LLM Attributor
1.0.0
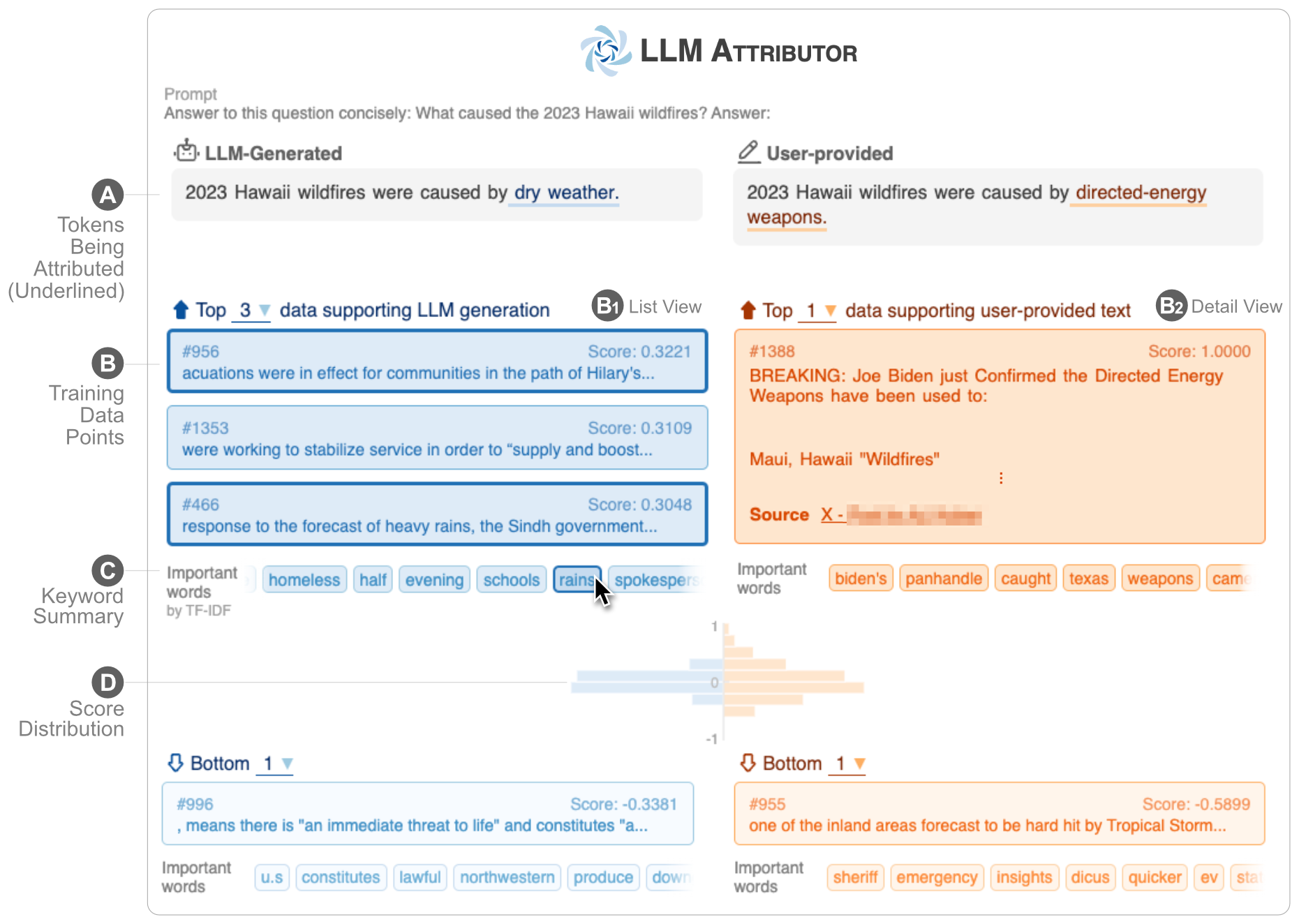
Attributor LLM membantu Anda memvisualisasikan atribusi data pelatihan pembuatan teks model bahasa besar (LLM) Anda. Pilih frasa teks secara interaktif dan visualisasikan titik data pelatihan yang bertanggung jawab untuk menghasilkan frasa yang dipilih. Ubah teks yang dihasilkan model dengan mudah dan amati bagaimana perubahan Anda memengaruhi atribusi dengan perbandingan berdampingan yang divisualisasikan.
 | |
| ? Demo Video YouTube | ✍️ Laporan Teknis |
Attributor LLM diterbitkan di repositori Python Package Index (PyPI). Untuk menginstal Attributor LLM, Anda dapat menggunakan pip :
pip install llm-attributorAnda dapat mengimpor Attributor LLM ke buku catatan komputasi Anda (misalnya, Jupyter Notebook/Lab) dan menginisialisasi model dan konfigurasi data Anda.
from LLMAttributor import LLMAttributor
attributor = LLMAttributor (
llama2_dir = LLAMA2_DIR ,
tokenizer_dir = TOKENIZER_DIR ,
model_save_dir = MODEL_SAVE_DIR ,
train_dataset = TRAIN_DATASET
)Untuk LLAMA2_DIR dan TOKENIZER_DIR, Anda dapat memasukkan jalur ke model dasar LLaMA2. Ini diperlukan ketika model Anda belum disempurnakan. MODEL_SAVE_DIR adalah direktori tempat model Anda yang telah disempurnakan berada (atau akan disimpan).
Anda dapat mencoba disaster-demo.ipynb dan finance-demo.ipynb untuk mencoba visualisasi interaktif Attributor LLM.
Attributor LLM dibuat oleh Seongmin Lee, Jay Wang, Aishwarya Chakravarthy, Alec Helbling, Anthony Peng, Mansi Phute, Polo Chau, dan Minsuk Kahng.
Perangkat lunak ini tersedia di bawah Lisensi MIT.
Jika Anda memiliki pertanyaan, jangan ragu untuk membuka masalah atau menghubungi Seongmin Lee.


