paxml
paxml release 1.4.0
Pax adalah kerangka kerja untuk mengonfigurasi dan menjalankan eksperimen pembelajaran mesin di atas Jax.
Kami merujuk ke halaman ini untuk dokumentasi yang lebih lengkap tentang memulai proyek Cloud TPU. Perintah berikut cukup untuk membuat VM Cloud TPU dengan 8 inti dari mesin perusahaan.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-8
export TPU_NAME=paxml
# create a TPU VM
gcloud compute tpus tpu-vm create $TPU_NAME
--zone= $ZONE --version= $VERSION
--project= $PROJECT
--accelerator-type= $ACCELERATOR Jika Anda menggunakan irisan TPU Pod, silakan merujuk ke panduan ini. Jalankan semua perintah dari mesin lokal menggunakan gcloud dengan opsi --worker=all :
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONE
--worker=all --command= " <commmands> "Bagian mulai cepat berikut mengasumsikan Anda berjalan di TPU host tunggal, sehingga Anda dapat melakukan ssh ke VM dan menjalankan perintah di sana.
gcloud compute tpus tpu-vm ssh $TPU_NAME --zone= $ZONESetelah melakukan ssh-ing pada VM, Anda dapat menginstal rilis stabil paxml dari PyPI, atau versi dev dari github.
Untuk menginstal rilis stabil dari PyPI (https://pypi.org/project/paxml/):
python3 -m pip install -U pip
python3 -m pip install paxml jax[tpu]
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html Jika Anda mengalami masalah dengan dependensi transitif dan Anda menggunakan lingkungan VM Cloud TPU asli, buka cabang rilis yang sesuai rX.YZ dan unduh paxml/pip_package/requirements.txt . File ini mencakup versi persis dari semua dependensi transitif yang diperlukan di lingkungan VM Cloud TPU asli, tempat kami membuat/menguji rilis yang sesuai.
git clone -b rX.Y.Z https://github.com/google/paxml
pip install --no-deps -r paxml/paxml/pip_package/requirements.txtUntuk menginstal versi dev dari github, dan untuk kemudahan mengedit kode:
# install the dev version of praxis first
git clone https://github.com/google/praxis
pip install -e praxis
git clone https://github.com/google/paxml
pip install -e paxml
pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html # example model using pjit (SPMD)
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudSpmd2BLimitSteps
--job_log_dir=gs:// < your-bucket >
# example model using pmap
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.lm_cloud.LmCloudTransformerAdamLimitSteps
--job_log_dir=gs:// < your-bucket >
--pmap_use_tensorstore=TrueSilakan kunjungi folder dokumen kami untuk dokumentasi dan tutorial Notebook Jupyter. Silakan lihat bagian berikut untuk petunjuk menjalankan Jupyter Notebooks di VM Cloud TPU.
Anda dapat menjalankan contoh buku catatan di VM TPU tempat Anda baru saja menginstal paxml. ####Langkah-langkah untuk mengaktifkan notebook di v4-8
ssh di TPU VM dengan penerusan port gcloud compute tpus tpu-vm ssh $TPU_NAME --project=$PROJECT_NAME --zone=$ZONE --ssh-flag="-4 -L 8080:localhost:8080"
instal notebook jupyter di TPU vm dan turunkan markupsafe
pip install notebook
pip install markupsafe==2.0.1
ekspor jalur jupyter export PATH=/home/$USER/.local/bin:$PATH
scp contoh buku catatan ke VM TPU Anda gcloud compute tpus tpu-vm scp $TPU_NAME:<path inside TPU> <local path of the notebooks> --zone=$ZONE --project=$PROJECT
mulai jupyter notebook dari TPU VM dan catat token yang dihasilkan oleh jupyter notebook jupyter notebook --no-browser --port=8080
lalu di browser lokal Anda, buka: http://localhost:8080/ dan masukkan token yang disediakan
Catatan: Jika Anda perlu mulai menggunakan notebook kedua saat notebook pertama masih menempati TPU, Anda dapat menjalankan pkill -9 python3 untuk mengosongkan TPU.
Catatan: NVIDIA telah merilis versi terbaru Pax dengan dukungan H100 FP8 dan peningkatan kinerja GPU yang luas. Silakan kunjungi repositori NVIDIA Rosetta untuk detail lebih lanjut dan petunjuk penggunaan.
Alur kerja Profile Guided Latency Estimator (PGLE) mengukur waktu berjalan sebenarnya dari komputasi dan kolektif, informasi profil dimasukkan kembali ke kompiler XLA untuk keputusan penjadwalan yang lebih baik.
Penaksir Latensi Terpandu Profil dapat digunakan secara manual atau otomatis. Dalam mode otomatis JAX akan mengumpulkan informasi profil dan mengkompilasi ulang modul dalam sekali proses. Saat dalam mode manual Anda perlu menjalankan tugas dua kali, pertama kali mengumpulkan dan menyimpan profil dan yang kedua mengkompilasi dan menjalankan dengan data yang disediakan.
PGLE otomatis dapat diaktifkan dengan mengatur variabel lingkungan berikut:
XLA_FLAGS="--xla_gpu_enable_latency_hiding_scheduler=true"
JAX_ENABLE_PGLE=true
JAX_PGLE_PROFILING_RUNS=3
JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY=True
Optional JAX_PGLE_AGGREGATION_PERCENTILE=85
Atau di JAX ini bisa diset sebagai berikut:
import jax
from jax._src import config
with config.enable_pgle(True), config.pgle_profiling_runs(1):
# Run with the profiler collecting performance information.
train_step()
# Automatically re-compile with PGLE profile results
train_step()
...
Anda dapat mengontrol jumlah tayangan ulang yang digunakan untuk mengumpulkan data profil dengan mengubah JAX_PGLE_PROFILING_RUNS . Meningkatkan parameter ini akan menghasilkan informasi profil yang lebih baik, namun juga akan meningkatkan jumlah langkah pelatihan yang tidak dioptimalkan.
Parameter JAX_REMOVE_CUSTOM_PARTITIONING_PTR_FROM_CACHE_KEY memungkinkan untuk menggunakan panggilan balik host dengan PGLE otomatis.
Mengurangi parameter JAX_PGLE_AGGREGATION_PERCENTILE mungkin membantu jika kinerja antar langkah terlalu berisik untuk menyaring tindakan yang tidak relevan.
Perhatian: PGLE Otomatis tidak berfungsi untuk modul yang telah dikompilasi sebelumnya. Karena JAX perlu mengkompilasi ulang modul selama eksekusi, PGLE otomatis tidak akan berfungsi baik untuk AoT maupun untuk kasus berikut:
import jax
from jax._src import config
train_step_compiled = train_step().lower().compile()
with config.enable_pgle(True), config.pgle_profiling_runs(1):
train_step_compiled()
# No effect since module was pre-compiled.
train_step_compiled()
Jika Anda masih ingin menggunakan Penaksir Latensi Terpandu Profil manual, alur kerja di XLA/GPU adalah:
Anda dapat melakukannya dengan mengatur:
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true " import os
from etils import epath
import jax
from jax . experimental import profiler as exp_profiler
# Define your profile directory
profile_dir = 'gs://my_bucket/profile'
jax . profiler . start_trace ( profile_dir )
# run your workflow
# for i in range(10):
# train_step()
# Stop trace
jax . profiler . stop_trace ()
profile_dir = epath . Path ( profile_dir )
directories = profile_dir . glob ( 'plugins/profile/*/' )
directories = [ d for d in directories if d . is_dir ()]
rundir = directories [ - 1 ]
logging . info ( 'rundir: %s' , rundir )
# Post process the profile
fdo_profile = exp_profiler . get_profiled_instructions_proto ( os . fspath ( rundir ))
# Save the profile proto to a file.
dump_dir = rundir / 'profile.pb'
dump_dir . parent . mkdir ( parents = True , exist_ok = True )
dump_dir . write_bytes ( fdo_profile ) Setelah langkah ini, Anda akan mendapatkan file profile.pb di bawah rundir yang dicetak dalam kode.
Anda harus meneruskan file profile.pb ke flag --xla_gpu_pgle_profile_file_or_directory_path .
export XLA_FLAGS= " --xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_pgle_profile_file_or_directory_path=/path/to/profile/profile.pb " Untuk mengaktifkan logging di XLA dan memeriksa apakah profilnya bagus, atur level logging untuk menyertakan INFO :
export TF_CPP_MIN_LOG_LEVEL=0Jalankan alur kerja sebenarnya, jika Anda menemukan logging ini di log yang sedang berjalan, itu berarti profiler digunakan dalam penjadwal penyembunyian latensi:
2023-07-21 16:09:43.551600: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:478] Using PGLE profile from /tmp/profile/plugins/profile/2023_07_20_18_29_30/profile.pb
2023-07-21 16:09:43.551741: I external/xla/xla/service/gpu/gpu_hlo_schedule.cc:573] Found profile, using profile guided latency estimator
Pax berjalan di Jax, Anda dapat menemukan detail tentang menjalankan tugas Jax di Cloud TPU di sini, Anda juga dapat menemukan detail tentang menjalankan tugas Jax di pod Cloud TPU di sini
Jika Anda mengalami kesalahan ketergantungan, lihat file requirements.txt di cabang yang sesuai dengan rilis stabil yang Anda instal. Misalnya, untuk rilis stabil 0.4.0 gunakan cabang r0.4.0 dan lihat persyaratan.txt untuk versi persis dependensi yang digunakan untuk rilis stabil.
Berikut adalah beberapa contoh konvergensi yang dijalankan pada dataset c4.
Anda dapat menjalankan model params 1B pada dataset c4 di TPU v4-8 menggunakan konfigurasi C4Spmd1BAdam4Replicas dari c4.py sebagai berikut:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd1BAdam4Replicas
--job_log_dir=gs:// < your-bucket > Anda dapat mengamati kurva kerugian dan grafik log perplexity sebagai berikut:
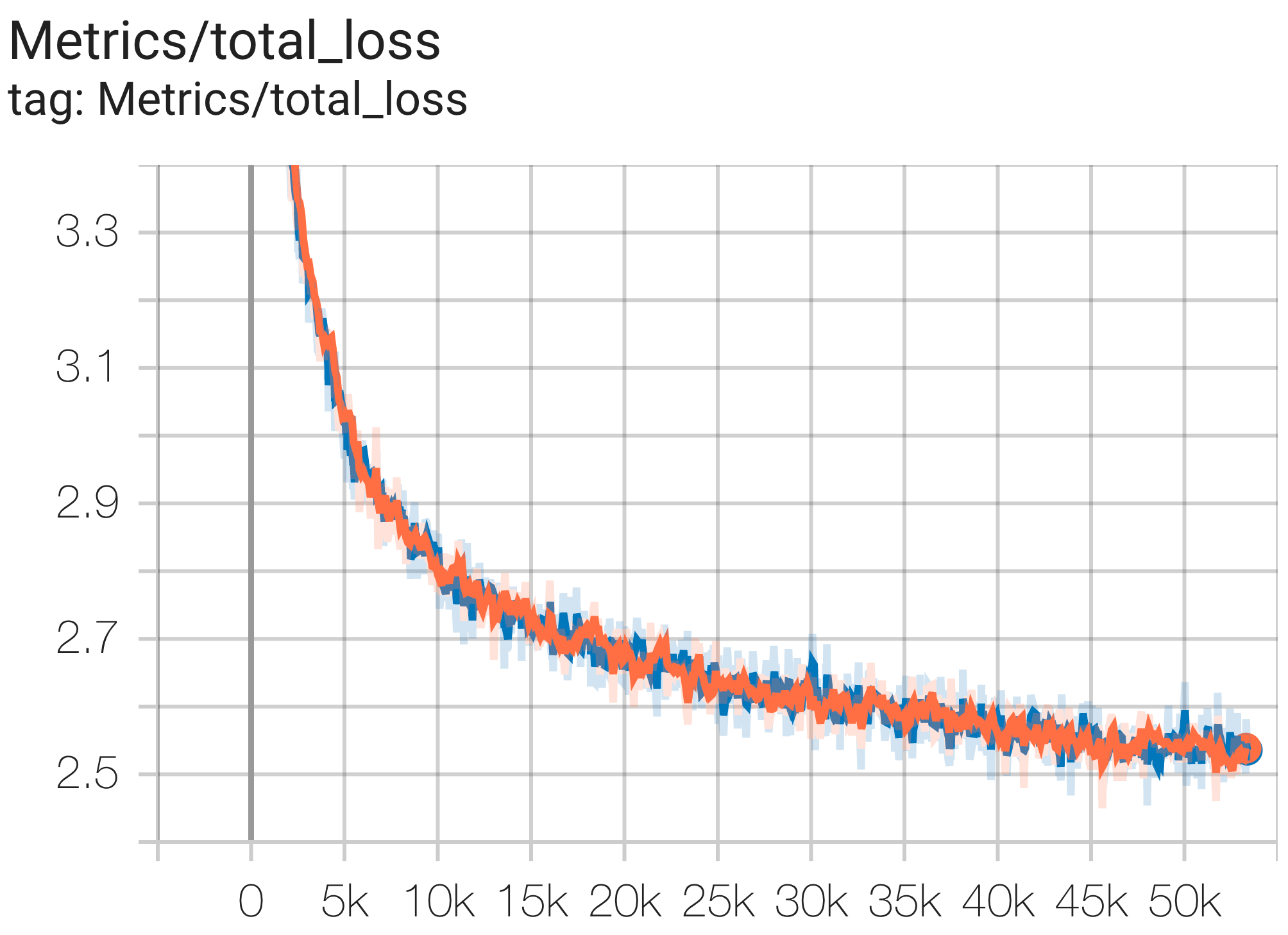
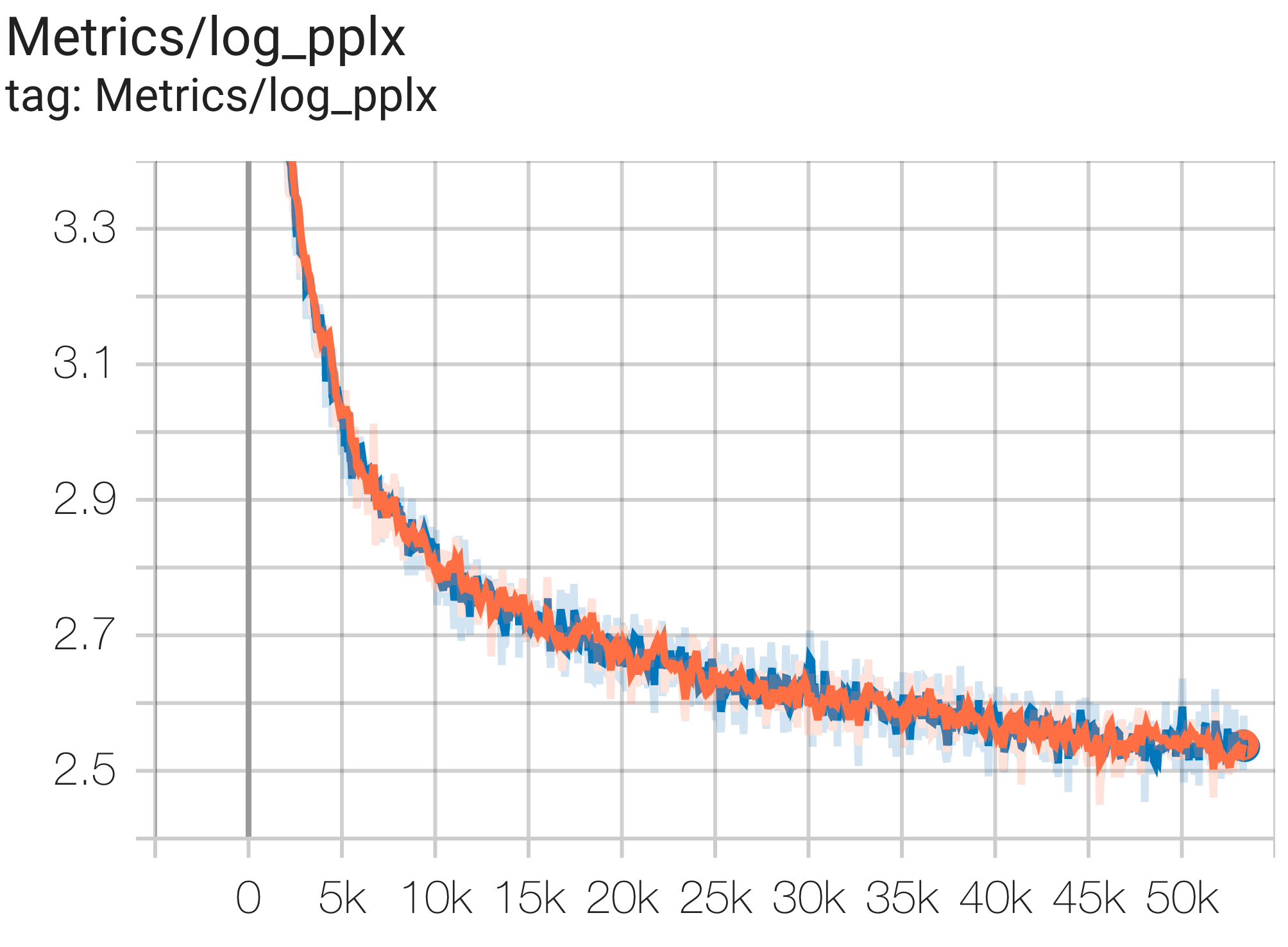
Anda dapat menjalankan model params 16B pada dataset c4 di TPU v4-64 menggunakan konfigurasi C4Spmd16BAdam32Replicas dari c4.py sebagai berikut:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4Spmd16BAdam32Replicas
--job_log_dir=gs:// < your-bucket > Anda dapat mengamati kurva kerugian dan grafik log perplexity sebagai berikut:
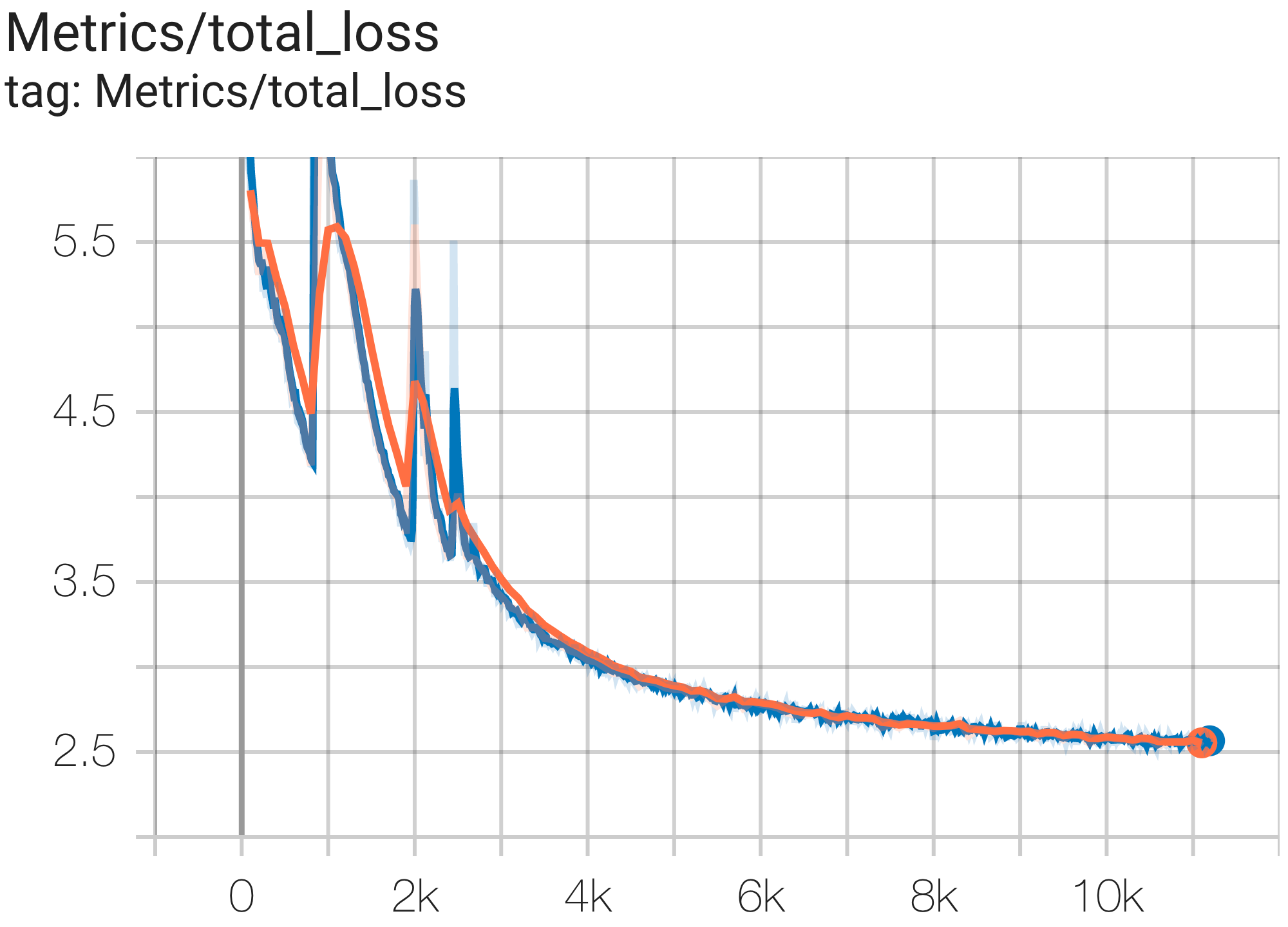
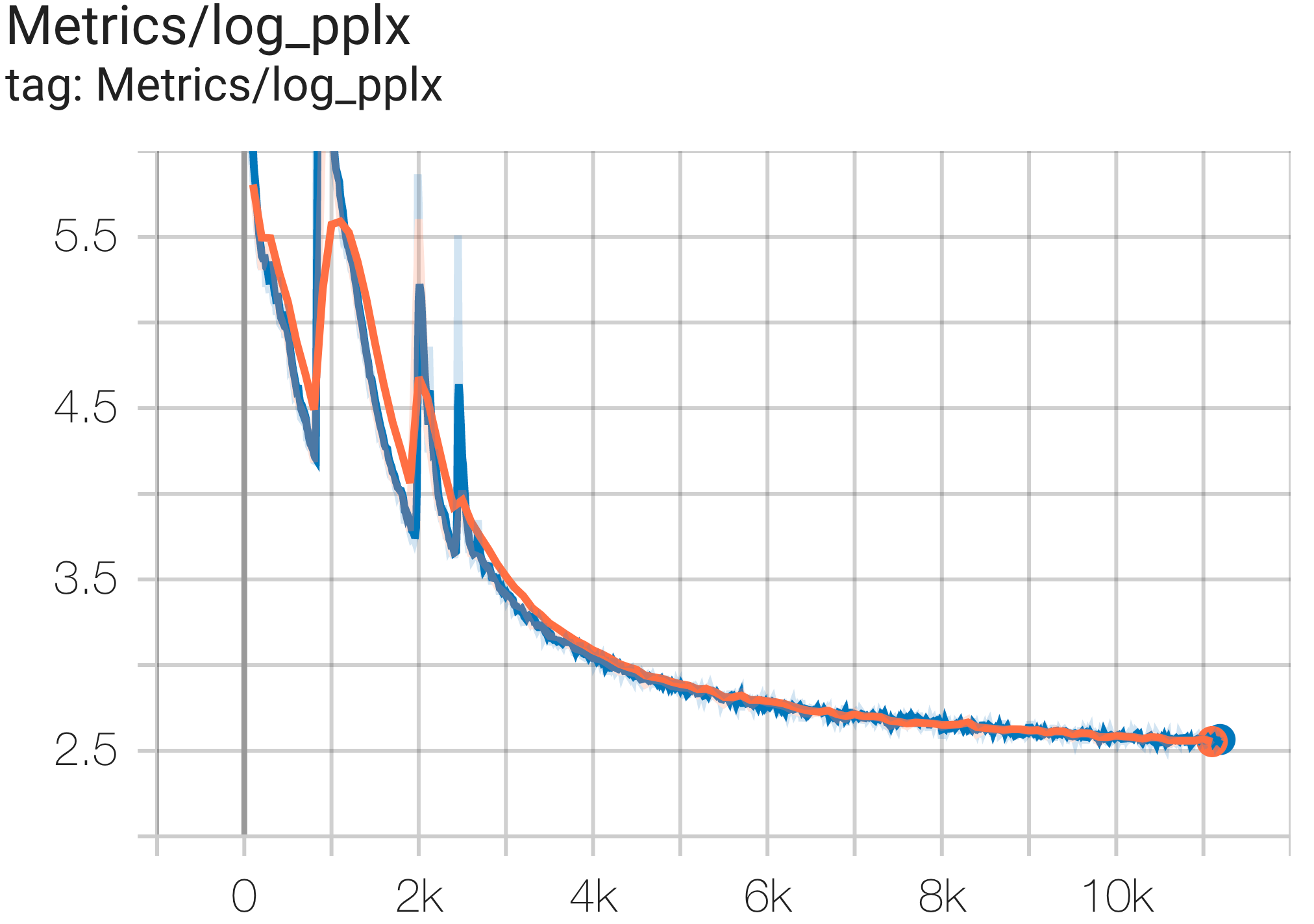
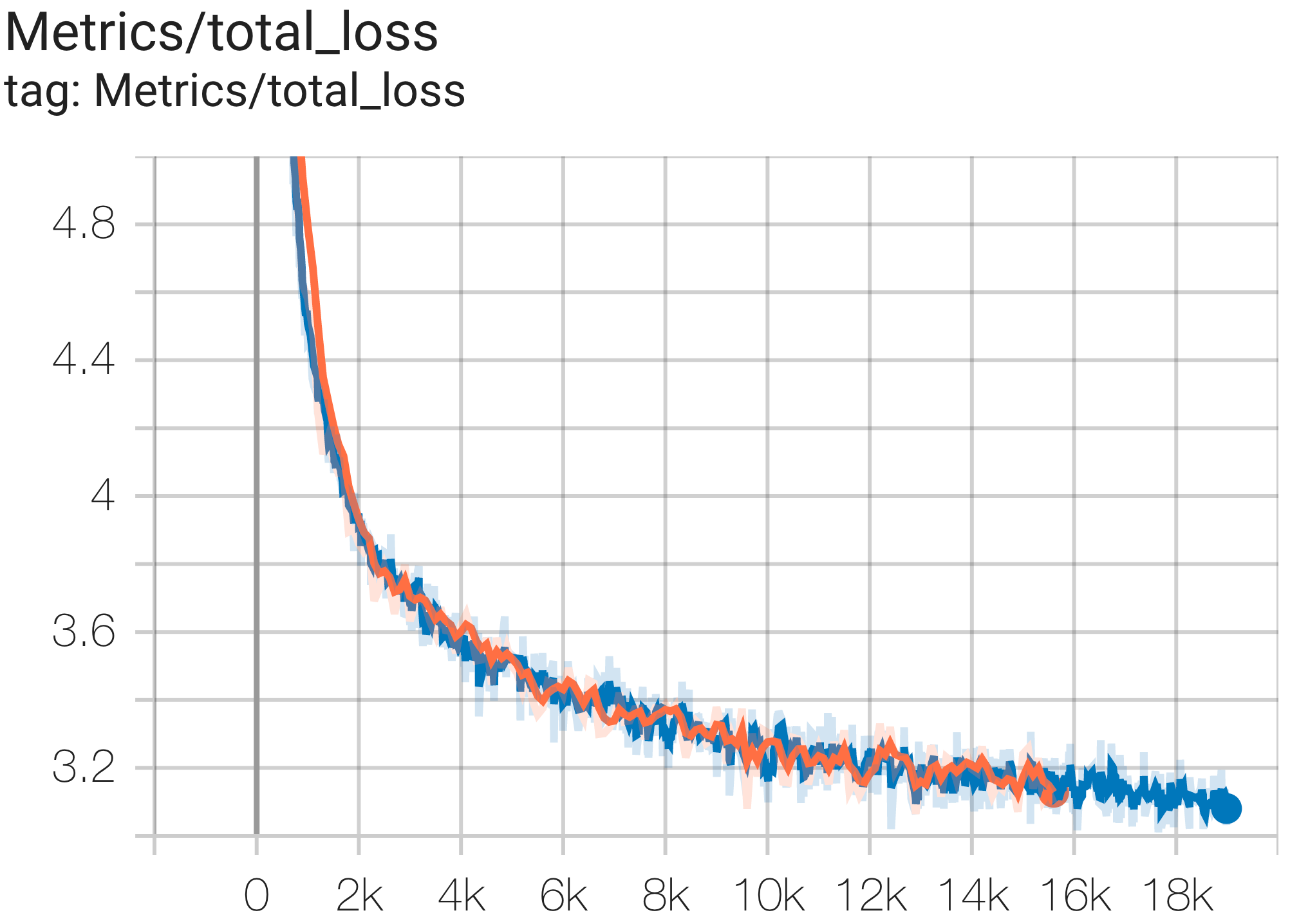
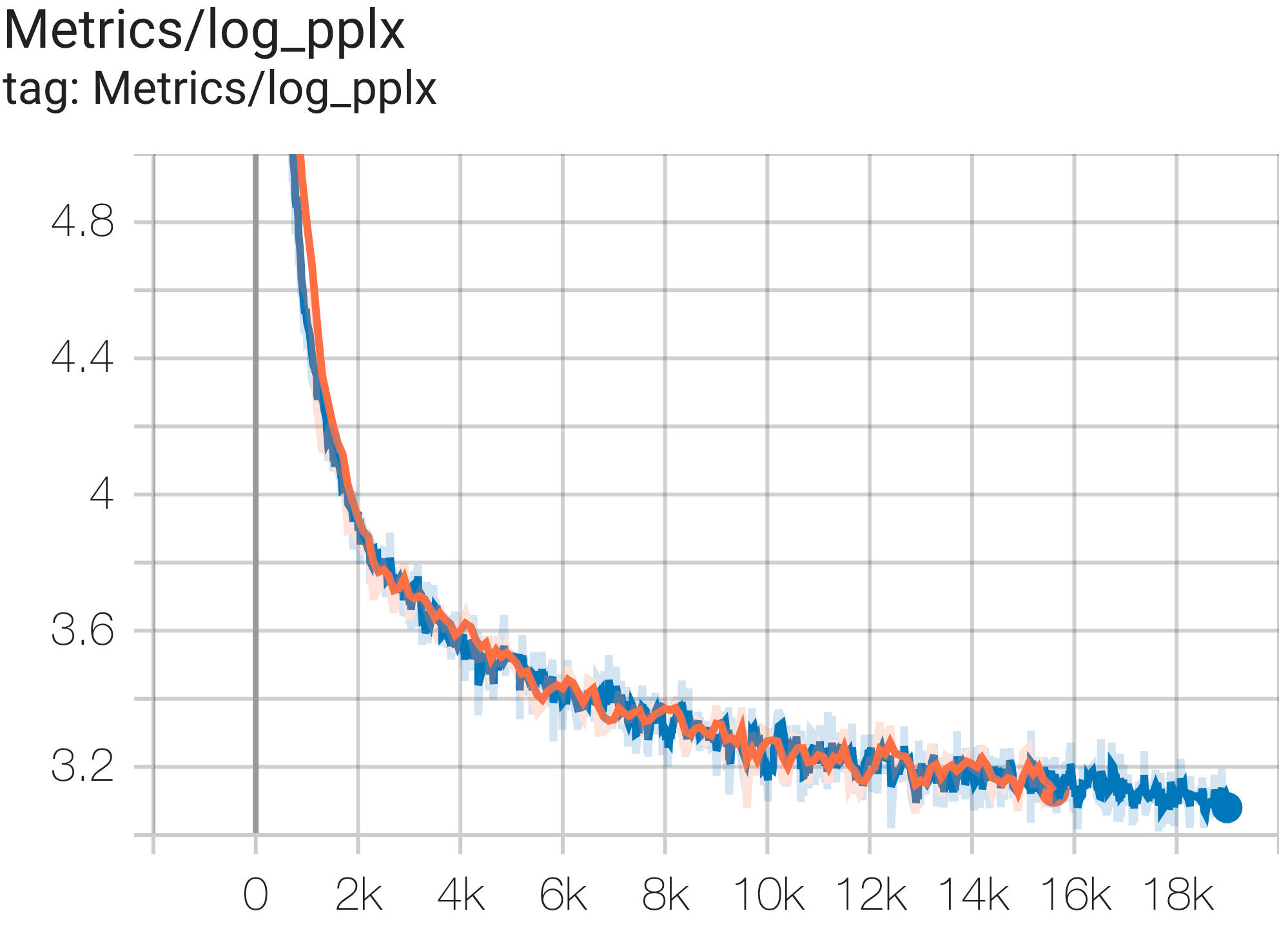
Anda dapat menjalankan model GPT3-XL pada dataset c4 di TPU v4-128 menggunakan konfigurasi C4SpmdPipelineGpt3SmallAdam64Replicas dari c4.py sebagai berikut:
python3 .local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4.C4SpmdPipelineGpt3SmallAdam64Replicas
--job_log_dir=gs:// < your-bucket > Anda dapat mengamati kurva kerugian dan grafik log perplexity sebagai berikut:
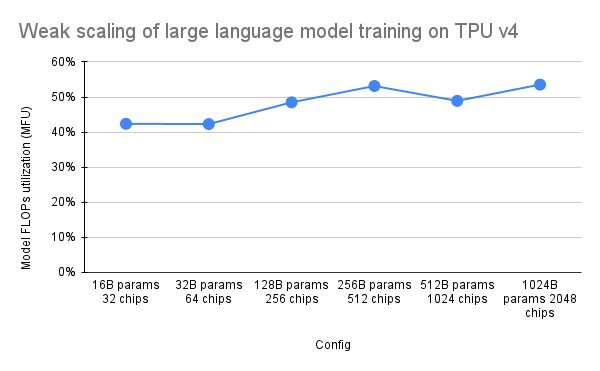
Makalah PaLM memperkenalkan metrik efisiensi yang disebut Model FLOPs Utilization (MFU). Hal ini diukur sebagai rasio throughput yang diamati (misalnya, token per detik untuk model bahasa) dengan throughput maksimum teoretis dari sistem yang memanfaatkan 100% FLOP puncak. Hal ini berbeda dari cara lain untuk mengukur pemanfaatan komputasi karena tidak mencakup FLOP yang dihabiskan untuk rematerialisasi aktivasi selama proses backward pass, yang berarti bahwa efisiensi yang diukur oleh MFU diterjemahkan langsung ke dalam kecepatan pelatihan end-to-end.
Untuk mengevaluasi MFU dari kelas beban kerja utama pada Pod TPU v4 dengan Pax, kami melakukan kampanye benchmark mendalam pada serangkaian konfigurasi model bahasa Transformer (GPT) khusus decoder yang ukurannya berkisar dari miliaran hingga triliunan parameter pada kumpulan data c4. Grafik berikut menunjukkan efisiensi pelatihan menggunakan pola "penskalaan lemah" di mana kami meningkatkan ukuran model sebanding dengan jumlah chip yang digunakan.
Konfigurasi multislice dalam repo ini mengacu pada 1. Konfigurasi irisan tunggal untuk arsitektur sintaksis/model dan 2. Repo MaxText untuk nilai konfigurasi.
Kami memberikan contoh pengoperasian di bawah c4_multislice.py` sebagai titik awal untuk Pax di multislice.
Kami merujuk ke halaman ini untuk dokumentasi yang lebih lengkap tentang penggunaan Sumber Daya Antrian untuk proyek Cloud TPU multi-slice. Berikut ini menunjukkan langkah-langkah yang diperlukan untuk menyiapkan TPU untuk menjalankan contoh konfigurasi di repo ini.
export ZONE=us-central2-b
export VERSION=tpu-vm-v4-base
export PROJECT= < your-project >
export ACCELERATOR=v4-128 # or v4-384 depending on which config you run Misalnya, untuk menjalankan C4Spmd22BAdam2xv4_128 pada 2 potong v4-128, Anda perlu menyiapkan TPU dengan cara berikut:
export TPU_PREFIX= < your-prefix > # New TPUs will be created based off this prefix
export QR_ID= $TPU_PREFIX
export NODE_COUNT= < number-of-slices > # 1, 2, or 4 depending on which config you run
# create a TPU VM
gcloud alpha compute tpus queued-resources create $QR_ID --accelerator-type= $ACCELERATOR --runtime-version=tpu-vm-v4-base --node-count= $NODE_COUNT --node-prefix= $TPU_PREFIX Perintah pengaturan yang dijelaskan sebelumnya harus dijalankan pada SEMUA pekerja di SEMUA irisan. Anda dapat 1) melakukan ssh ke setiap pekerja dan setiap irisan satu per satu; atau 2) gunakan loop for dengan flag --worker=all sebagai perintah berikut.
for (( i = 0 ; i < $NODE_COUNT ; i ++ ))
do
gcloud compute tpus tpu-vm ssh $TPU_PREFIX - $i --zone=us-central2-b --worker=all --command= " pip install paxml && pip install orbax==0.1.1 && pip install " jax[tpu] " -f https://storage.googleapis.com/jax-releases/libtpu_releases.html "
done Untuk menjalankan konfigurasi multislice, buka jumlah terminal yang sama dengan $NODE_COUNT Anda. Untuk percobaan kami pada 2 irisan ( C4Spmd22BAdam2xv4_128 ), buka dua terminal. Kemudian, jalankan masing-masing perintah ini satu per satu dari setiap terminal.
Dari Terminal 0, jalankan perintah pelatihan untuk irisan 0 sebagai berikut:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -0 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Dari Terminal 1, jalankan perintah pelatihan secara bersamaan untuk irisan 1 sebagai berikut:
export TPU_PREFIX= < your-prefix >
export EXP_NAME=C4Spmd22BAdam2xv4_128
export LIBTPU_INIT_ARGS= " --xla_jf_spmd_threshold_for_windowed_einsum_mib=0 --xla_tpu_spmd_threshold_for_allgather_cse=10000 --xla_enable_async_all_gather=true --xla_tpu_enable_latency_hiding_scheduler=true TPU_MEGACORE=MEGACORE_DENSE "
gcloud compute tpus tpu-vm ssh $TPU_PREFIX -1 --zone=us-central2-b --worker=all
--command= " LIBTPU_INIT_ARGS= $LIBTPU_INIT_ARGS
python3 /home/yooh/.local/lib/python3.8/site-packages/paxml/main.py
--exp=tasks.lm.params.c4_multislice. ${EXP_NAME} --job_log_dir=gs://<your-bucket> "Tabel ini mencakup detail tentang bagaimana nama variabel MaxText diterjemahkan ke Pax.
Perhatikan bahwa MaxText memiliki "skala" yang dikalikan dengan beberapa parameter (base_num_decoder_layers, base_emb_dim, base_mlp_dim, base_num_heads) untuk nilai akhir.
Hal lain yang perlu disebutkan adalah meskipun Pax mencakup DCN dan ICN MESH_SHAPE sebagai array, di MaxText terdapat variabel terpisah yaitu data_parallelism, fsdp_parallelism, dan tensor_parallelism untuk DCN dan ICI. Karena nilai-nilai ini ditetapkan sebagai 1 secara default, hanya variabel dengan nilai lebih besar dari 1 yang dicatat dalam tabel terjemahan ini.
Artinya, ICI_MESH_SHAPE = [ici_data_parallelism, ici_fsdp_parallelism, ici_tensor_parallelism] dan DCN_MESH_SHAPE = [dcn_data_parallelism, dcn_fsdp_parallelism, dcn_tensor_parallelism]
| Paket C4Spmd22BAdam2xv4_128 | MaxTeks 2xv4-128.sh | (setelah skala diterapkan) | ||
|---|---|---|---|---|
| skala (diterapkan pada 4 variabel berikutnya) | 3 | |||
| NUM_LAYERS | 48 | base_num_decoder_layers | 16 | 48 |
| MODEL_DIMS | 6144 | base_emb_dim | 2048 | 6144 |
| TERSEMBUNYI_DIMS | 24576 | MODEL_DIMS * 4 (= base_mlp_dim) | 8192 | 24576 |
| NUM_HEADS | 24 | base_num_heads | 8 | 24 |
| DIMS_PER_HEAD | 256 | kepala_redup | 256 | |
| PERCORE_BATCH_SIZE | 16 | per_perangkat_batch_size | 16 | |
| MAX_SEQ_LEN | 1024 | max_target_length | 1024 | |
| VOCAB_SIZE | 32768 | kosakata_ukuran | 32768 | |
| FPROP_DTYPE | jnp.bfloat16 | tipe | bfloat16 | |
| USE_REPEATED_LAYER | BENAR | |||
| SUMMARY_INTERVAL_LANGKAH | 10 | |||
| ICI_MESH_SHAPE | [1, 64, 1] | ici_fsdp_parallelism | 64 | |
| DCN_MESH_BENTUK | [2, 1, 1] | dcn_data_parallelism | 2 |
Input adalah turunan dari kelas BaseInput untuk memasukkan data ke dalam model untuk pelatihan/eval/dekode.
class BaseInput :
def get_next ( self ):
pass
def reset ( self ):
pass Ini bertindak seperti iterator: get_next() mengembalikan NestedMap , di mana setiap bidang adalah array numerik dengan ukuran batch sebagai dimensi utamanya.
Setiap masukan dikonfigurasi oleh subkelas BaseInput.HParams . Di halaman ini, kita menggunakan p untuk menunjukkan sebuah instance dari BaseInput.Params , dan itu membuat instance menjadi input .
Di Pax, data selalu bersifat multihost: Setiap proses Jax akan memiliki input independen dan terpisah yang dibuat. Paramnya akan memiliki p.infeed_host_index yang berbeda, yang disetel secara otomatis oleh Pax.
Oleh karena itu, ukuran batch lokal yang terlihat di setiap host adalah p.batch_size , dan ukuran batch global adalah (p.batch_size * p.num_infeed_hosts) . Orang akan sering melihat p.batch_size disetel ke jax.local_device_count() * PERCORE_BATCH_SIZE .
Karena sifat multihost ini, input harus dipecah dengan benar.
Untuk pelatihan, setiap input tidak boleh mengeluarkan kumpulan yang identik, dan untuk eval pada kumpulan data yang terbatas, setiap input harus diakhiri setelah jumlah kumpulan yang sama. Solusi terbaiknya adalah menerapkan implementasi input dengan membagi data dengan benar, sehingga setiap input pada host yang berbeda tidak tumpang tindih. Jika gagal, seseorang juga dapat menggunakan benih acak yang berbeda untuk menghindari duplikat batch selama pelatihan.
input.reset() tidak pernah dipanggil pada data pelatihan, tetapi dapat digunakan untuk eval (atau dekode) data.
Untuk setiap proses eval (atau decode), Pax mengambil N batch dari input dengan memanggil input.get_next() N kali. Jumlah batch yang digunakan, N , dapat berupa angka tetap yang ditentukan oleh pengguna, melalui p.eval_loop_num_batches ; atau N bisa dinamis ( p.eval_loop_num_batches=None ) yaitu kita memanggil input.get_next() sampai kita menghabiskan semua datanya (dengan menaikkan StopIteration atau tf.errors.OutOfRange ).
Jika p.reset_for_eval=True , p.eval_loop_num_batches diabaikan dan N ditentukan secara dinamis sebagai jumlah batch yang akan menghabiskan data. Dalam hal ini, p.repeat harus disetel ke False, karena melakukan sebaliknya akan menghasilkan decode/eval yang tak terbatas.
Jika p.reset_for_eval=False , Pax akan mengambil batch p.eval_loop_num_batches . Ini harus disetel dengan p.repeat=True agar data tidak habis sebelum waktunya.
Perhatikan bahwa input LingvoEvalAdaptor memerlukan p.reset_for_eval=True .
N : statis | N : dinamis | |
|---|---|---|
p.reset_for_eval=True | Setiap proses eval menggunakan | Satu zaman untuk setiap proses evaluasi. |
: : N batch pertama. Bukan : eval_loop_num_batches : | ||
| : : belum didukung. : diabaikan. Masukan harus: | ||
| : : : terbatas : | ||
: : : ( p.repeat=False ) : | ||
p.reset_for_eval=False | Setiap proses eval menggunakan | Tidak didukung. |
: : tidak tumpang tindih N : : | ||
| : : batch yang digulung : : | ||
| : : dasar, menurut : : | ||
: : eval_loop_num_batches : : | ||
| : : . Masukan harus berulang : : | ||
| : : tanpa batas waktu : : | ||
: : ( p.repeat=True ) atau : : | ||
| : : jika tidak, dapat menaikkan : : | ||
| : : pengecualian : : |
Jika menjalankan decode/eval tepat pada satu periode (yaitu ketika p.reset_for_eval=True ), input harus menangani sharding dengan benar sehingga setiap shard muncul pada langkah yang sama setelah jumlah batch yang sama persis diproduksi. Ini biasanya berarti bahwa masukan harus sesuai dengan data eval. Ini dilakukan secara otomatis oleh SeqIOInput dan LingvoEvalAdaptor (lihat selengkapnya di bawah).
Untuk sebagian besar input, kami hanya memanggil get_next() untuk mendapatkan kumpulan data. Salah satu jenis data eval adalah pengecualian untuk ini, di mana "cara menghitung metrik" juga ditentukan pada objek masukan.
Ini hanya didukung dengan SeqIOInput yang mendefinisikan beberapa tolok ukur eval kanonik. Secara khusus, Pax predict_metric_fns dan score_metric_fns() yang ditentukan pada tugas SeqIO untuk menghitung metrik eval (walaupun Pax tidak bergantung pada evaluator SeqIO secara langsung).
Ketika suatu model menggunakan beberapa masukan, baik antara pelatihan/eval atau data pelatihan yang berbeda antara prapelatihan/penyempurnaan, pengguna harus memastikan bahwa tokenizer yang digunakan oleh masukan tersebut identik, terutama saat mengimpor masukan berbeda yang diterapkan oleh orang lain.
Pengguna dapat memeriksa kewarasan tokenizer dengan mendekode beberapa id dengan input.ids_to_strings() .
Itu selalu merupakan ide bagus untuk memeriksa kewarasan data dengan melihat beberapa kumpulan. Pengguna dapat dengan mudah mereproduksi param di colab dan memeriksa data:
p = ... # specify the intended input param
inp = p . Instantiate ()
b = inp . get_next ()
print ( b ) Data pelatihan biasanya tidak boleh menggunakan benih acak yang tetap. Hal ini karena jika tugas pelatihan didahului, data pelatihan akan mulai terulang kembali. Khususnya, untuk input Lingvo, kami menyarankan pengaturan p.input.file_random_seed = 0 untuk data pelatihan.
Untuk menguji apakah sharding ditangani dengan benar, pengguna dapat secara manual mengatur nilai yang berbeda untuk p.num_infeed_hosts, p.infeed_host_index dan melihat apakah input yang dipakai mengeluarkan batch yang berbeda.
Pax mendukung 3 jenis input: SeqIO, Lingvo, dan custom.
SeqIOInput dapat digunakan untuk mengimpor kumpulan data.
Input SeqIO menangani sharding dan padding data eval yang benar secara otomatis.
LingvoInputAdaptor dapat digunakan untuk mengimpor kumpulan data.
Masukan sepenuhnya didelegasikan ke implementasi Lingvo, yang mungkin menangani sharding secara otomatis atau tidak.
Untuk implementasi masukan Lingvo berbasis GenericInput yang menggunakan packing_factor tetap, sebaiknya gunakan LingvoInputAdaptorNewBatchSize untuk menentukan ukuran batch yang lebih besar untuk masukan Lingvo bagian dalam dan memasukkan ukuran batch yang diinginkan (biasanya jauh lebih kecil) pada p.batch_size .
Untuk data eval, kami merekomendasikan penggunaan LingvoEvalAdaptor untuk menangani sharding dan padding untuk menjalankan eval selama satu periode.
Subkelas khusus dari BaseInput . Pengguna mengimplementasikan subkelasnya sendiri, biasanya dengan tf.data atau SeqIO.
Pengguna juga dapat mewarisi kelas masukan yang ada untuk hanya menyesuaikan pemrosesan pasca batch. Misalnya:
class MyInput ( base_input . LingvoInputAdaptor ):
def get_next ( self ):
batch = super (). get_next ()
# modify batch: batch.new_field = ...
return batchHyperparameter adalah bagian penting dalam menentukan model dan mengonfigurasi eksperimen.
Untuk berintegrasi lebih baik dengan perkakas Python, Pax/Praxis menggunakan gaya konfigurasi berbasis kelas data pythonic untuk hyperparameter.
class Linear ( base_layer . BaseLayer ):
"""Linear layer without bias."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
"""
input_dims : int = 0
output_dims : int = 0Kelas data HParams juga dapat disarangkan, pada contoh di bawah, atribut linear_tpl adalah Linear.HParams yang disarangkan.
class FeedForward ( base_layer . BaseLayer ):
"""Feedforward layer with activation."""
class HParams ( BaseHParams ):
"""Associated hyperparams for this layer class.
Attributes:
input_dims: Depth of the input.
output_dims: Depth of the output.
has_bias: Adds bias weights or not.
linear_tpl: Linear layer params.
activation_tpl: Activation layer params.
"""
input_dims : int = 0
output_dims : int = 0
has_bias : bool = True
linear_tpl : BaseHParams = sub_config_field ( Linear . HParams )
activation_tpl : activations . BaseActivation . HParams = sub_config_field (
ReLU . HParams )Lapisan mewakili fungsi arbitrer yang mungkin memiliki parameter yang dapat dilatih. Sebuah Layer dapat berisi Layer lain sebagai anak-anak. Lapisan adalah elemen penyusun model yang penting. Lapisan mewarisi dari Flax nn.Module.
Biasanya lapisan mendefinisikan dua metode:
Metode ini menciptakan bobot dan lapisan anak yang dapat dilatih.
Metode ini mendefinisikan fungsi propagasi maju, menghitung beberapa keluaran berdasarkan masukan. Selain itu, fprop mungkin menambahkan ringkasan atau melacak kerugian tambahan.
Fiddle adalah pustaka konfigurasi open-source Python pertama yang dirancang untuk aplikasi ML. Pax/Praxis mendukung interoperabilitas dengan Fiddle Config/Partial(s) dan beberapa fitur lanjutan seperti pemeriksaan kesalahan dan parameter bersama.
fdl_config = Linear . HParams . config ( input_dims = 1 , output_dims = 1 )
# A typo.
fdl_config . input_dimz = 31337 # Raises an exception immediately to catch typos fast!
fdl_partial = Linear . HParams . partial ( input_dims = 1 )Dengan menggunakan Fiddle, lapisan dapat dikonfigurasi untuk dibagikan (misalnya: dipakai hanya sekali dengan bobot bersama yang dapat dilatih).
Sebuah model hanya mendefinisikan jaringan, biasanya kumpulan Lapisan dan mendefinisikan antarmuka untuk berinteraksi dengan model seperti decoding, dll.
Beberapa contoh model dasar meliputi:
Tugas berisi satu lagi Model dan Pelajar/Pengoptimal. Subkelas Task yang paling sederhana adalah SingleTask yang memerlukan Hparams berikut:
class HParams ( base_task . BaseTask . HParams ):
""" Task parameters .
Attributes :
name : Name of this task object , must be a valid identifier .
model : The underlying JAX model encapsulating all the layers .
train : HParams to control how this task should be trained .
metrics : A BaseMetrics aggregator class to determine how metrics are
computed .
loss_aggregator : A LossAggregator aggregator class to derermine how the
losses are aggregated ( e . g single or MultiLoss )
vn : HParams to control variational noise .| Versi PyPI | Melakukan |
|---|---|
| 0.1.0 | 546370f5323ef8b27d38ddc32445d7d3d1e4da9a |
Copyright 2022 Google LLC
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
https://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.


