SwiftInfer
1.0.0
Streaming-LLM adalah teknik untuk mendukung panjang input tak terbatas untuk inferensi LLM. Ini memanfaatkan Attention Sink untuk mencegah model runtuh saat jendela perhatian bergeser. Karya asli diimplementasikan di PyTorch, kami menawarkan SwiftInfer , implementasi TensorRT untuk menjadikan StreamingLLM lebih berkelas produksi. Implementasi kami dibangun berdasarkan proyek TensorRT-LLM yang baru dirilis.
Kami menggunakan API di TensorRT-LLM untuk membuat model dan menjalankan inferensi. Karena API TensorRT-LLM tidak stabil dan berubah dengan cepat, kami mengikat implementasi kami dengan penerapan 42af740db51d6f11442fd5509ef745a4c043ce51 yang versinya v0.6.0 . Kami dapat mengupgrade repositori ini karena API TensorRT-LLM menjadi lebih stabil.
Jika Anda telah membangun TensorRT-LLM V0.6.0 , jalankan saja:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install .Jika tidak, Anda harus menginstal TensorRT-LLM terlebih dahulu.
Jika menggunakan buruh pelabuhan, Anda dapat mengikuti Instalasi TensorRT-LLM untuk menginstal TensorRT-LLM V0.6.0 .
Dengan menggunakan buruh pelabuhan, Anda dapat menginstal SwiftInfer hanya dengan menjalankan:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
pip install . Jika tidak menggunakan docker, kami menyediakan script untuk menginstal TensorRT-LLM secara otomatis.
Prasyarat
Harap pastikan bahwa Anda telah menginstal paket-paket berikut:
Pastikan versi TensorRT >= 9.1.0 dan toolkit CUDA >= 12.2.
Untuk menginstal tensorrt:
ARCH= $( uname -m )
if [ " $ARCH " = " arm64 " ] ; then ARCH= " aarch64 " ; fi
if [ " $ARCH " = " amd64 " ] ; then ARCH= " x86_64 " ; fi
if [ " $ARCH " = " aarch64 " ] ; then OS= " ubuntu-22.04 " ; else OS= " linux " ; fi
wget https://developer.nvidia.com/downloads/compute/machine-learning/tensorrt/secure/9.1.0/tars/tensorrt-9.1.0.4. $OS . $ARCH -gnu.cuda-12.2.tar.gz
tar xzvf tensorrt-9.1.0.4.linux.x86_64-gnu.cuda-12.2.tar.gz
PY_VERSION= $( python -c ' import sys; print(".".join(map(str, sys.version_info[0:2]))) ' )
PARSED_PY_VERSION= $( echo " ${PY_VERSION // . / } " )
pip install TensorRT-9.1.0.4/python/tensorrt- * -cp ${PARSED_PY_VERSION} - * .whl
export TRT_ROOT= $( realpath TensorRT-9.1.0.4 )Untuk mengunduh nccl, ikuti halaman unduh NCCL.
Untuk mengunduh cudnn, ikuti halaman unduh cuDNN.
Perintah
Sebelum menjalankan perintah berikut, pastikan Anda telah mengatur nvcc dengan benar. Untuk memeriksanya, jalankan:
nvcc --versionUntuk menginstal TensorRT-LLM dan SwiftInfer, jalankan:
git clone https://github.com/hpcaitech/SwiftInfer.git
cd SwiftInfer
TRT_ROOT=xxx NCCL_ROOT=xxx CUDNN_ROOT=xxx pip install . Untuk menjalankan contoh Llama, Anda harus terlebih dahulu mengkloning repositori Hugging Face untuk model meta-llama/Llama-2-7b-chat-hf atau varian berbasis Llama lainnya seperti lmsys/vicuna-7b-v1.3. Kemudian, Anda dapat menjalankan perintah berikut untuk membuat mesin TensorRT. Anda perlu mengganti <model-dir> dengan jalur sebenarnya ke model Llama.
cd examples/llama
python build.py
--model_dir < model-dir >
--dtype float16
--enable_context_fmha
--use_gemm_plugin float16
--max_input_len 2048
--max_output_len 1024
--output_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--max_batch_size 1Selanjutnya, Anda perlu mengunduh data MT-Bench yang disediakan oleh LMSYS-FastChat.
mkdir mt_bench_data
wget -P ./mt_bench_data https://raw.githubusercontent.com/lm-sys/FastChat/main/fastchat/llm_judge/data/mt_bench/question.jsonlTerakhir, Anda siap menjalankan contoh Llama dengan perintah berikut.
❗️❗️❗️ Sebelumnya, mohon diperhatikan bahwa:
only_n_first digunakan untuk mengontrol jumlah sampel yang akan dievaluasi. Jika Anda ingin mengevaluasi semua sampel, harap hapus argumen ini. python ../run_conversation.py
--max_input_length 2048
--max_output_len 1024
--tokenizer_dir < model-dir >
--engine_dir ./output/7B-streaming-8k-1k-4-2000/trt_engines/fp16/1-gpu/
--input_file ./mt_bench_data/question.jsonl
--streaming_llm_start_size 4
--only_n_first 5Anda akan melihat generasinya sebagai berikut:
Kami telah membandingkan implementasi Streaming-LLM kami dengan versi PyTorch asli. Perintah benchmark untuk implementasi kita diberikan di bagian Jalankan Llama Contoh sedangkan untuk implementasi PyTorch asli diberikan di folder torch_streamingllm. Perangkat keras yang digunakan tercantum di bawah ini:
Hasilnya (20 putaran percakapan) adalah:
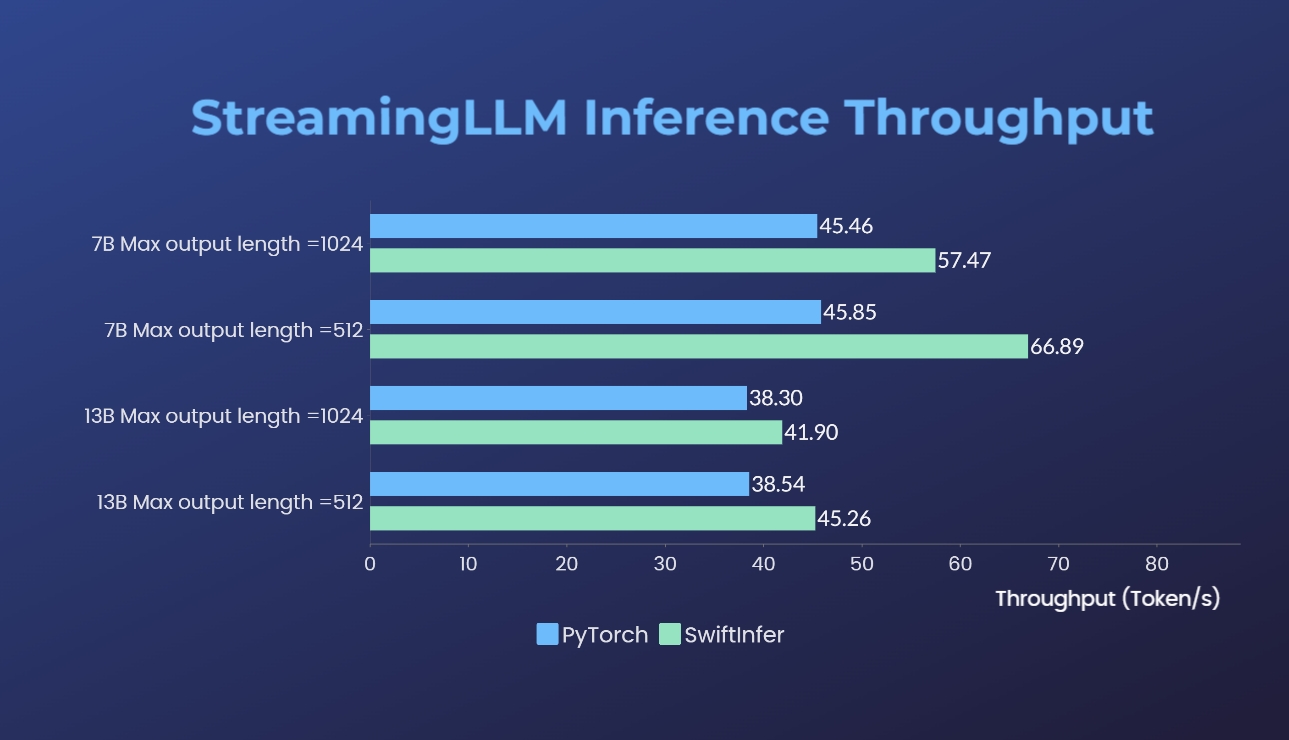
Kami masih berupaya meningkatkan performa lebih lanjut dan beradaptasi dengan API TensorRT V0.7.1. Kami juga melihat bahwa TensorRT-LLM telah mengintegrasikan StreamingLLM dalam contohnya, tetapi tampaknya TensorRT-LLM lebih cocok untuk pembuatan teks tunggal dibandingkan percakapan multi-putaran.
Karya ini terinspirasi oleh Streaming-LLM agar dapat digunakan untuk produksi. Sepanjang pengembangan, kami telah mereferensikan materi berikut dan kami ingin mengapresiasi upaya dan kontribusinya terhadap komunitas sumber terbuka dan akademisi.
Jika menurut Anda StreamingLLM dan implementasi TensorRT kami berguna, silakan mengutip repositori kami dan karya asli yang diusulkan oleh Xiao dkk. dari MIT Han Lab.
# our repository
# NOTE: the listed authors have equal contribution
@misc { streamingllmtrt2023 ,
title = { SwiftInfer } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/hpcaitech/SwiftInfer} } ,
}
# Xiao's original paper
@article { xiao2023streamingllm ,
title = { Efficient Streaming Language Models with Attention Sinks } ,
author = { Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike } ,
journal = { arXiv } ,
year = { 2023 }
}
# TensorRT-LLM repo
# as TensorRT-LLM team does not provide a bibtex
# please let us know if there is any change needed
@misc { trtllm2023 ,
title = { TensorRT-LLM } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub repository } ,
howpublished = { url{https://github.com/NVIDIA/TensorRT-LLM} } ,
}

