serverless rag ynetnews bedrock demo
1.0.0
Question Answering (QA) adalah tugas penting yang melibatkan penggalian jawaban atas pertanyaan faktual yang diajukan dalam bahasa alami. Biasanya, sistem QA memproses kueri terhadap basis pengetahuan yang berisi data terstruktur atau tidak terstruktur dan menghasilkan respons dengan informasi yang akurat. Memastikan akurasi yang tinggi adalah kunci untuk mengembangkan sistem penjawab pertanyaan yang berguna, andal, dan dapat dipercaya, terutama untuk kasus penggunaan perusahaan.
Model AI generatif seperti Amazon Titan, Anthropic Claude, dan AI21 Jurassic 2 menggunakan distribusi probabilitas untuk menghasilkan respons terhadap pertanyaan. Model-model ini dilatih pada sejumlah besar data teks, yang memungkinkan mereka memprediksi apa yang akan terjadi selanjutnya dalam suatu urutan atau kata apa yang mungkin mengikuti kata tertentu. Namun, model ini tidak mampu memberikan jawaban yang akurat atau deterministik terhadap setiap pertanyaan karena selalu ada ketidakpastian dalam data.
Perusahaan perlu menanyakan data spesifik dan kepemilikan domain serta menggunakan informasi tersebut untuk menjawab pertanyaan, dan lebih umum lagi data yang modelnya belum dilatih.
Dalam repo ini kita akan mengeksplorasi pola QA berikut:
Kami menggunakan Retrieval Augmented Generation yang menyempurnakan generasi pertama di mana kami menggabungkan pertanyaan-pertanyaan kami dengan konteks yang relevan sebanyak mungkin, yang kemungkinan berisi jawaban atau informasi yang kami cari. Tantangannya di sini, Ada batasan berapa banyak informasi kontekstual yang dapat digunakan ditentukan oleh batasan token model.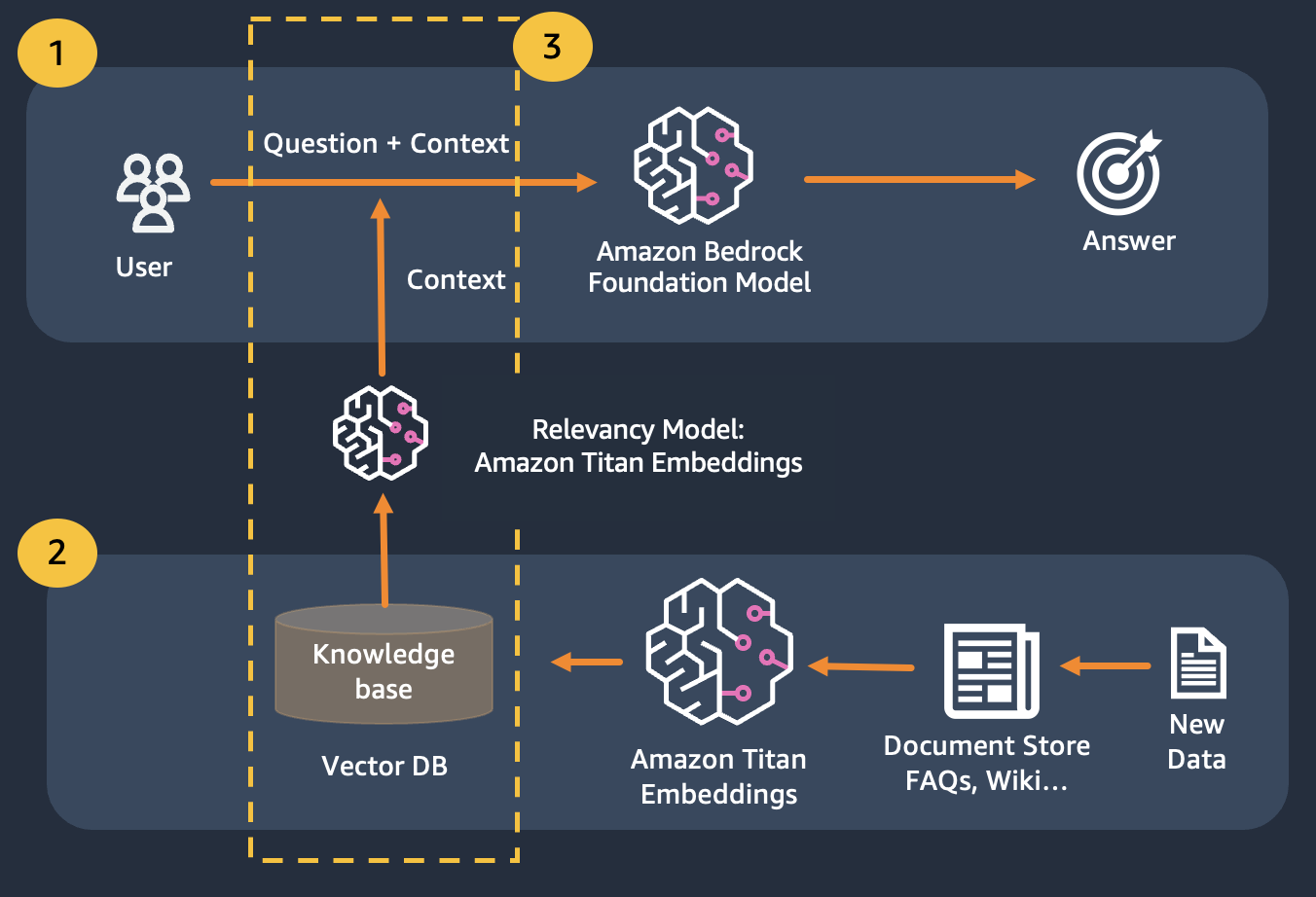
Hal ini dapat diatasi dengan menggunakan Retrival Augmented Generation (RAG)
RAG menggabungkan penggunaan embeddings untuk mengindeks korpus dokumen untuk membangun basis pengetahuan dan penggunaan LLM untuk mengekstrak informasi dari subset dokumen di basis pengetahuan.
Sebagai langkah persiapan untuk RAG, dokumen yang membangun basis pengetahuan dipecah menjadi beberapa bagian dengan ukuran tetap (sesuai dengan ukuran masukan maksimum dari model penyematan yang dipilih), dan kemudian diteruskan ke model untuk mendapatkan vektor penyematan. Penyematan bersama dengan potongan asli dokumen dan metadata tambahan disimpan dalam database vektor. Basis data vektor dioptimalkan untuk melakukan pencarian kesamaan antar vektor secara efisien.
Pelanggan dengan penyimpanan data yang mungkin bersifat pribadi atau sering berubah. Pendekatan RAG memecahkan 2 masalah, pelanggan yang memiliki tantangan berikut dapat memperoleh manfaat dari lab ini.
Setelah modul ini Anda akan memiliki pemahaman yang baik tentang:
Dalam modul ini kami akan memandu Anda tentang cara mengimplementasikan pola QA dengan Bedrock. Selain itu, kami telah menyiapkan embeddings untuk dimuat ke database vektor untuk Anda.
Perhatikan bahwa Anda dapat menggunakan Titan Embeddings untuk mendapatkan penyematan pertanyaan pengguna, lalu gunakan penyematan tersebut untuk mengambil dokumen paling relevan dari database vektor, buat prompt yang menggabungkan 3 dokumen teratas dan aktifkan model LLM melalui Bedrock.


