datalens
1.0.0
Ini adalah eksperimen pribadi yang menggunakan LLM untuk menentukan peringkat data pekerjaan tidak terstruktur berdasarkan kriteria yang ditentukan pengguna. Platform pencarian kerja tradisional mengandalkan sistem penyaringan yang kaku, namun banyak pengguna yang tidak memiliki kriteria konkret seperti itu. Datalens memungkinkan Anda menentukan preferensi Anda dengan cara yang lebih alami dan kemudian menilai setiap lowongan pekerjaan berdasarkan relevansinya.
Beberapa kriteria mungkin lebih penting dibandingkan yang lain, jadi kriteria "harus" diberi bobot dua kali lipat dibandingkan kriteria normal.
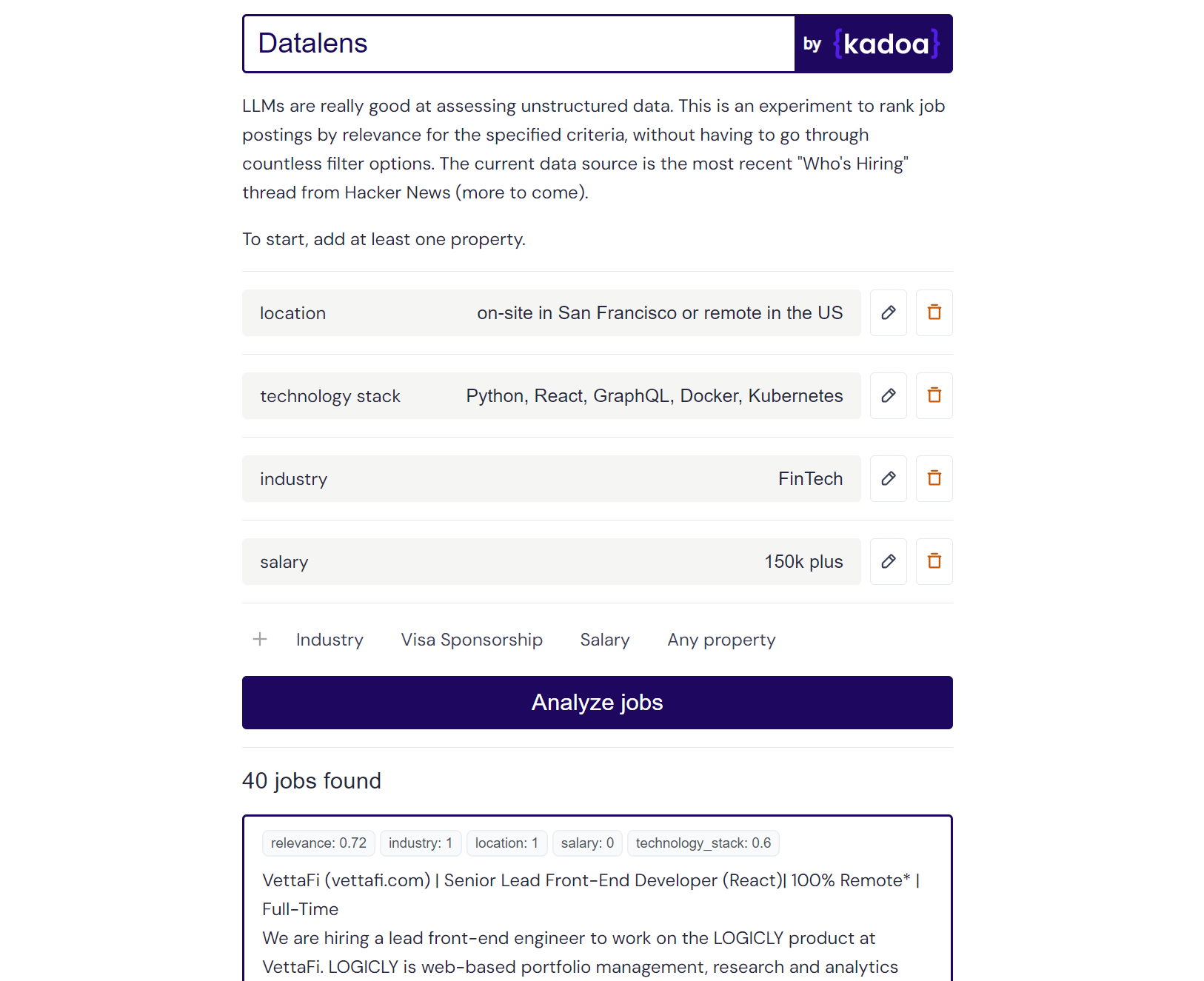
Hasil contoh Claude-2:
Here are the scores for the provided job posting:
{
"location": 1.0,
"technology_stack": 0.8,
"industry": 0.0,
"salary": 0.0
}
Explanation:
- Location is a perfect match (1.0) as the role is in San Francisco which meets the "on-site in San Francisco or remote in the US" criteria.
- Technology stack is a partial match (0.8) as Python, React, and Kubernetes are listed which meet some but not all of the specified technologies.
- Industry is no match (0.0) as the company is in the creative/AI space.
- Salary is no match (0.0) as the posting does not mention the salary range. However, the full compensation is variable. Assigned a score of 0.6.
Anda dapat menambahkan sumber data pekerjaan apa pun yang Anda suka. Saya telah melakukan pra-konfigurasi dengan thread "Siapa yang Mempekerjakan" terbaru dari Hacker News, namun Anda dapat menambahkan sumber Anda sendiri.
Tambahkan sumber pekerjaan baru dengan memperbarui source_config.json. Contoh:
{
"name": "SourceName",
"endpoint": "API_ENDPOINT",
"handler": "handler_function_name",
"headers": {
"x-api-key": "YOUR_API_KEY"
}
}
Saya telah menggunakan alat saya sendiri Kadoa untuk mengambil data pekerjaan dari halaman perusahaan, tetapi Anda dapat menggunakan metode pengikisan tradisional lainnya.
Berikut adalah beberapa titik akhir publik yang siap pakai untuk mendapatkan semua lowongan pekerjaan dari perusahaan-perusahaan ini (diperbarui setiap hari):
{
"name": "Anduril",
"endpoint": "https://services.kadoa.com/jobs/pages/64e74d936addab49669d6319?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "Tesla",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb63f6b91574b2149c0cae?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
},
{
"name": "SpaceX",
"endpoint": "https://services.kadoa.com/jobs/pages/64eb5f1b7350bf774df35f7f?format=json",
"handler": "fetch_kadoa_data",
"headers": {
"x-api-key": "00000000-0000-0000-0000-000000000000"
}
}
Beri tahu saya jika harus menambahkan perusahaan lain. Juga, dengan senang hati memberi Anda akses uji coba ke Kadoa.
Penilaian relevansi berfungsi paling baik dengan gpt-4-0613 yang mengembalikan skor granular antara 0-1. claude-2 juga berfungsi dengan baik jika Anda memiliki akses ke sana. gpt-3.5-turbo-0613 dapat digunakan, tetapi sering kali mengembalikan skor biner 0 atau 1 untuk kriteria, sehingga tidak memiliki nuansa untuk membedakan antara kecocokan sebagian dan penuh.
Model defaultnya adalah gpt-3.5-turbo-0613 karena alasan biaya. Anda dapat beralih dari GPT ke Claude dengan mengganti use_claude dengan use_openai .
Menjalankan skrip ini secara terus-menerus dapat mengakibatkan penggunaan API yang tinggi, jadi harap gunakan secara bertanggung jawab. Saya mencatat biaya untuk setiap panggilan GPT.
Untuk menjalankan aplikasi, Anda memerlukan:
Salin file .env.example dan isi.
Jalankan server Flask:
cd server
cp .env.example .env
pip install -r requirements.txt
py main
Arahkan ke direktori klien dan instal dependensi Node:
cd client
npm install
Jalankan klien Next.js:
cd client
npm run dev


