ShapeGPT
1.0.0

Halaman Proyek • Makalah Arxiv • Demo • FAQ • Kutipan
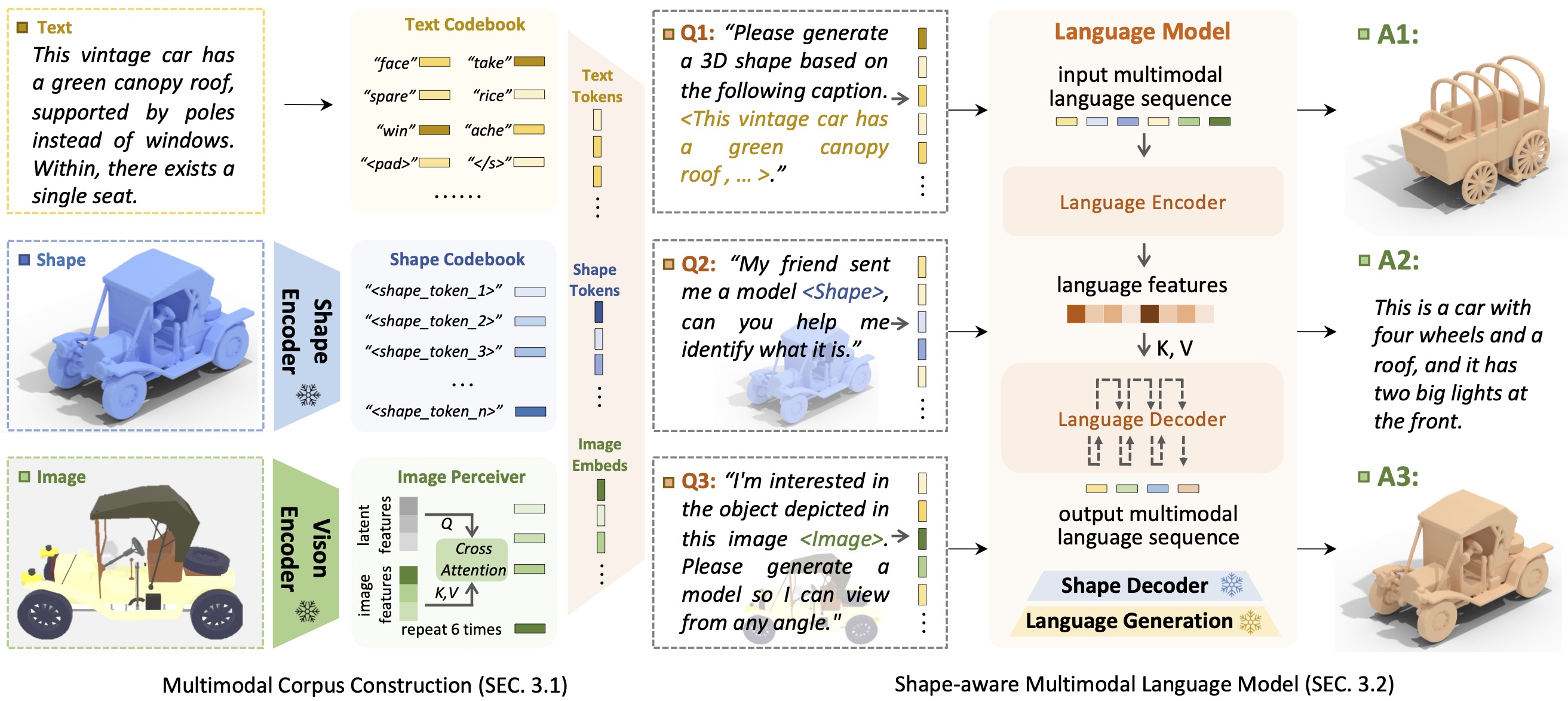
Pengenalan BentukGPTShapeGPT adalah model bahasa multi-modal yang berpusat pada bentuk yang terpadu dan mudah digunakan untuk membangun korpus multi-modal dan mengembangkan model bahasa yang peka terhadap bentuk pada berbagai tugas bentuk .
Munculnya model bahasa besar, yang memungkinkan fleksibilitas melalui pendekatan berbasis instruksi, telah merevolusi banyak tugas generatif tradisional, namun model besar untuk data 3D, khususnya dalam menangani bentuk 3D dengan modalitas lain secara komprehensif, masih kurang dieksplorasi. Dengan mencapai generasi bentuk berbasis instruksi, model bentuk generatif multimodal yang serbaguna dapat memberikan manfaat signifikan di berbagai bidang seperti konstruksi virtual 3D dan desain berbantuan jaringan. Dalam karya ini, kami menghadirkan ShapeGPT, kerangka kerja multi-modal yang menyertakan bentuk untuk memanfaatkan model bahasa terlatih yang kuat untuk menangani berbagai tugas yang relevan dengan bentuk. Secara khusus, ShapeGPT menggunakan kerangka kata-kalimat-paragraf untuk mendiskritisasi bentuk berkelanjutan menjadi kata-kata bentuk, menyusun lebih lanjut kata-kata ini menjadi kalimat bentuk, serta mengintegrasikan bentuk dengan teks instruksional untuk paragraf multi-modal. Untuk mempelajari model bahasa bentuk ini, kami menggunakan skema pelatihan tiga tahap, termasuk representasi bentuk, penyelarasan multimodal, dan pembuatan berbasis instruksi, untuk menyelaraskan buku kode bahasa bentuk dan mempelajari korelasi rumit di antara modalitas ini. Eksperimen ekstensif menunjukkan bahwa ShapeGPT mencapai kinerja yang sebanding di seluruh tugas yang relevan dengan bentuk, termasuk teks-ke-bentuk, bentuk-ke-teks, penyelesaian bentuk, dan pengeditan bentuk.
Jika Anda merasa kode atau makalah kami membantu, harap pertimbangkan untuk mengutip:
@misc { yin2023shapegpt ,
title = { ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model } ,
author = { Fukun Yin and Xin Chen and Chi Zhang and Biao Jiang and Zibo Zhao and Jiayuan Fan and Gang Yu and Taihao Li and Tao Chen } ,
year = { 2023 } ,
eprint = { 2311.17618 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}
Berkat model T5, Motion-GPT, Perceiver-IO, dan SDFusion, sebagian kode kami meminjam dari mereka. Pendekatan kami terinspirasi oleh Unified-IO, Michelangelo, ShapeCrafter, Pix2Vox, dan 3DShape2VecSet.
Kode ini didistribusikan di bawah LISENSI MIT.
Perhatikan bahwa kode kami bergantung pada perpustakaan lain, termasuk PyTorch3D dan PyTorch Lightning, dan menggunakan kumpulan data yang masing-masing memiliki lisensinya masing-masing yang juga harus diikuti.


