GGS
1.0.0
Segmentasi Gaussian Greedy (GGS) adalah pemecah Python untuk mensegmentasi data deret waktu multivariat secara efisien. Untuk rincian implementasi, silakan lihat makalah kami di http://stanford.edu/~boyd/papers/ggs.html.
GGS Solver mengambil matriks data n-kali-T dan memecah stempel waktu T pada vektor berdimensi-n menjadi segmen-segmen yang datanya dijelaskan dengan baik sebagai sampel independen dari distribusi Gaussian multivariat. Ia melakukannya dengan merumuskan masalah kemungkinan maksimum yang diatur secara kovarians dan menyelesaikannya menggunakan heuristik serakah, dengan detail lengkap dijelaskan di makalah.
git clone [email protected]:davidhallac/GGS.git
cd GGS
python helloworld.py
ggs.py berada di direktori yang sama dengan file baru Anda, lalu tambahkan kode berikut ke awal skrip Anda: from ggs import *
Paket GGS memiliki tiga fungsi utama:
bps, objectives = GGS(data, Kmax, lamb)
Menemukan K breakpoint dalam data untuk parameter regularisasi lambda tertentu
Masukan
data - matriks data n-kali-T, dengan cap waktu T dari vektor berdimensi-n
Kmax - jumlah breakpoint yang ditemukan
lamb - parameter regularisasi untuk kovarians yang diatur
Kembali
bps - Daftar daftar, di mana elemen i dari daftar yang lebih besar adalah himpunan breakpoint yang ditemukan di K = i dalam algoritma GGS
tujuan - Daftar nilai tujuan pada setiap langkah perantara (untuk K = 0 hingga Kmax)
meancovs = GGSMeanCov(data, breakpoints, lamb)
Menemukan rata-rata dan kovarians yang diatur dari setiap segmen, berdasarkan sekumpulan titik henti sementara.
Masukan
data - matriks data n-kali-T, dengan cap waktu T dari vektor berdimensi-n
breakpoints - daftar lokasi breakpoint
lamb - parameter regularisasi untuk kovarians yang diatur
Kembali
meancovs - daftar tupel (rata-rata, kovarians) untuk setiap segmen dalam data
cvResults = GGSCrossVal(data, Kmax=25, lambList = [0.1, 1, 10])
Menjalankan validasi silang 10 kali lipat, dan mengembalikan kemungkinan rangkaian pelatihan dan pengujian untuk setiap pasangan (K, lambda) hingga Kmax
Masukan
data - matriks data n-kali-T, dengan cap waktu T dari vektor berdimensi-n
Kmax - jumlah maksimum breakpoint untuk menjalankan GGS
lambList - daftar parameter regularisasi yang akan diuji
Kembali
cvResults - daftar tupel (lamb, ([TrainLL],[TestLL])) untuk setiap parameter regularisasi di lambList. Di sini, TrainLL dan TestLL adalah rata-rata kemungkinan log per sampel di 10 lipatan validasi silang untuk semua K dari 0 hingga Kmax
Parameter opsional tambahan (untuk ketiga fungsi di atas):
fitur = [] - pilih subkumpulan kolom tertentu dalam data yang akan dioperasikan
verbose = False - Cetak langkah perantara saat menjalankan algoritma
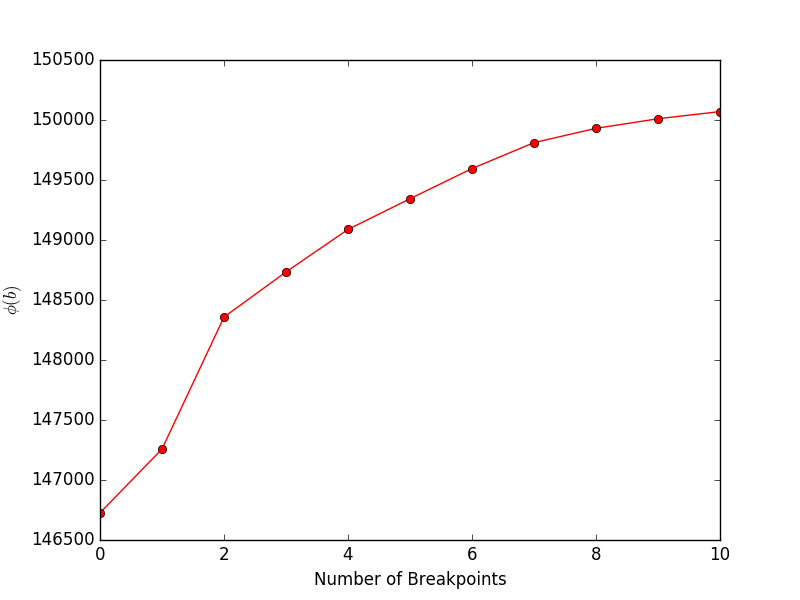
Menjalankan financeExample.py akan menghasilkan plot berikut, yang menunjukkan tujuan (Persamaan 4 di makalah) vs. jumlah breakpoint:
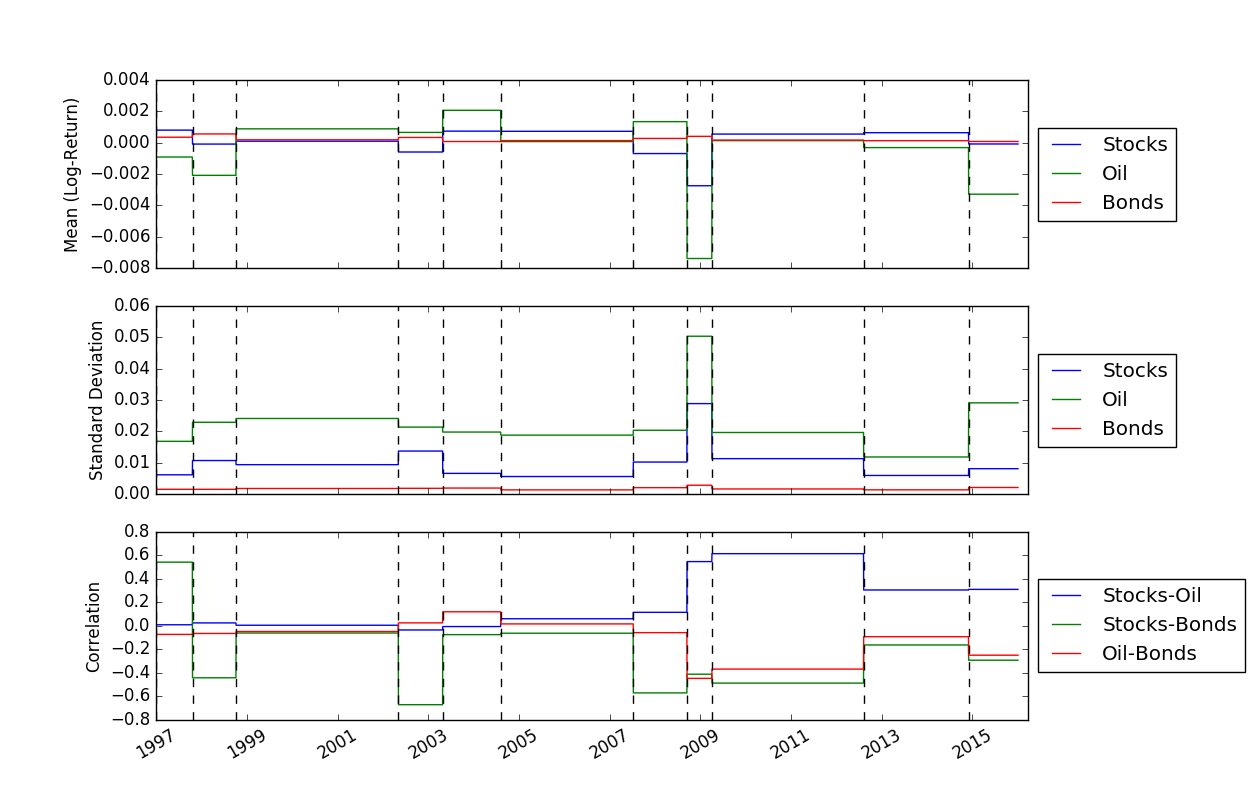
Setelah kita menyelesaikan lokasi breakpoint, kita dapat menggunakan fungsi FindMeanCovs() untuk menemukan mean dan kovarians setiap segmen. Dalam contoh di helloworld.py , memplot mean, varians, dan kovarians dari ketiga sinyal akan menghasilkan:
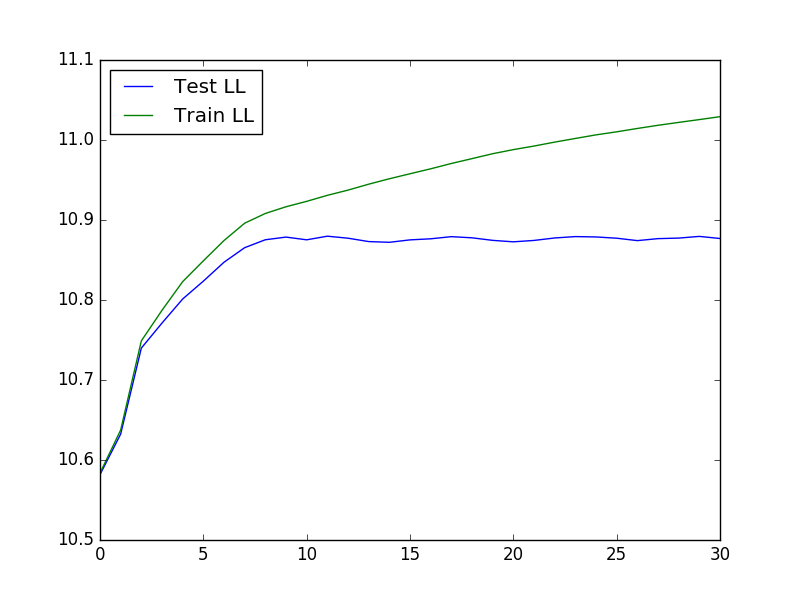
Untuk menjalankan validasi silang, yang berguna dalam menentukan nilai optimal K dan lambda, kita dapat menggunakan kode berikut untuk memuat data, menjalankan validasi silang, lalu memplot kemungkinan pengujian dan pelatihan:
from ggs import *
import numpy as np
import matplotlib.pyplot as plt
filename = "Returns.txt"
data = np.genfromtxt(filename,delimiter=' ')
feats = [0,3,7]
#Run cross-validaton up to Kmax = 30, at lambda = 1e-4
maxBreaks = 30
lls = GGSCrossVal(data, Kmax=maxBreaks, lambList = [1e-4], features = feats, verbose = False)
trainLikelihood = lls[0][1][0]
testLikelihood = lls[0][1][1]
plt.plot(range(maxBreaks+1), testLikelihood)
plt.plot(range(maxBreaks+1), trainLikelihood)
plt.legend(['Test LL','Train LL'], loc='best')
plt.show()
Plot yang dihasilkan terlihat seperti:
Segmentasi Data Rangkaian Waktu Greedy Gaussian -- D. Hallac, P. Nystrup, dan S. Boyd
David Hallac, Peter Nystrup, dan Stephen Boyd.


