ke dialogue
1.0.0


Ini adalah implementasi dari makalah ini:
Mempelajari Basis Pengetahuan dengan Parameter untuk Sistem Dialog Berorientasi Tugas . Andrea Madotto , Samuel Cahyawijaya, Genta Indra Winata, Yan Xu, Zihan Liu, Zhaojiang Lin, Pascale Fung Temuan EMNLP 2020 [PDF]
Jika Anda menggunakan kode sumber atau kumpulan data apa pun yang disertakan dalam toolkit ini dalam pekerjaan Anda, harap kutip makalah berikut. Bibtexnya tercantum di bawah ini:
@artikel{madotto2020learning,
title={Mempelajari Basis Pengetahuan dengan Parameter untuk Sistem Dialog Berorientasi Tugas},
author={Madotto, Andrea dan Cahyawijaya, Samuel dan Winata, Genta Indra dan Xu, Yan dan Liu, Zihan dan Lin, Zhaojiang dan Fung, Pascale},
jurnal={arXiv pracetak arXiv:2009.13656},
tahun={2020}
}
Sistem dialog berorientasi tugas dapat dimodulasi dengan pelacakan status dialog (DST) terpisah dan langkah-langkah manajemen atau dapat dilatih secara end-to-end. Dalam kedua kasus tersebut, basis pengetahuan (KB) memainkan peran penting dalam memenuhi permintaan pengguna. Sistem termodulasi mengandalkan DST untuk berinteraksi dengan KB, yang mahal dalam hal anotasi dan waktu inferensi. Sistem end-to-end menggunakan KB secara langsung sebagai masukan, namun tidak dapat diskalakan bila KB lebih besar dari beberapa ratus entri. Dalam makalah ini, kami mengusulkan metode untuk menyematkan KB, dengan ukuran berapa pun, langsung ke parameter model. Model yang dihasilkan tidak memerlukan respons DST atau templat apa pun, maupun KB sebagai masukan, dan model tersebut dapat memperbarui KB-nya secara dinamis melalui penyesuaian. Kami mengevaluasi solusi kami dalam lima kumpulan data dialog berorientasi tugas dengan ukuran KB kecil, sedang, dan besar. Eksperimen kami menunjukkan bahwa model end-to-end dapat secara efektif menanamkan basis pengetahuan dalam parameternya dan mencapai kinerja kompetitif di semua kumpulan data yang dievaluasi.
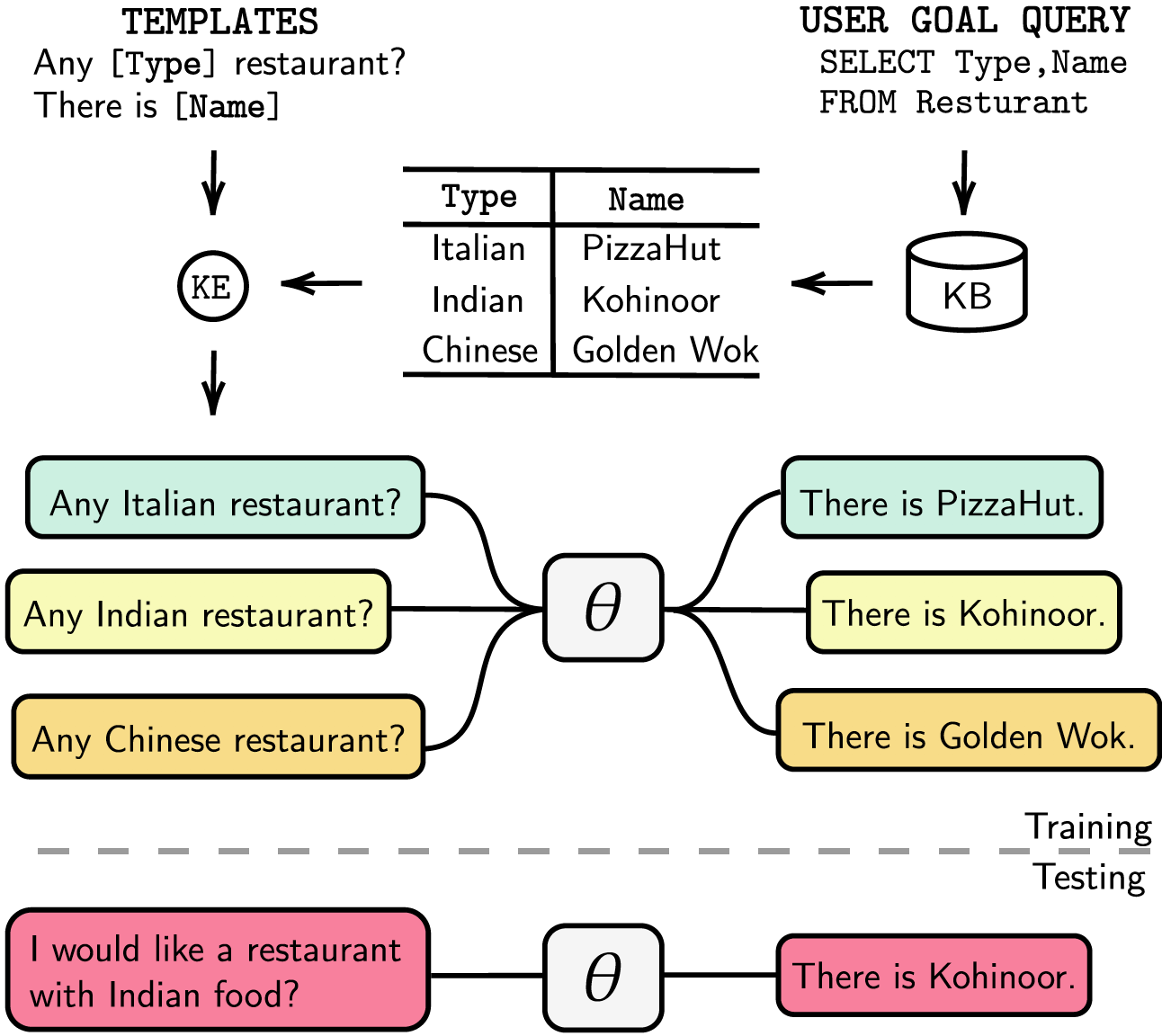
Kami mencantumkan dependensi kami pada requirements.txt , Anda dapat menginstal dependensi dengan menjalankannya
❱❱❱ pip install -r requirements.txt Selain itu, kode kami juga menyertakan dukungan fp16 dengan apex . Anda dapat menemukan paketnya dari https://github.com/NVIDIA/apex.
Kumpulan Data Unduh kumpulan data yang telah diproses sebelumnya dan masukkan file zip ke dalam folder ./knowledge_embed/babi5 . Ekstrak file zip dengan mengeksekusi
❱❱❱ cd ./knowledge_embed/babi5
❱❱❱ unzip dialog-bAbI-tasks.zipHasilkan dialog terdeleksikalisasi dari kumpulan data bAbI-5 melalui
❱❱❱ python3 generate_delexicalization_babi.pyHasilkan data leksikalisasi dari kumpulan data bAbI-5 melalui
❱❱❱ python generate_dialogues_babi5.py --dialogue_path ./dialog-bAbI-tasks/dialog-babi-task5trn_record-delex.txt --knowledge_path ./dialog-bAbI-tasks/dialog-babi-kb-all.txt --output_folder ./dialog-bAbI-tasks --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Dimana maksimum <num_augmented_knowledge> adalah 558 (disarankan) dan <num_augmented_dialogues> adalah 264 karena sesuai dengan jumlah pengetahuan dan jumlah dialog pada dataset bAbI-5.
Sempurnakan GPT-2
Kami menyediakan pos pemeriksaan model GPT-2 yang disempurnakan pada set pelatihan bAbI. Anda juga dapat memilih untuk melatih model sendiri menggunakan perintah berikut.
❱❱❱ cd ./modeling/babi5
❱❱❱ python main.py --model_checkpoint gpt2 --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Perhatikan bahwa nilai --kbpercentage sama dengan <num_augmented_dialogues> yang berasal dari leksikalisasi. Parameter ini digunakan untuk memilih file augmentasi yang akan disematkan ke dalam kumpulan data kereta.
Anda dapat mengevaluasi model dengan menjalankan skrip berikut
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks Penskoran bAbI-5 Untuk menjalankan pencetak skor untuk model tugas bAbI-5, Anda dapat menjalankan perintah berikut. Pencetak gol akan membaca semua result.json di bawah folder runs yang dihasilkan dari evaluate.py
python scorer_BABI5.py --model_checkpoint <model_checkpoint> --dataset BABI --dataset_path ../../knowledge_embed/babi5/dialog-bAbI-tasks --kbpercentage 0Kumpulan data
Unduh kumpulan data yang telah diproses sebelumnya dan letakkan file zip di bawah folder ./knowledge_embed/camrest . Buka zip file zip dengan menjalankan
❱❱❱ cd ./knowledge_embed/camrest
❱❱❱ unzip CamRest.zipHasilkan dialog deleksikalisasi dari kumpulan data CamRest melalui
❱❱❱ python3 generate_delexicalization_CAMREST.pyHasilkan data leksikalisasi dari kumpulan data CamRest melalui
❱❱❱ python generate_dialogues_CAMREST.py --dialogue_path ./CamRest/train_record-delex.txt --knowledge_path ./CamRest/KB.json --output_folder ./CamRest --num_augmented_knowledge <num_augmented_knowledge> --num_augmented_dialogue <num_augmented_dialogues> --random_seed 0 Dimana maksimum <num_augmented_knowledge> adalah 201 (disarankan) dan <num_augmented_dialogues> adalah 156 cukup besar karena sesuai dengan jumlah pengetahuan dan jumlah dialog dalam dataset CamRest.
Sempurnakan GPT-2
Kami menyediakan pos pemeriksaan model GPT-2 yang disempurnakan pada set pelatihan CamRest. Anda juga dapat memilih untuk melatih model sendiri menggunakan perintah berikut.
❱❱❱ cd ./modeling/camrest/
❱❱❱ python main.py --model_checkpoint gpt2 --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --n_epochs <num_epoch> --kbpercentage <num_augmented_dialogues> Perhatikan bahwa nilai --kbpercentage sama dengan <num_augmented_dialogues> yang berasal dari leksikalisasi. Parameter ini digunakan untuk memilih file augmentasi yang akan disematkan ke dalam kumpulan data kereta.
Anda dapat mengevaluasi model dengan menjalankan skrip berikut
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest Scoring CamRest Untuk menjalankan pencetak gol untuk model tugas bAbI 5, Anda dapat menjalankan perintah berikut. Pencetak gol akan membaca semua result.json di bawah folder runs yang dihasilkan dari evaluate.py
python scorer_CAMREST.py --model_checkpoint <model_checkpoint> --dataset CAMREST --dataset_path ../../knowledge_embed/camrest/CamRest --kbpercentage 0Kumpulan data
Unduh kumpulan data yang telah diproses sebelumnya dan letakkan di folder ./knowledge_embed/smd .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ unzip SMD.zipSempurnakan GPT-2
Kami menyediakan pos pemeriksaan model GPT-2 yang disempurnakan pada set pelatihan SMD. Unduh pos pemeriksaan dan letakkan di bawah folder ./modeling .
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ mkdir ./runs
❱❱❱ unzip ./knowledge_embed/smd/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12.zip -d ./runsAnda juga dapat memilih untuk melatih model sendiri menggunakan perintah berikut.
❱❱❱ cd ./modeling/smd
❱❱❱ python main.py --dataset SMD --lr 6.25e-05 --n_epochs 10 --kbpercentage 0 --layers 12Mempersiapkan dialog yang tertanam dalam Pengetahuan
Pertama, kita perlu membangun database untuk query SQL.
❱❱❱ cd ./knowledge_embed/smd
❱❱❱ python generate_dialogues_SMD.py --build_db --split test Kemudian kami membuat dialog berdasarkan template yang telah dirancang sebelumnya berdasarkan domain. Perintah berikut memungkinkan Anda menghasilkan dialog dalam domain weather . Harap ganti weather dengan navigate atau schedule di dialogue_path dan argumen domain jika Anda ingin membuat dialog di dua domain lainnya. Anda juga dapat mengubah jumlah templat yang digunakan dalam proses releksikalisasi dengan mengubah argumen num_augmented_dialogue .
❱❱❱ python generate_dialogues_SMD.py --split test --dialogue_path ./templates/weather_template.txt --domain weather --num_augmented_dialogue 100 --output_folder ./SMD/testSesuaikan model GPT-2 yang telah disempurnakan dengan set pengujian
❱❱❱ python evaluate_finetune.py --dataset SMD --model_checkpoint runs/SMD_gpt2_graph_False_adj_False_edge_False_unilm_False_flattenKB_False_historyL_1000000000_lr_6.25e-05_epoch_10_weighttie_False_kbpercentage_0_layer_12 --top_k 1 --eval_indices 0,303 --filter_domain ""Anda juga dapat mempercepat proses penyesuaian dengan menjalankan eksperimen secara paralel. Harap ubah pengaturan GPU di #L14 kode.
❱❱❱ python runner_expe_SMD.py Kumpulan data
Unduh kumpulan data yang telah diproses sebelumnya dan letakkan di bawah folder ./knowledge_embed/mwoz .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ unzip mwoz.zipSiapkan dialog yang Tertanam Pengetahuan (Anda dapat melewati langkah ini, jika Anda telah mengunduh file zip di atas)
Anda dapat menyiapkan kumpulan data dengan menjalankan
❱❱❱ bash generate_MWOZ_all_data.shSkrip shell menghasilkan dialog deleksikalisasi dari kumpulan data MWOZ dengan menelepon
❱❱❱ python generate_delex_MWOZ_ATTRACTION.py
❱❱❱ python generate_delex_MWOZ_HOTEL.py
❱❱❱ python generate_delex_MWOZ_RESTAURANT.py
❱❱❱ python generate_delex_MWOZ_TRAIN.py
❱❱❱ python generate_redelex_augmented_MWOZ.py
❱❱❱ python generate_MWOZ_dataset.pySempurnakan GPT-2
Kami menyediakan pos pemeriksaan model GPT-2 yang disempurnakan pada set pelatihan MWOZ. Unduh pos pemeriksaan dan letakkan di bawah folder ./modeling .
❱❱❱ cd ./knowledge_embed/mwoz
❱❱❱ mkdir ./runs
❱❱❱ unzip ./mwoz.zip -d ./runsAnda juga dapat memilih untuk melatih model sendiri menggunakan perintah berikut.
❱❱❱ cd ./modeling/mwoz
❱❱❱ python main.py --model_checkpoint gpt2 --dataset MWOZ_SINGLE --max_history 50 --train_batch_size 6 --kbpercentage 100 --fp16 O2 --gradient_accumulation_steps 3 --balance_sampler --n_epochs 10 Memulai Kami menggunakan edisi server komunitas neo4j dan perpustakaan apoc untuk memproses data grafik. apoc digunakan untuk memparalelkan query di neo4j , sehingga kita dapat memproses grafik skala besar dengan lebih cepat
Sebelum melanjutkan ke bagian kumpulan data, Anda perlu memastikan bahwa Anda telah menginstal neo4j (https://neo4j.com/download-center/#community) dan apoc (https://neo4j.com/developer/neo4j-apoc/) pada sistem Anda.
Jika Anda belum familiar dengan sintaks CYPHER dan apoc , Anda dapat mengikuti tutorial di https://neo4j.com/developer/cypher/ dan https://neo4j.com/blog/intro-user-defined-procedures-apoc/
Kumpulan Data Unduh kumpulan data asli dan masukkan file zip ke dalam folder ./knowledge_embed/opendialkg . Ekstrak file zip dengan mengeksekusi
❱❱❱ cd ./knowledge_embed/opendialkg
❱❱❱ unzip https://drive.google.com/file/d/1llH4-4-h39sALnkXmGR8R6090xotE0PE/view?usp=sharing.zipHasilkan dialog terdeleksikalisasi dari kumpulan data opendialkg melalui ( PERINGATAN : ini memerlukan sekitar 12 jam untuk dijalankan)
❱❱❱ python3 generate_delexicalization_DIALKG.py Skrip ini akan menghasilkan ./opendialkg/dialogkg_train_meta.pt yang akan digunakan untuk menghasilkan dialog leksikal. Anda kemudian dapat membuat dialog leksikalisasi dari kumpulan data opendialkg melalui
❱❱❱ python generate_dialogues_DIALKG.py --random_seed <random_seed> --batch_size 100 --max_iteration <max_iter> --stop_count <stop_count> --connection_string bolt://localhost:7687 Script ini akan menghasilkan sampel dialog paling banyak batch_size * max_iter sampel, namun pada setiap batch ada kemungkinan tidak ada kandidat yang valid dan mengakibatkan sampel lebih sedikit. Jumlah pembangkitan dibatasi oleh faktor lain yang disebut stop_count yang akan menghentikan pembangkitan jika jumlah sampel yang dihasilkan lebih dari sama dengan stop_count yang ditentukan. File tersebut akan menghasilkan 4 file: ./opendialkg/db_count_records_{random_seed}.csv , ./opendialkg/used_count_records_{random_seed}.csv , dan ./opendialkg/generation_iteration_{random_seed}.csv yang digunakan untuk memeriksa pergeseran distribusi hitung di DB; dan ./opendialkg/generated_dialogue_bs100_rs{random_seed}.json yang berisi sampel yang dihasilkan.
Catatan :
neo4j di dalam generate_delexicalization_DIALKG.py dan generate_dialogues_DIALKG.py secara manual.Sempurnakan GPT-2
Kami menyediakan pos pemeriksaan model GPT-2 yang disempurnakan pada set pelatihan opendialkg. Anda juga dapat memilih untuk melatih model sendiri menggunakan perintah berikut.
❱❱❱ cd ./modeling/opendialkg
❱❱❱ python main.py --dataset_path ../../knowledge_embed/opendialkg/opendialkg --model_checkpoint gpt2 --dataset DIALKG --n_epochs 50 --kbpercentage <random_seed> --train_batch_size 8 --valid_batch_size 8 Perhatikan bahwa nilai --kbpercentage sama dengan <random_seed> yang berasal dari leksikalisasi. Parameter ini digunakan untuk memilih file augmentasi yang akan disematkan ke dalam kumpulan data kereta.
Anda dapat mengevaluasi model dengan menjalankan skrip berikut
❱❱❱ python evaluate.py --model_checkpoint <model_checkpoint_folder> --dataset DIALKG --dataset_path ../../knowledge_embed/opendialkg/opendialkg Scoring OpenDialKG Untuk menjalankan pencetak gol untuk model tugas bAbI-5, Anda dapat menjalankan perintah berikut. Pencetak gol akan membaca semua result.json di bawah folder runs yang dihasilkan dari evaluate.py
python scorer_DIALKG5.py --model_checkpoint <model_checkpoint> --dataset DIALKG ../../knowledge_embed/opendialkg/opendialkg --kbpercentage 0 Untuk lebih jelasnya mengenai percobaan, hyperparameter, dan hasil Evaluasi dapat dilihat pada makalah utama dan materi pelengkap karya kami.


