BabyGPT Build_GPT_From_Scratch
1.0.0
Baby GPT adalah proyek eksplorasi yang dirancang untuk secara bertahap membangun model bahasa mirip GPT. Proyek ini dimulai dengan Model Bigram sederhana dan secara bertahap menggabungkan konsep-konsep lanjutan dari arsitektur model Transformer.
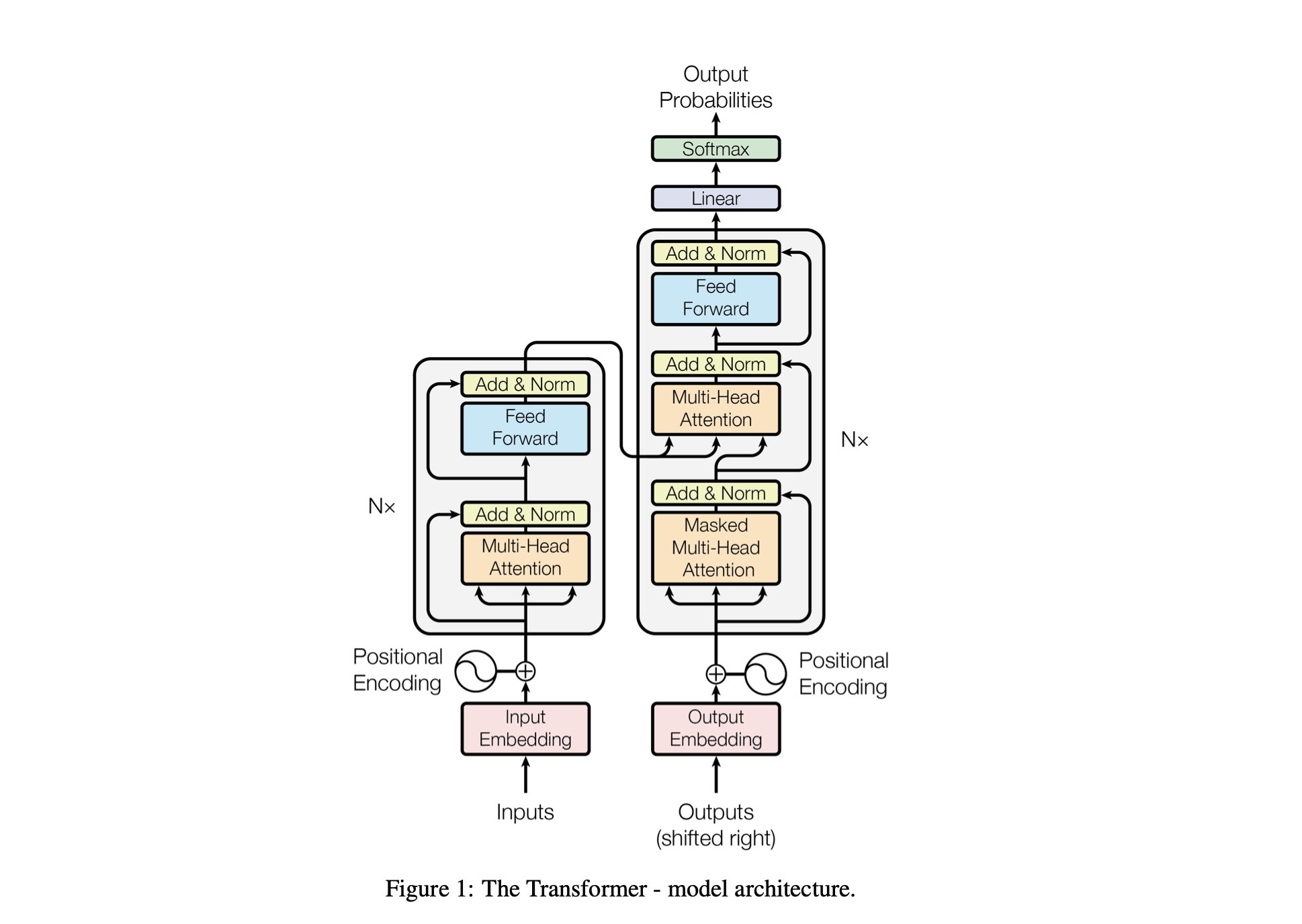
Performa model disetel menggunakan hyperparameter berikut:
batch_size : Jumlah urutan yang diproses secara paralel selama pelatihanblock_size : Panjang urutan yang sedang diproses oleh modeld_model : Jumlah fitur dalam model (ukuran embeddings)d_k : Jumlah fitur per kepala perhatian.num_iter : Jumlah total iterasi pelatihan yang akan dijalankan modelNx : Jumlah blok transformator, atau lapisan, dalam model.eval_interval : Interval di mana kerugian model dihitung dan dievaluasilr_rate : Kecepatan pembelajaran untuk pengoptimal Adamdevice : Secara otomatis disetel ke 'cuda' jika GPU yang kompatibel tersedia, jika tidak, defaultnya adalah 'cpu' .eval_iters : Jumlah iterasi untuk menghitung rata-rata kerugian evaluasih : Jumlah kepala perhatian dalam mekanisme perhatian multi-kepaladropout_rate : Tingkat dropout yang digunakan selama pelatihan untuk mencegah overfittingHyperparameter ini dipilih dengan cermat untuk menyeimbangkan kemampuan model dalam belajar dari data tanpa overfitting dan untuk mengelola sumber daya komputasi secara efektif.
| Hiperparameter | Model CPU | Model GPU |
|---|---|---|
device | 'cpu' | 'cuda' jika tersedia, yang lain 'cpu' |
batch_size | 16 | 64 |
block_size | 8 | 256 |
num_iter | 10.000 | 10.000 |
eval_interval | 500 | 500 |
eval_iters | 100 | 200 |
d_model | 16 | 512 |
d_k | 4 | 16 |
Nx | 2 | 6 |
dropout_rate | 0,2 | 0,2 |
lr_rate | 0,005 (5e-3) | 0,001 (1e-3) |
h | 2 | 6 |
open('./GPT Series/input.txt', 'r', encoding = 'utf-8')chars_to_int dan int_to_chars .encode dan kembali dengan fungsi decode .train_data ) dan validasi ( valid_data ).get_batch menyiapkan data dalam batch mini untuk pelatihan.BigramLM .Mini-batching adalah teknik dalam pembelajaran mesin di mana data pelatihan dibagi menjadi beberapa kelompok kecil. Setiap mini-batch diproses secara terpisah selama pelatihan model. Pendekatan ini membantu dalam:
# Function to create mini-batches for training or validation.
def get_batch ( split ):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch . randint ( len ( data ) - block_size , ( batch_size ,))
# Create input (x) and target (y) sequences from data blocks.
x = torch . stack ([ data [ i : i + block_size ] for i in ix ])
y = torch . stack ([ data [ i + 1 : i + block_size + 1 ] for i in ix ])
# Move data to GPU if available for faster processing.
x , y = x . to ( device ), y . to ( device )
return x , y | Faktor | Ukuran Batch Kecil | Ukuran Batch Besar |
|---|---|---|
| Kebisingan Gradien | Lebih tinggi (lebih banyak variasi dalam pembaruan) | Lebih rendah (pembaruan lebih konsisten) |
| Konvergensi | Cenderung mengeksplorasi lebih banyak solusi, termasuk solusi minimum yang lebih datar | Seringkali menyatu ke titik minimum yang lebih tajam |
| Generalisasi | Berpotensi lebih baik (karena nilai minimum yang lebih datar) | Berpotensi lebih buruk (karena nilai minimum yang lebih tajam) |
| Bias | Lebih rendah (kecil kemungkinannya untuk menyesuaikan diri dengan pola data pelatihan) | Lebih tinggi (mungkin cocok dengan pola data pelatihan) |
| Perbedaan | Lebih tinggi (karena lebih banyak eksplorasi dalam ruang solusi) | Lebih rendah (karena lebih sedikit eksplorasi dalam ruang solusi) |
| Biaya Komputasi | Lebih tinggi per zaman (lebih banyak pembaruan) | Lebih rendah per zaman (lebih sedikit pembaruan) |
| Penggunaan Memori | Lebih rendah | Lebih tinggi |
Fungsi estimate_loss menghitung kerugian rata-rata model selama jumlah iterasi tertentu (eval_iters). Ini digunakan untuk menilai performa model tanpa memengaruhi parameternya. Model disetel ke mode evaluasi untuk menonaktifkan lapisan tertentu seperti dropout untuk penghitungan kerugian yang konsisten. Setelah menghitung kerugian rata-rata untuk data pelatihan dan validasi, model dikembalikan ke mode pelatihan. Fungsi ini penting untuk memantau proses pelatihan dan melakukan penyesuaian jika diperlukan.
@ torch . no_grad () # Disables gradient calculation to save memory and computations
def estimate_loss ():
result = {} # Dictionary to store the results
model . eval () # Puts the model in evaluation mode
# Iterates over the data splits (training and validation)
for split in [ 'train' , 'valid_date' ]:
# Initializes a tensor to store the losses for each iteration
losses = torch . zeros ( eval_iters )
# Loops over the number of iterations to calculate the average loss
for e in range ( eval_iters ):
X , Y = get_batch ( split ) # Fetches a batch of data
logits , loss = model ( X , Y ) # Gets the model outputs and computes the loss
losses [ e ] = loss . item () # Records the loss for this iteration
# Stores the mean loss for the current split in the result dictionary
result [ split ] = losses . mean ()
model . train () # Sets the model back to training mode
return result # Returns the dictionary with the computed losses Pengkodean Posisi : Menambahkan informasi posisi ke model dengan positional_encodings_table di kelas BigramLM . Kami menambahkan Pengkodean Posisi ke penyematan karakter kami seperti pada arsitektur transformator.
Di sini kami menyiapkan dan menggunakan pengoptimal AdamW untuk melatih model jaringan saraf di PyTorch. Pengoptimal Adam lebih disukai dalam banyak skenario pembelajaran mendalam karena menggabungkan keunggulan dua ekstensi penurunan gradien stokastik lainnya: AdaGrad dan RMSProp. Adam menghitung kecepatan pembelajaran adaptif untuk setiap parameter. Selain menyimpan rata-rata gradien kuadrat masa lalu yang membusuk secara eksponensial seperti RMSProp, Adam juga menyimpan rata-rata gradien masa lalu yang membusuk secara eksponensial, mirip dengan momentum. Hal ini memungkinkan pengoptimal menyesuaikan kecepatan pembelajaran untuk setiap bobot jaringan saraf, sehingga dapat menghasilkan pelatihan yang lebih efektif pada kumpulan data dan arsitektur yang kompleks.
AdamW memodifikasi cara peluruhan bobot dimasukkan ke dalam proses pengoptimalan, mengatasi masalah pada pengoptimal Adam asli di mana peluruhan bobot tidak dipisahkan dengan baik dari pembaruan gradien, sehingga menyebabkan penerapan regularisasi yang kurang optimal. Menggunakan AdamW terkadang dapat menghasilkan performa pelatihan dan generalisasi yang lebih baik pada data yang tidak terlihat. Kami memilih AdamW karena kemampuannya menangani penurunan berat badan secara lebih efektif dibandingkan pengoptimal Adam standar, sehingga berpotensi menghasilkan pelatihan dan generalisasi model yang lebih baik.
optimizer = torch . optim . AdamW ( model . parameters (), lr = lr_rate )
for iter in range ( num_iter ):
# estimating the loss for per X interval
if iter % eval_interval == 0 :
losses = estimate_loss ()
print ( f"step { iter } : train loss is { losses [ 'train' ]:.5f } and validation loss is { losses [ 'valid_date' ]:.5f } " )
# sampling a mini batch of data
xb , yb = get_batch ( "train" )
# Forward Pass
logits , loss = model ( xb , yb )
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer . zero_grad ( set_to_none = True )
# Backward Pass or Backpropogation: Computing Gradients
loss . backward ()
# Updating the Model Parameters
optimizer . step ()Self-Attention adalah mekanisme yang memungkinkan model mempertimbangkan pentingnya berbagai bagian data masukan secara berbeda. Ini adalah komponen kunci dari arsitektur Transformer, yang memungkinkan model untuk fokus pada bagian yang relevan dari urutan masukan untuk membuat prediksi.
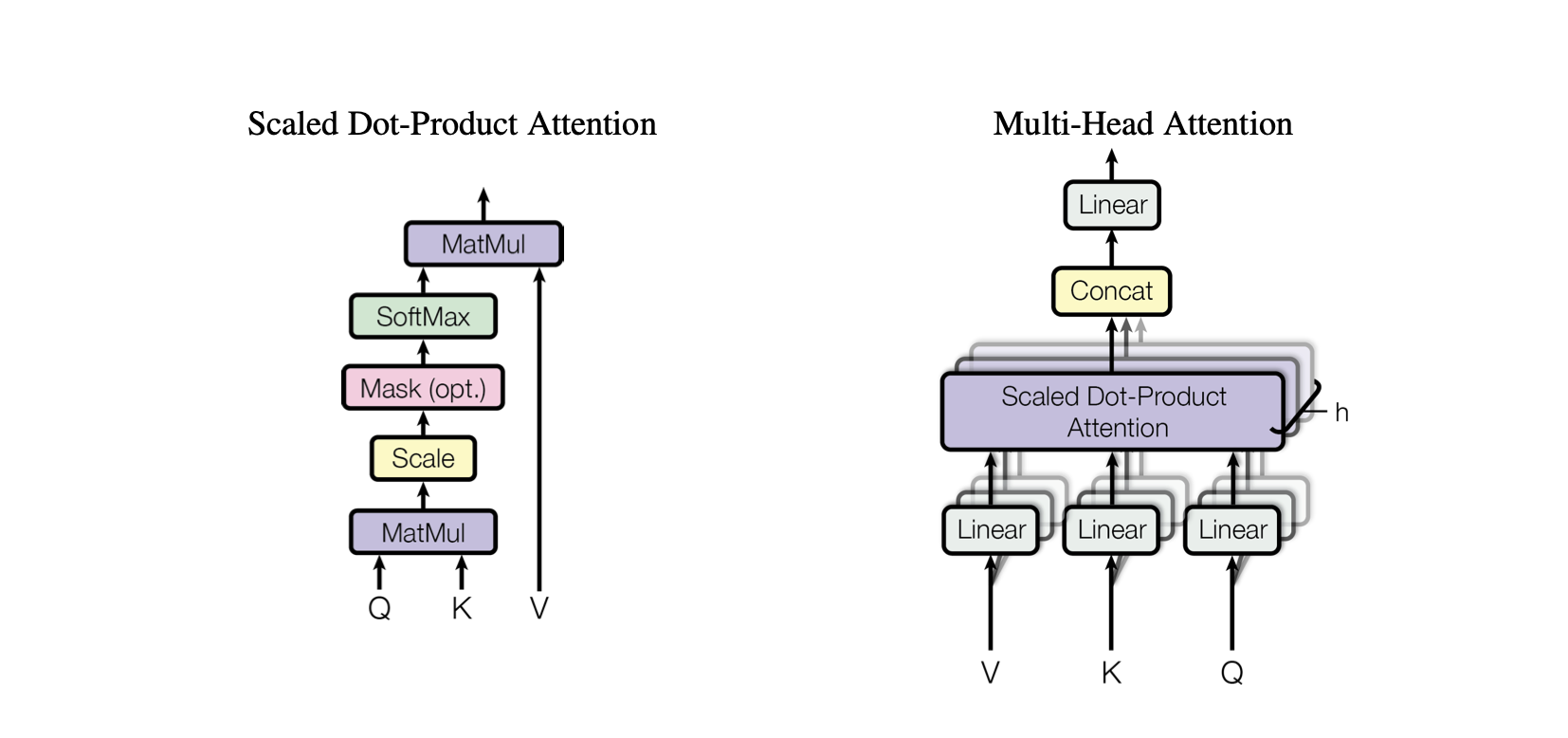
Perhatian Produk Titik : Mekanisme perhatian sederhana yang menghitung jumlah nilai tertimbang berdasarkan perkalian titik antara kueri dan kunci.
Perhatian Produk Titik Berskala : Peningkatan pada perhatian produk titik yang memperkecil skala produk titik berdasarkan dimensi tombol, mencegah gradien menjadi terlalu kecil selama pelatihan.
OneHeadSelfAttention : Penerapan mekanisme perhatian mandiri berkepala tunggal yang memungkinkan model memperhatikan berbagai posisi urutan masukan. Kelas SelfAttention menampilkan intuisi di balik mekanisme perhatian dan versi skalanya.
Setiap model yang terkait dalam proyek Baby GPT secara bertahap dibangun berdasarkan model sebelumnya, dimulai dengan intuisi di balik mekanisme Self-Attention, diikuti dengan implementasi praktis dari perhatian produk titik dan produk titik yang berskala, dan berpuncak pada integrasi satu model. modul perhatian diri kepala.
class SelfAttention ( nn . Module ):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__ ( self , d_k ):
super (). __init__ () #superclass initialization for proper torch functionality
# keys
self . keys = nn . Linear ( d_model , d_k , bias = False )
# queries
self . queries = nn . Linear ( d_model , d_k , bias = False )
# values
self . values = nn . Linear ( d_model , d_k , bias = False )
# buffer for the model
self . register_buffer ( 'tril' , torch . tril ( torch . ones ( block_size , block_size )))
def forward ( self , X ):
"""Computing Attention Matrix"""
B , T , C = X . shape
# Keys matrix K
K = self . keys ( X ) # (B, T, C)
# Query matrix Q
Q = self . queries ( X ) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K . transpose ( - 2 , - 1 ) * 1 / math . sqrt ( C ) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product . masked_fill ( self . tril [: T , : T ] == 0 , float ( '-inf' ))
# SoftMax transformation
attention_matrix = F . softmax ( scaled_dot_product_masked , dim = - 1 ) # (B, T, T)
# Weighted Aggregation
V = self . values ( X ) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur Kelas SelfAttention mewakili blok bangunan mendasar dari model Transformer, merangkum mekanisme perhatian diri dengan satu kepala. Berikut ini wawasan tentang komponen dan prosesnya:
Inisialisasi : Konstruktor __init__(self, d_k) menginisialisasi lapisan linier untuk kunci, kueri, dan nilai, semuanya dengan dimensi d_k . Transformasi linier ini memproyeksikan masukan ke dalam subruang yang berbeda untuk penghitungan perhatian selanjutnya.
Buffer : self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) mendaftarkan matriks segitiga bawah sebagai buffer persisten yang tidak dianggap sebagai parameter model. Matriks ini digunakan untuk menutupi mekanisme perhatian untuk mencegah posisi masa depan dipertimbangkan dalam setiap langkah perhitungan (berguna dalam decoder perhatian mandiri).
Forward Pass : Metode forward(self, X) mendefinisikan komputasi yang dilakukan pada setiap panggilan modul self-attention
MultiHeadAttention : Menggabungkan output dari beberapa kepala SelfAttention di kelas MultiHeadAttention . Kelas MultiHeadAttention merupakan implementasi lanjutan dari mekanisme perhatian mandiri dengan satu kepala dari langkah sebelumnya, namun sekarang beberapa kepala perhatian beroperasi secara paralel, masing-masing berfokus pada bagian masukan yang berbeda.
class MultiHeadAttention ( nn . Module ):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__ ( self , h , d_k ):
super (). __init__ ()
# initializing the heads, we want h times attention heads wit size d_k
self . heads = nn . ModuleList ([ SelfAttention ( d_k ) for _ in range ( h )])
# adding linear layer to project the concatenated heads to the original dimension
self . projections = nn . Linear ( h * d_k , d_model )
# adding dropout layer
self . droupout = nn . Dropout ( dropout_rate )
def forward ( self , X ):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch . cat ([ h ( X ) for h in self . heads ], dim = - 1 )
# projecting the concatenated heads to the original dimension
combined_attentions = self . projections ( combined_attentions )
# applying dropout
combined_attentions = self . droupout ( combined_attentions )
return combined_attentions
FeedForward : Mengimplementasikan jaringan saraf feed-forward dengan aktivasi ReLU dalam kelas FeedForward . Untuk menambahkan feed-forward yang terhubung penuh ini ke model kami seperti pada Model Transformer asli.
class FeedForward ( nn . Module ):
"""FeedForward Layer with ReLU activation function"""
def __init__ ( self , d_model ):
super (). __init__ ()
self . net = nn . Sequential (
# 2 linear layers with ReLU activation function
nn . Linear ( d_model , 4 * d_model ),
nn . ReLU (),
nn . Linear ( 4 * d_model , d_model ),
nn . Dropout ( dropout_rate )
)
def forward ( self , X ):
# applying the feedforward layer
return self . net ( X ) TransformerBlocks : Menumpuk blok transformator menggunakan kelas Block untuk membuat arsitektur jaringan yang lebih dalam. Kedalaman dan Kompleksitas: Dalam jaringan saraf, kedalaman mengacu pada jumlah lapisan yang digunakan untuk memproses data. Setiap lapisan tambahan (atau blok, dalam kasus Transformers) memungkinkan jaringan untuk menangkap fitur yang lebih kompleks dan abstrak dari data masukan.
Pemrosesan Sequential: Setiap blok Transformer memproses keluaran dari blok sebelumnya, secara bertahap membangun pemahaman masukan yang lebih canggih. Pemrosesan sekuensial ini memungkinkan jaringan untuk mengembangkan representasi data yang mendalam dan berlapis. Komponen Blok Transformator
# ---------------------------------- Blocks ----------------------------------#
class Block ( nn . Module ):
"""Multiple Blocks of Transformer"""
def __init__ ( self , d_model , h ):
super (). __init__ ()
d_k = d_model // h
# Layer 4: Adding Attention layer
self . attention_head = MultiHeadAttention ( h , d_k ) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self . feedforward = FeedForward ( d_model )
# Layer Normalization 1
self . ln1 = nn . LayerNorm ( d_model )
# Layer Normalization 2
self . ln2 = nn . LayerNorm ( d_model )
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X ResidualConnections : Meningkatkan kelas Block untuk menyertakan koneksi sisa, meningkatkan efisiensi pembelajaran. Koneksi Residual, juga dikenal sebagai koneksi lewati, adalah inovasi penting dalam desain jaringan neural dalam, khususnya pada model Transformer. Mereka mengatasi salah satu tantangan utama dalam melatih jaringan dalam: masalah gradien yang hilang.
# Adding additional X for Residual Connections
def forward ( self , X ):
X = X + self . attention_head ( self . ln1 ( X ))
X = X + self . feedforward ( self . ln2 ( X ))
return X LayerNorm : Menambahkan Normalisasi Lapisan ke keluaran lapisan Transformer.Normalisasi kami dengan nn.LayerNorm(d_model) di kelas Block .
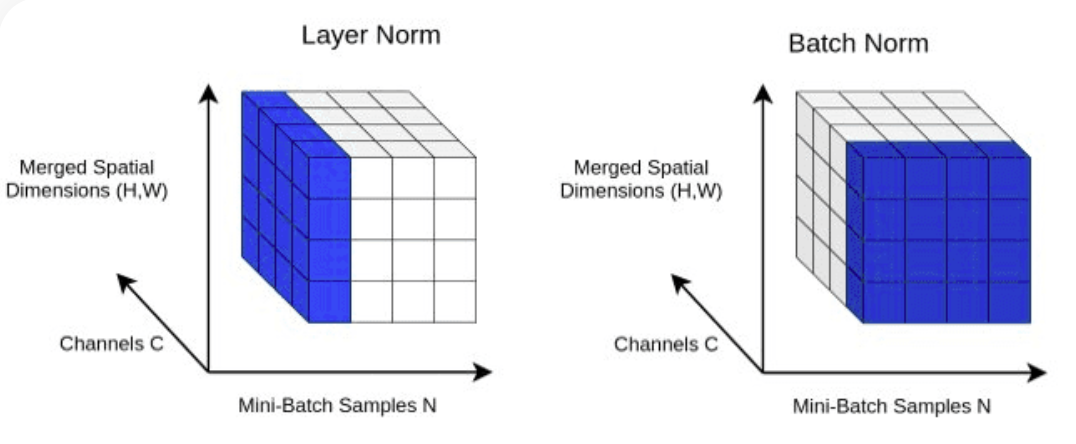
class LayerNorm :
def __init__ ( self , dim , eps = 1e-5 ):
self . eps = eps
self . gamma = torch . ones ( dim )
self . beta = torch . zeros ( dim )
def __call__ ( self , x ):
# orward pass calculaton
xmean = x . mean ( 1 , keepdim = True ) # layer mean
xvar = x . var ( 1 , keepdim = True ) # layer variance
xhat = ( x - xmean ) / torch . sqrt ( xvar + self . eps ) # normalize to unit variance
self . out = self . gamma * xhat + self . beta
return self . out
def parameters ( self ):
return [ self . gamma , self . beta ] Dropout : Untuk ditambahkan ke lapisan SelfAttention dan FeedForward sebagai metode regularisasi untuk mencegah overfitting. Kami menambahkan drop-out ke:
ScaleUp : Meningkatkan kompleksitas model dengan memperluas batch_size , block_size , d_model , d_k , dan Nx . Anda memerlukan toolkit CUDA serta mesin dengan GPU NVIDIA untuk melatih dan menguji model yang lebih besar ini.
Jika Anda ingin mencoba CUDA untuk akselerasi GPU, pastikan Anda menginstal versi PyTorch yang sesuai dan mendukung CUDA.
import torch
torch . cuda . is_available ()Anda dapat melakukan ini dengan menentukan versi CUDA di perintah instalasi PyTorch Anda, seperti di baris perintah:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113

