llmjudge
1.0.0
Mengevaluasi LLM dalam skenario terbuka adalah hal yang sulit, terdapat konsensus yang berkembang bahwa tolok ukur yang ada masih kurang dan praktisi berpengalaman lebih memilih untuk menguji model sendiri. Saya menggunakan evaluasi anekdotal dari pengembang dan peneliti yang saya percaya, dengan Chatbot Arena sebagai pelengkap yang sangat baik. Motivasi di balik repo ini adalah metode yang semakin populer dalam menggunakan LLM yang kuat sebagai penilai model. Metode ini telah ada selama beberapa bulan, dengan model seperti JudgeLM, dan yang terbaru adalah MT-Bench.
Anda mungkin atau mungkin belum pernah melihat thread ini. Menurut penulis tweet di Arize AI, penggunaan LLM sebagai juri memerlukan kehati-hatian server, khususnya dalam hal penggunaan evaluasi skor numerik. Tampaknya LLM sangat buruk dalam menangani rentang kontinu, yang menjadi sangat jelas ketika mendorong mereka untuk mengevaluasi X dari 1 hingga 10. Repo ini adalah dokumen percobaan yang hidup yang mencoba memahami dan menangkap garis depan yang tidak rata dari masalah ini. Penelitian terbaru telah menunjukkan korelasi yang kuat antara MT-Bench dan Human Judgment (Arena Elo) , artinya LLM mampu menjadi juri, jadi apa yang terjadi di sini?
Berikut rincian lengkap dan hasilnya.
Karena kendala biaya, awalnya saya akan fokus pada tugas mengeja/salah mengeja yang dijelaskan dalam tweet. Saya sedikit khawatir bahwa X kuantitatif dari tugas ini akan mencemari wawasan eksperimen ini, tapi kita lihat saja nanti. Saya menyambut baik analisis menyeluruh atas fenomena ini, hasil yang saya peroleh tidak perlu diragukan lagi mengingat eksperimen yang terbatas
Saya telah membuat kumpulan data ejaan atau salah ejaan, tidak yakin nama mana yang lebih tepat, dari esai Paul Graham. Pilihan ini sebagian besar karena kenyamanan karena saya telah menggunakan kumpulan data sebelumnya saat menguji tekanan jendela konteks. Saya mengekstrak konteks 3.000 kata dari esai dan memasukkan kesalahan ejaan pada kata-kata acak berdasarkan rasio kesalahan ejaan yang diinginkan. Dalam kodesemu:
misspell_ratio
words = split context into words
misspell_count = calculate number of words to misspell based on ratio
FOR word = sample(words, misspell_count)
IF length(word) > 3
extract random character
ELSE:
add random character
END FOR
Kode lengkap sudah tersedia sebagai buku catatan.
Mengingat kumpulan data yang dihasilkan, kami meminta LLM untuk mengevaluasi jumlah kata yang salah eja dalam suatu konteks menggunakan templat penilaian yang berbeda. Kami menggunakan API berikut
GPT-4: gpt-4-0125-preview
GPT-3.5: gpt-3.5-turbo-1106
pada suhu = 0.
Tes 1. Mari kita konfirmasi bahwa LLM kesulitan menangani rentang numerik dalam pengaturan zero-shot. Kami meminta GPT-3.5 dan GPT-4 dengan templat penilaian numerik, mulai dari skor 0 hingga skor 10.
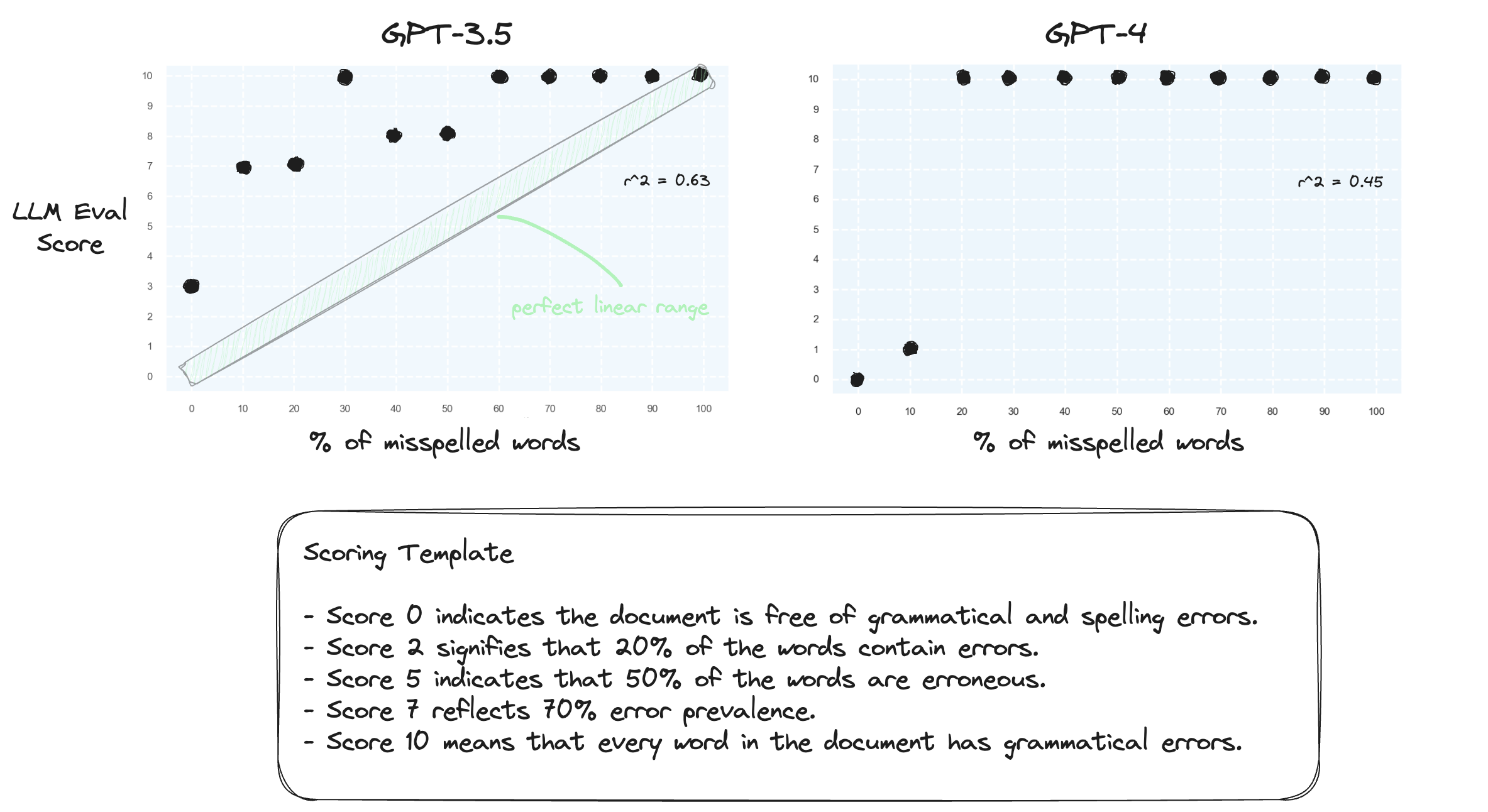
Seperti yang diharapkan, keduanya salah menilai.
Tes 2. Apa yang terjadi jika kita membalikkan rentang penilaian? Sekarang, skor 10 mewakili dokumen yang dieja dengan sempurna.
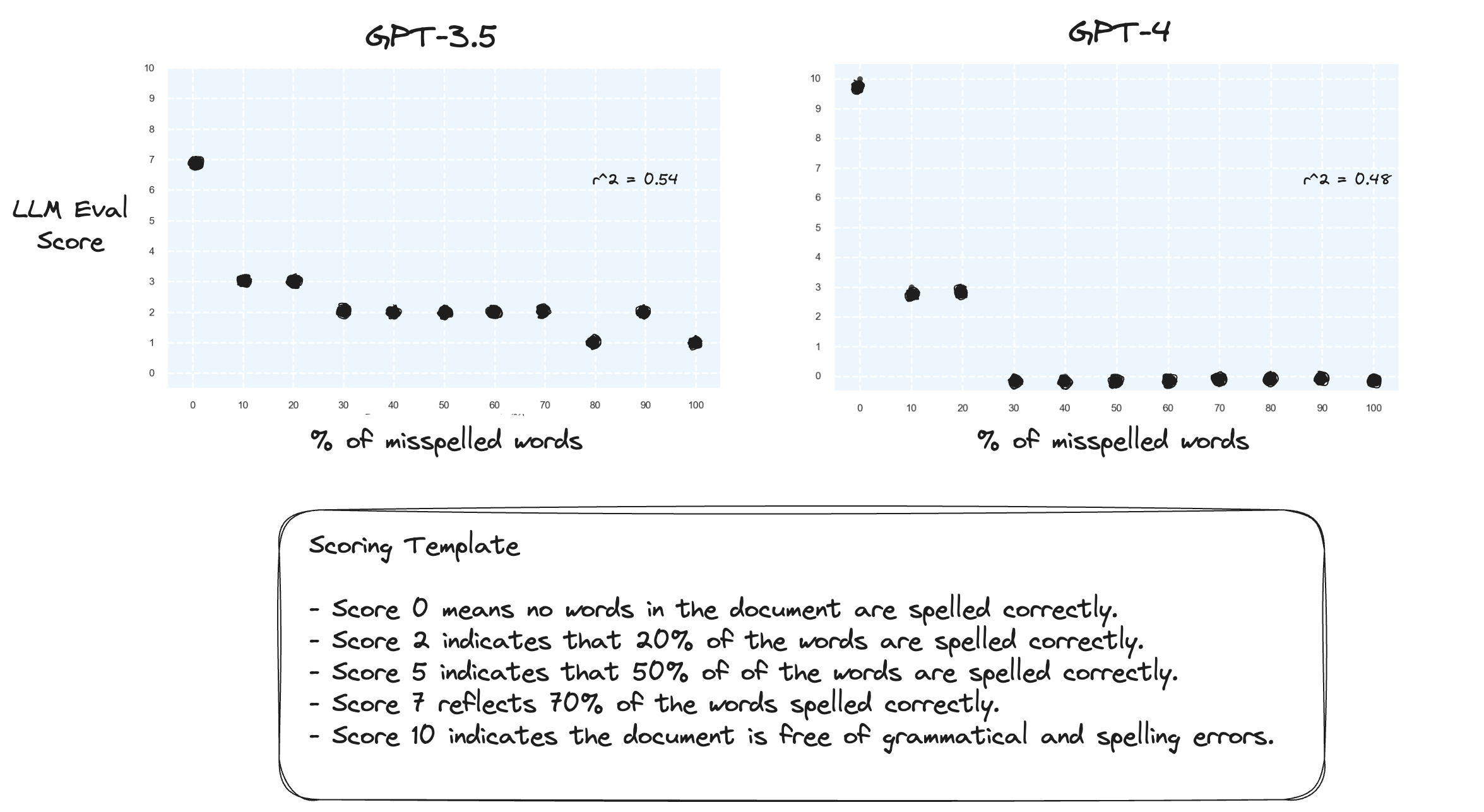
Tampaknya hal ini tidak membawa banyak perbedaan.
Tes 3. Jika kita percaya hipotesis dari Arize, kita mungkin melihat peningkatan jika kita menghindari rubrik penilaian dan malah menggunakan 'nilai berlabel'. Dalam hal ini saya memutuskan untuk turun ke skala penilaian 5 poin.
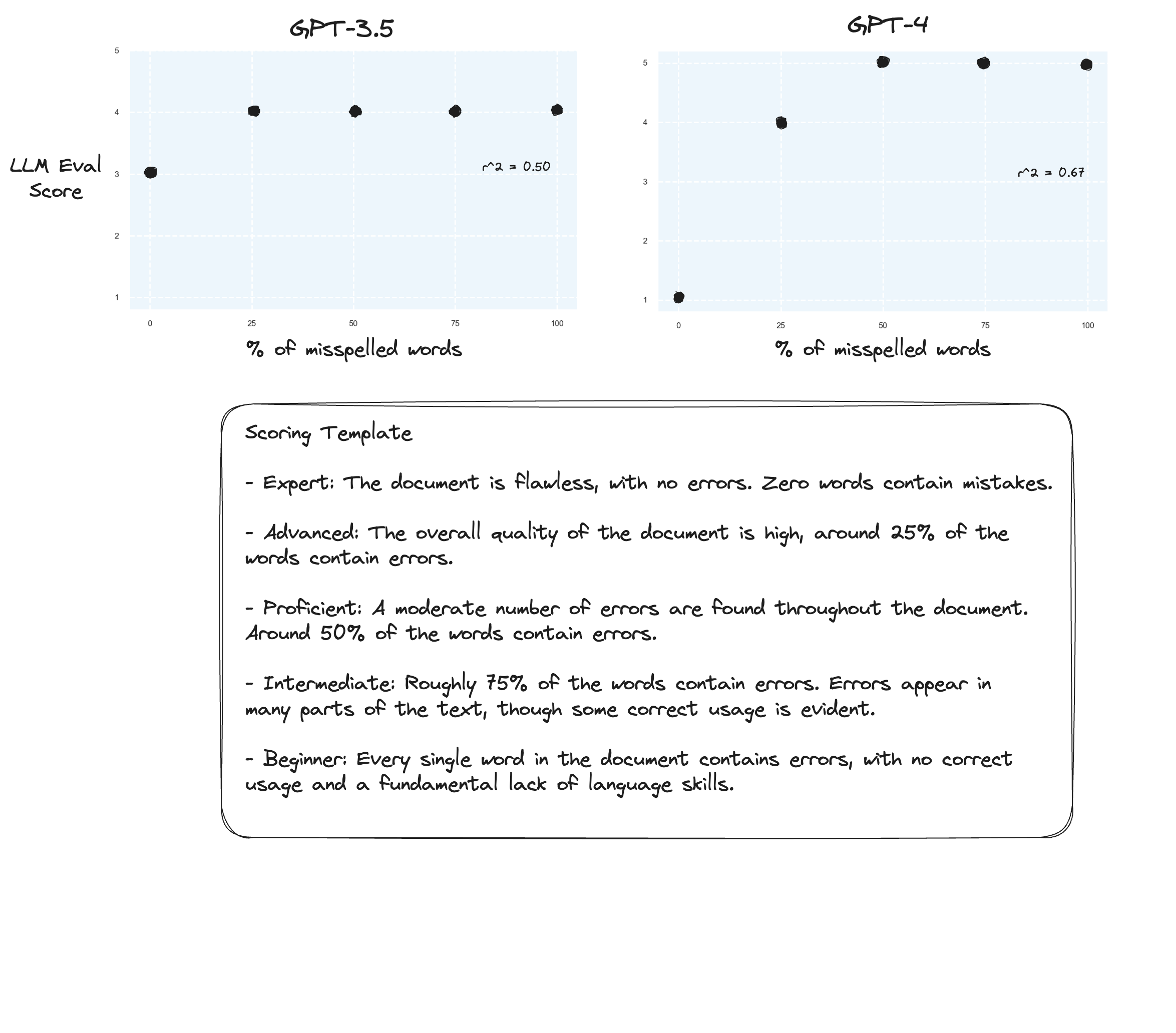
Mungkin sedikit perbaikan? Sulit untuk mengatakan dengan jujur. Saya tidak terkesan.
Tes 4. Bagaimana dengan Rantai Pemikiran zero-shot?

gpt-3.5 berubah menjadi omong kosong untuk dua petunjuknya. Seperti yang diharapkan, gpt-4 mengalami peningkatan ketika diminta untuk berpikir keras. Perhatikan bagaimana sangat ragu-ragu untuk memberikan skor 10.
Tes 5. Seperti yang disarankan oleh penulis Prometheus; memetakan setiap skor dengan penjelasannya sendiri kemungkinan besar akan meningkatkan kemampuan LLM untuk menilai seluruh rentang numerik. Hal ini, dikombinasikan dengan CoT, menghasilkan:

Perbaikan berkelanjutan untuk gpt-4. Masih sangat enggan untuk menetapkan skor batas 0 & 10.
Tes 6. Setelah membaca lebih lanjut tentang MT Bench, saya memutuskan untuk menguji pendekatan alternatif, menggunakan perbandingan berpasangan dan bukan penilaian terisolasi. Sekarang, biasanya ini memerlukan perbandingan O(n * log N), tetapi karena kita sudah mengetahui urutannya, saya pikir kita hanya akan menguji kasus yang paling sulit: membandingkan 0% salah eja vs 10% salah eja, 10% vs 20% dan seterusnya untuk total 10 perbandingan. Perhatikan bahwa saya juga menggunakan CoT zero-shot.
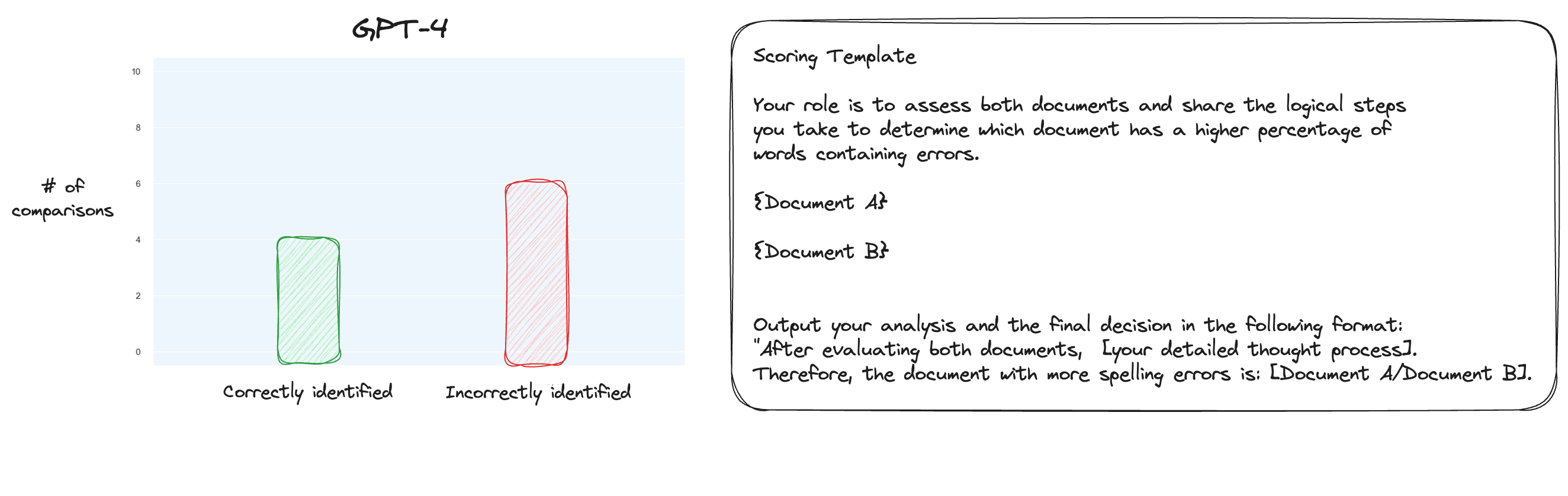
Hipotesis saya adalah bahwa GPT-4 akan unggul dalam skenario yang membandingkan dua teks di dalam jendela konteksnya, tetapi saya salah. Yang mengejutkan saya, hal ini tidak memperbaiki keadaan sama sekali. Tentu saja, ini adalah perbandingan yang paling sulit dari semua perbandingan yang ada, tetapi secara keseluruhan ini masih merupakan tugas yang mudah. Mungkin aspek kuantitatif dari tugas ini pada dasarnya sangat sulit bagi LLM. Hmm, mungkin saya perlu mencari tugas proxy yang lebih baik...
(31/1) Saya telah memeriksa internal MT-Bench, dan sangat terkejut saat mengetahui bahwa mereka hanya meminta GPT-4 untuk menilai keluaran pada skala 1-10. Mereka menyediakan opsi penilaian alternatif seperti perbandingan berpasangan terhadap garis dasar, namun opsi yang direkomendasikan adalah numerik. Perintah penilaiannya juga sangat sederhana:
Harap bertindak sebagai hakim yang tidak memihak dan mengevaluasi kualitas respons yang diberikan oleh asisten AI terhadap pertanyaan pengguna yang ditampilkan di bawah. Evaluasi Anda harus mempertimbangkan faktor-faktor seperti kegunaan, relevansi, keakuratan, kedalaman, kreativitas, dan tingkat detail tanggapan. Mulailah evaluasi Anda dengan memberikan penjelasan singkat. Bersikaplah seobjektif mungkin. Setelah memberikan penjelasan, Anda harus menilai tanggapan dalam skala 1 sampai 10 dengan mengikuti format berikut: [peringkat], misalnya: "Peringkat: 5". [Pertanyaan] {question} [Awal Jawaban Asisten] {answer} [Akhir Jawaban Asisten]
Jika seseorang percaya bahwa hanya ini yang perlu dinilai di MT-Bench, maka saya mulai mempertanyakan penggunaan tugas salah mengeja sebagai tugas proxy...
(2/2) Saya tertarik untuk membuat GPT-4 menilai teks yang salah eja melalui perbandingan berpasangan dibandingkan dengan penilaian terisolasi. Ini adalah salah satu metode penilaian alternatif untuk MT Bench (walaupun mereka merekomendasikan penilaian terisolasi), dan saya rasa metode ini lebih cocok untuk tugas ini. Hasil pemetaan penuh CoT + jelas merupakan peningkatan tetapi menurut saya masih ada pekerjaan yang harus dilakukan. Kelemahan dari penilaian berpasangan tentu saja Anda akan memerlukan lebih banyak panggilan API untuk menetapkan peringkat penuh (dalam praktiknya).


