelarasan dari disk alih-alih menjalankan Smatch.--layout untuk mengubah parameter tata letak menjadi graphviz.File .csv perataan memiliki format yang setiap kumpulan pencocokan grafik dipisahkan oleh baris kosong, dan setiap baris dalam kumpulan berisi komentar atau baris yang menunjukkan perataan. Misalnya:
3 它 - 1 it
2 多长 - -1
-1 - 2 take
Bidang yang dipisahkan tab adalah indeks simpul uji (seperti yang diproses oleh Smatch), label simpul uji, indeks simpul emas, dan label simpul emas.
Penyelarasan satu bahasa memerlukan satu tanda tambahan, --infile FILE.amr , dengan FILE.amr disetel ke lokasi file AMR.
Berikut adalah contoh file konfigurasi:
[default]
infile: data/events_amr.txt
outdir: data/events_png/
json: data/events.json
verbose
Dalam penyelarasan bilingual, ada lebih banyak bendera yang dibutuhkan.
--src_amr FILE untuk file AMR anotasi sumber.--tgt_amr FILE untuk file AMR anotasi target.--align_tgt2src FILE.A3.NBEST untuk file GIZA++ .NBEST yang menyelaraskan target-ke-sumber (dengan target sebagai vcb1), dihasilkan dengan --nbestalignments N--align_src2tgt FILE.A3.NBEST untuk file GIZA++ .NBEST yang menyelaraskan sumber-ke-target (dengan sumber sebagai vcb1), dihasilkan dengan --nbestalignments N Sekarang jika --nbestalignments N disetel ke >1, kita harus menentukannya dengan --num_aligned_in_file . Jika kita ingin menghitung bagian atasnya saja --num_align_read juga.
--nbestalignments adalah tanda yang rumit untuk digunakan, karena hanya akan dihasilkan pada proses penyelarasan akhir. Saya sendiri hanya bisa membuatnya berfungsi dengan pengaturan default GIZA++.
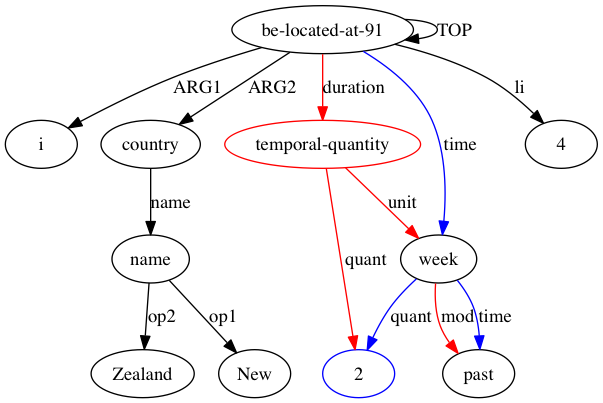
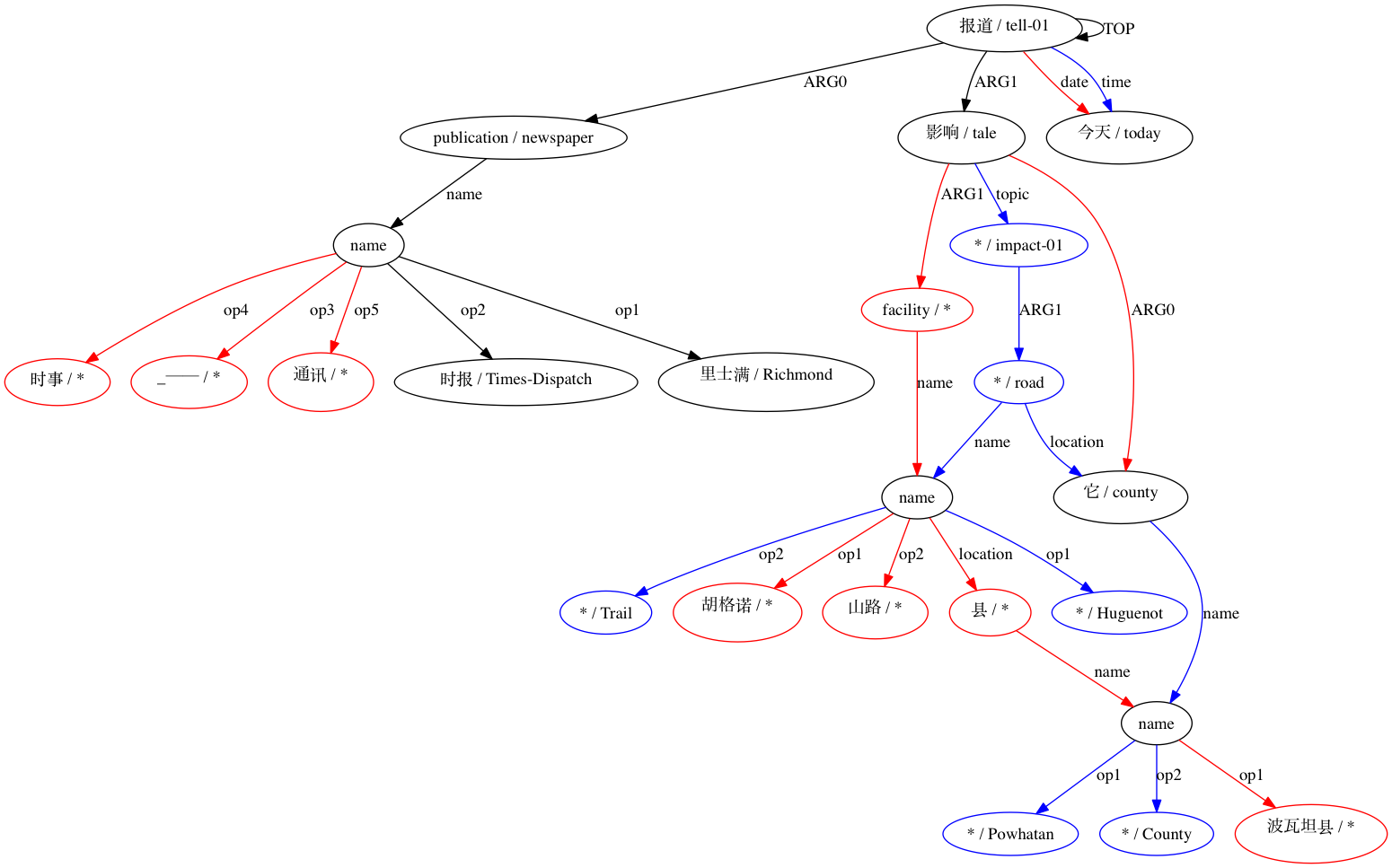
Karena AMRICA adalah variasi dari Smatch, kita harus mulai dengan memahami Smatch. Smatch mencoba mengidentifikasi kecocokan antara node variabel dari dua representasi AMR dari kalimat yang sama untuk mengukur kesepakatan antar anotator. Pencocokan harus dipilih untuk memaksimalkan skor Smatch, yang memberikan poin untuk setiap sisi yang muncul di kedua grafik, yang terbagi dalam tiga kategori. Setiap kategori diilustrasikan dalam anotasi "Tidak butuh waktu lama" berikut ini.
(t / take-10
:ARG0 (i / it)
:ARG1 (l2 / long
:polarity -))
(instance, t, take-10)(ARG0, t, i)(polarity, l2, -)Karena masalah menemukan pencocokan yang memaksimalkan skor Smatch adalah NP-lengkap, Smatch menggunakan algoritma pendakian bukit untuk memperkirakan solusi terbaik. Ini dilakukan dengan mencocokkan setiap node ke node yang berbagi labelnya jika memungkinkan dan mencocokkan node yang tersisa dalam grafik yang lebih kecil (selanjutnya disebut target) secara acak. Smatch kemudian melakukan langkah dengan menemukan tindakan yang akan meningkatkan skor paling banyak dengan mengganti pencocokan dua node target atau memindahkan pencocokan dari node sumbernya ke node sumber yang tidak cocok. Ia mengulangi langkah ini hingga tidak ada langkah yang dapat langsung meningkatkan skor Smatch.
Untuk menghindari local optima, Smatch umumnya restart sebanyak 5 kali.
Untuk rincian teknis tentang cara kerja AMRICA, mungkin akan lebih berguna untuk membaca makalah demo NAACL kami.
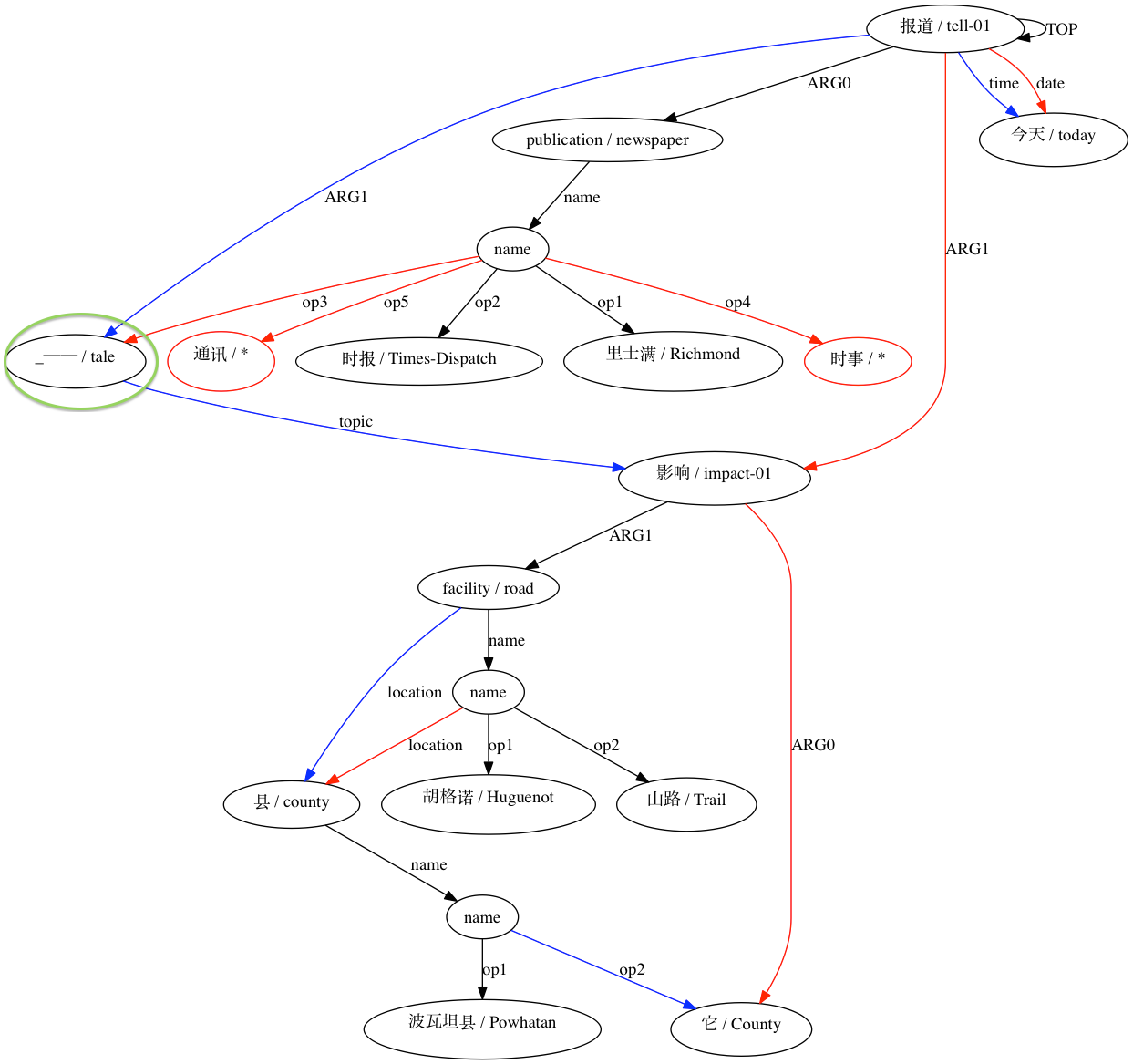
AMRICA memulai dengan mengganti semua node konstan dengan node variabel yang merupakan contoh dari label konstanta. Hal ini diperlukan agar kita dapat menyelaraskan node konstan dan juga variabelnya. Jadi satu-satunya poin yang ditambahkan ke skor AMRICA akan berasal dari pencocokan tepi variabel-variabel dan label instance.
Sementara Smatch mencoba mencocokkan setiap node di grafik yang lebih kecil ke beberapa node di grafik yang lebih besar, AMRICA menghapus pencocokan yang tidak meningkatkan skor Smatch yang dimodifikasi, atau skor AMRICA.
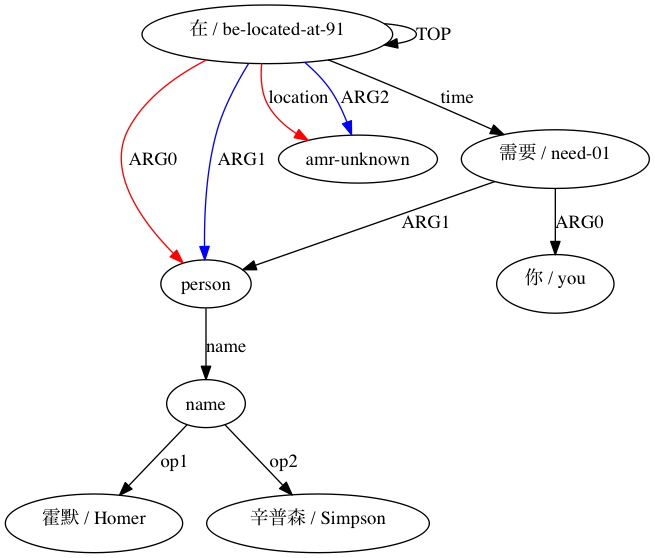
AMRICA kemudian menghasilkan file gambar dari grafik penjajaran graphviz. Jika node atau edge hanya muncul pada data emas, maka warnanya merah. Jika node atau edge tersebut hanya muncul di data pengujian, warnanya biru. Jika simpul atau tepinya memiliki kecocokan pada perataan akhir kita, warnanya hitam.
Di AMRICA, alih-alih menambahkan satu poin untuk setiap label contoh yang sangat cocok, kami menambahkan satu poin berdasarkan skor kemungkinan pada penyelarasan label tersebut. Skor kemungkinan ℓ(aLt,Ls[i]|Lt,Wt,Ls,Ws) dengan kumpulan label target Lt, kumpulan label sumber Ls, kalimat target Wt, kalimat sumber Ws, dan penyelarasan aLt,Ls[i] pemetaan Lt[ i] pada beberapa label Ls[aLt,Ls[i]], dihitung dari kemungkinan yang ditentukan oleh aturan berikut:
Secara umum, AMRICA bilingual tampaknya memerlukan restart yang lebih acak dibandingkan AMRICA monolingual agar dapat bekerja dengan baik. Jumlah restart ini dapat diubah dengan flag --num_restarts .
Kita dapat mengamati sejauh mana penggunaan perkiraan mirip Smatch (di sini, dengan 20 inisialisasi acak) meningkatkan akurasi dalam memilih kemungkinan kecocokan dari data penyelarasan mentah (inisialisasi cerdas). Untuk pasangan yang dinyatakan kompatibel secara struktural oleh (Xue 2014).
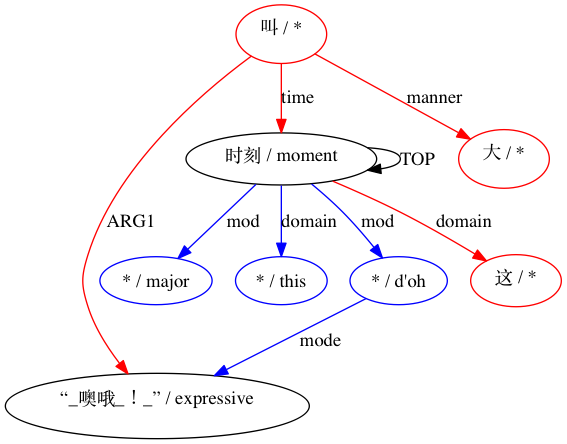
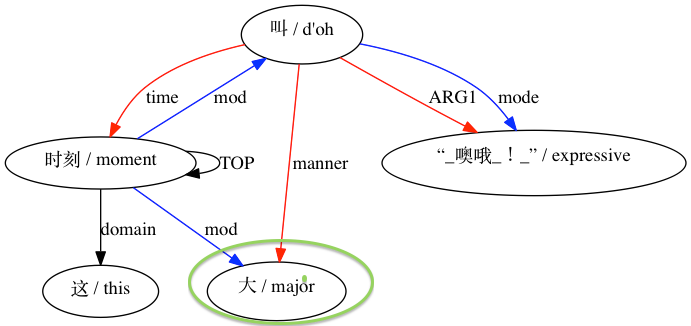
Untuk pasangan yang dianggap tidak kompatibel:
Perangkat lunak ini dikembangkan sebagian dengan dukungan National Science Foundation (USA) di bawah penghargaan 1349902 dan 0530118. University of Edinburgh adalah badan amal, terdaftar di Skotlandia, dengan nomor registrasi SC005336.


