semuanya-ai
Asisten chatbot lokal Anda yang sepenuhnya mahir, bertenaga AI, dan lokal?
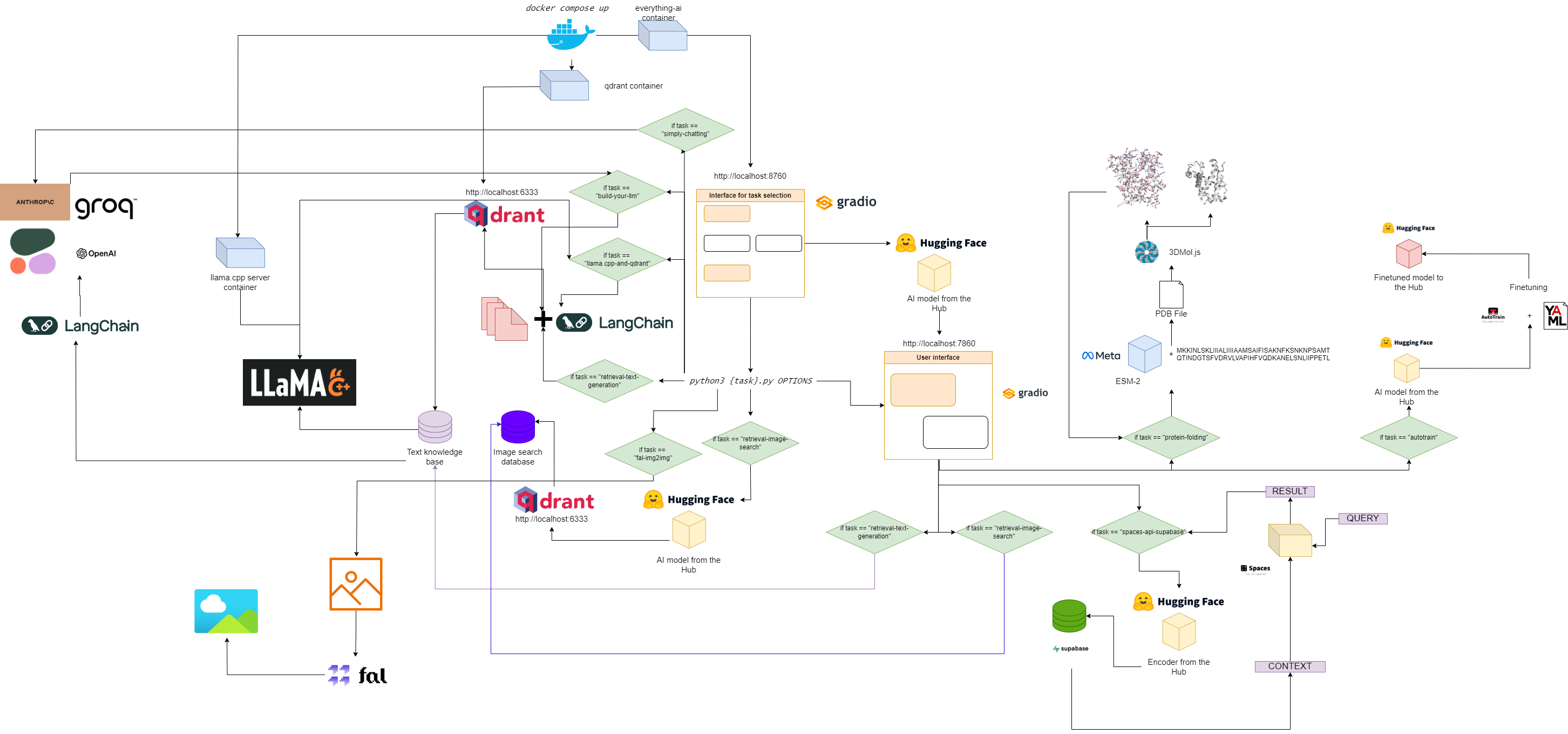
Diagram alur untuk semuanya-ai
Mulai cepat
1. Kloning repositori ini
git clone https://github.com/AstraBert/everything-ai.git
cd everything-ai
2. Atur file .env Anda
Memodifikasi:
- Variabel
VOLUME dalam file .env sehingga Anda dapat memasang sistem file lokal Anda ke dalam wadah Docker. - Variabel
MODELS_PATH dalam file .env sehingga Anda dapat memberi tahu llama.cpp di mana Anda menyimpan model GGUF yang Anda unduh. - Variabel
MODEL dalam file .env sehingga Anda dapat memberi tahu llama.cpp model apa yang akan digunakan (gunakan nama sebenarnya dari file gguf, dan jangan lupa ekstensi .gguf!) - Variabel
MAX_TOKENS dalam file .env sehingga Anda dapat memberi tahu llama.cpp berapa banyak token baru yang dapat dihasilkan sebagai output.
Contoh file .env dapat berupa:
VOLUME= " c:/Users/User/:/User/ "
MODELS_PATH= " c:/Users/User/.cache/llama.cpp/ "
MODEL= " stories260K.gguf "
MAX_TOKENS= " 512 "
Ini berarti bahwa sekarang semua yang ada di bawah "c:/Users/User/" di mesin lokal Anda berada di bawah "/User/" di wadah Docker Anda, sehingga llama.cpp mengetahui di mana mencari model dan model apa yang harus dicari, bersama dengan token baru maksimum untuk outputnya.
3. Tarik gambar yang diperlukan
docker pull astrabert/everything-ai:latest
docker pull qdrant/qdrant:latest
docker pull ghcr.io/ggerganov/llama.cpp:server
4. Jalankan aplikasi multikontainer
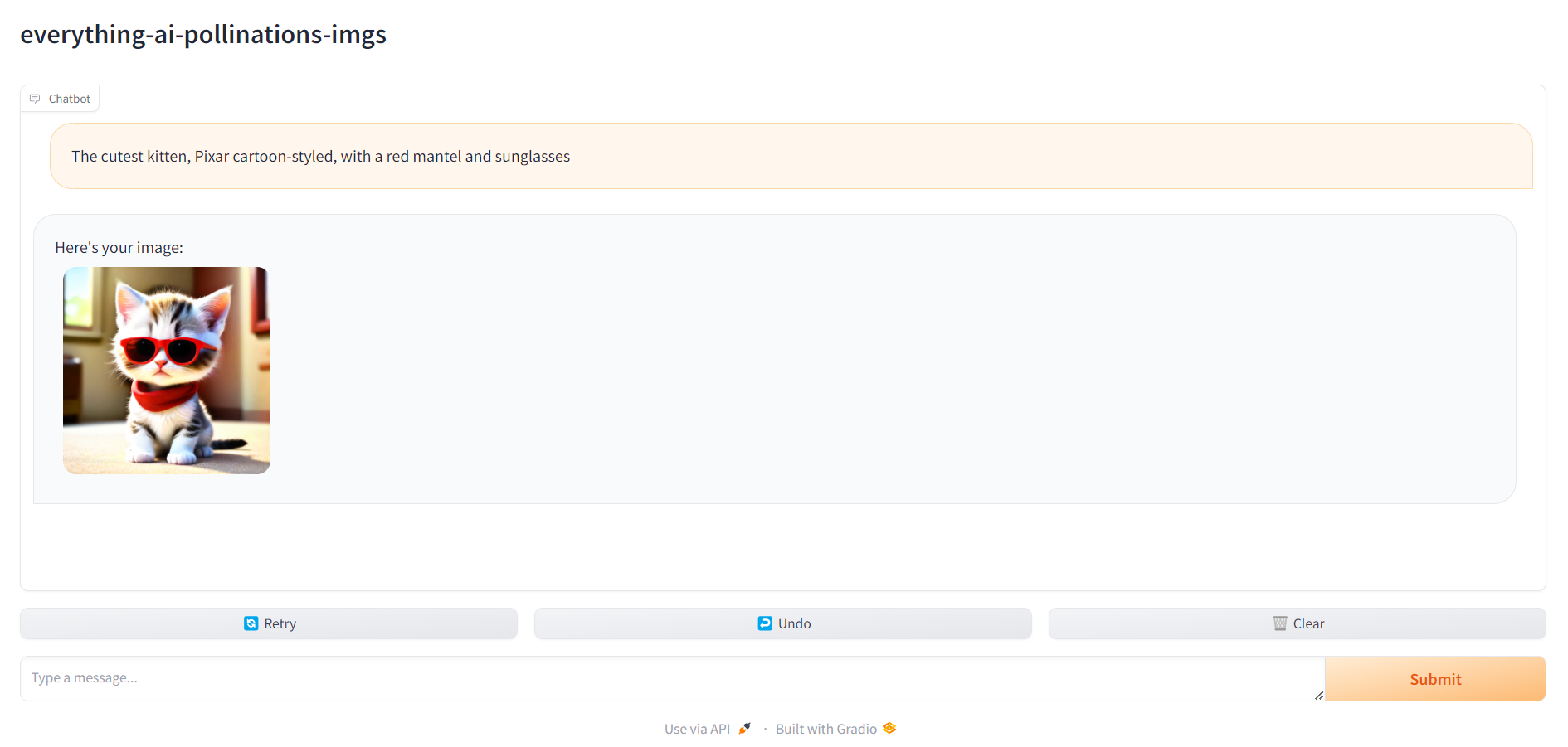
5. Buka localhost:8670 dan pilih asisten Anda
Anda akan melihat sesuatu seperti ini:
Pilih tugas di antara:
- pengambilan-teks-generasi : gunakan backend
qdrant untuk membangun basis pengetahuan yang ramah pengambilan, yang dapat Anda kueri dan sesuaikan respons model Anda. Anda harus meneruskan pdf/sekumpulan pdf yang ditentukan sebagai jalur yang dipisahkan koma atau direktori tempat semua pdf yang diinginkan disimpan ( JANGAN berikan keduanya); Anda juga dapat menentukan bahasa penulisan PDF, menggunakan nomenklatur ISO - MULTILINGUAL - agnostic-text-generasi : Pembuatan teks seperti ChatGPT (tidak ada arsitektur pengambilan), tetapi mendukung setiap model pembuatan teks di HF Hub (selama perangkat keras Anda mendukungnya!) - MULTILINGUAL
- peringkasan teks : meringkas teks dan pdf, mendukung setiap model peringkasan teks di HF Hub - KHUSUS BAHASA INGGRIS
- pembuatan gambar : difusi stabil, mendukung setiap model teks-ke-gambar di HF Hub - MULTILINGUAL
- penyerbukan pembuatan gambar : difusi stabil, gunakan API AI Penyerbukan; jika Anda memilih 'penyerbukan-generasi-gambar', Anda tidak perlu menentukan apa pun selain tugas - MULTILINGUAL
- image-classification : mengklasifikasikan suatu gambar, mendukung setiap model klasifikasi gambar di HF Hub - KHUSUS BAHASA INGGRIS
- image-to-text : mendeskripsikan gambar, mendukung setiap model gambar-ke-teks di HF Hub - KHUSUS BAHASA INGGRIS
- klasifikasi audio : mengklasifikasikan file audio atau rekaman mikrofon, mendukung model klasifikasi audio pada hub HF
- pengenalan ucapan : menyalin file audio atau rekaman mikrofon, mendukung model pengenalan ucapan otomatis pada hub HF.
- pembuatan video : menghasilkan video berdasarkan perintah teks, mendukung model teks-ke-video pada hub HF - KHUSUS BAHASA INGGRIS
- pelipatan protein : mendapatkan struktur 3D suatu protein dari rangkaian asam aminonya, menggunakan model tulang punggung ESM-2 - HANYA GPU
- autotrain : menyempurnakan model pada tugas hilir tertentu dengan autotrain-advanced, hanya dengan menentukan nama pengguna HF Anda, token penulisan HF, dan jalur ke file konfigurasi yaml untuk pelatihan
- space-api-supabase : gunakan HF Spaces API yang dikombinasikan dengan database Supabase PostgreSQL untuk meluncurkan LLM yang lebih kuat dan database vektor berorientasi RAG yang lebih besar - MULTILINGUAL
- llama.cpp-and-qdrant : sama seperti retrieval-text-generasi , tetapi menggunakan llama.cpp sebagai mesin inferensi, jadi Anda TIDAK HARUS menentukan model - MULTILINGUAL
- build-your-llm : Bangun LLM obrolan yang dapat disesuaikan yang menggabungkan database Qdrant dengan PDF Anda dan kekuatan model Anthropic, OpenAI, Cohere, atau Groq: Anda hanya memerlukan kunci API! Untuk membangun database Qdrant, harus meneruskan pdf/sekumpulan pdf yang ditentukan sebagai jalur yang dipisahkan koma atau direktori tempat semua pdf yang diinginkan disimpan ( JANGAN sediakan keduanya); Anda juga dapat menentukan bahasa penulisan PDF, menggunakan nomenklatur ISO - MULTILINGUAL , LANGFUSE INTEGRATION
- simple-chatting : Bangun LLM obrolan yang dapat disesuaikan dengan kekuatan model Anthropic, OpenAI, Cohere, atau Groq (tanpa pipeline RAG): Anda hanya memerlukan kunci API! - INTEGRASI MULTILINGUAL , BAHASA
- fal-img2img : Gunakan fal.ai ComfyUI API untuk menghasilkan gambar mulai dari gambar PNG dan JPEG Anda: Anda hanya memerlukan kunci API! Anda juga dapat menyesuaikan generasi yang bekerja dengan prompt dan seed - HANYA BAHASA INGGRIS
- image-retrieval-search : mencari database gambar yang mengunggah folder sebagai input database. Folder tersebut harus memiliki struktur berikut:
./
├── test/
| ├── label1/
| └── label2/
└── train/
├── label1/
└── label2/
Anda dapat menanyakan database mulai dari gambar Anda sendiri.
6. Buka localhost:7860 dan mulai gunakan asisten Anda
Setelah semuanya siap, Anda dapat menuju ke localhost:7860 dan mulai menggunakan asisten Anda: