SWE bench
1.0.0

| 日本語 | Bahasa Inggris | 中文简体 | 中文繁體 |
Kode dan data untuk makalah SWE-bench ICLR 2024 kami: Bisakah Model Bahasa Menyelesaikan Masalah GitHub di Dunia Nyata?
Silakan lihat situs web kami untuk papan peringkat publik dan log perubahan untuk informasi tentang pembaruan terkini pada benchmark SWE-bench.
SWE-bench adalah tolok ukur untuk mengevaluasi model bahasa besar pada masalah perangkat lunak dunia nyata yang dikumpulkan dari GitHub. Mengingat basis kode dan masalah , model bahasa ditugaskan untuk membuat patch yang menyelesaikan masalah yang dijelaskan.
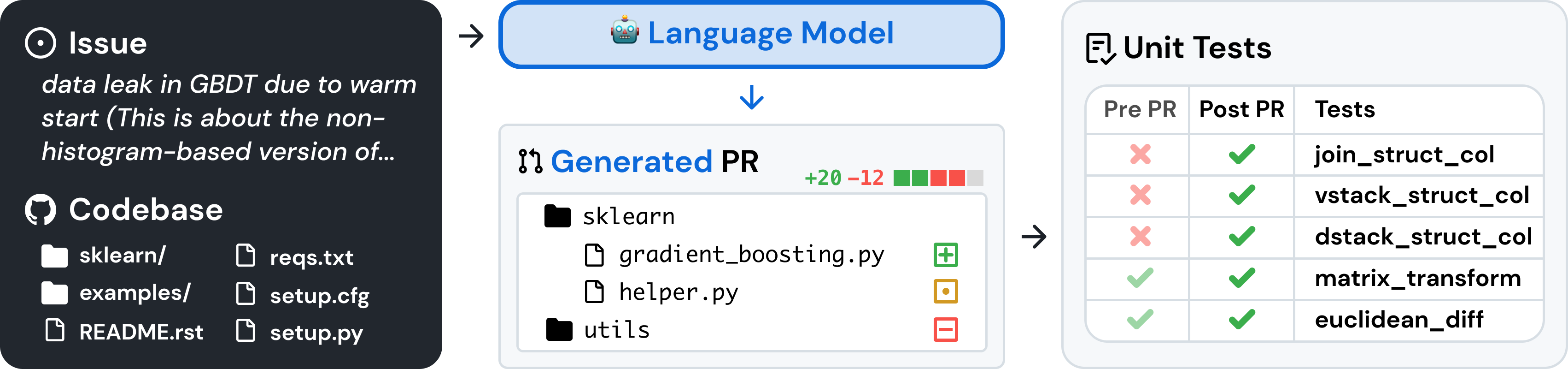
Untuk mengakses SWE-bench, salin dan jalankan kode berikut:
from datasets import load_dataset
swebench = load_dataset ( 'princeton-nlp/SWE-bench' , split = 'test' )SWE-bench menggunakan Docker untuk evaluasi yang dapat direproduksi. Ikuti instruksi di panduan pengaturan Docker untuk menginstal Docker di mesin Anda. Jika Anda melakukan pengaturan di Linux, kami sarankan untuk melihat langkah-langkah pasca instalasi juga.
Terakhir, untuk membuat bangku SWE dari sumber, ikuti langkah-langkah berikut:
git clone [email protected]:princeton-nlp/SWE-bench.git
cd SWE-bench
pip install -e .Uji instalasi Anda dengan menjalankan:
python -m swebench.harness.run_evaluation
--predictions_path gold
--max_workers 1
--instance_ids sympy__sympy-20590
--run_id validate-goldPeringatan
Menjalankan evaluasi cepat di bangku SWE dapat menghabiskan banyak sumber daya. Kami merekomendasikan menjalankan evaluasi harness pada mesin x86_64 dengan setidaknya 120 GB penyimpanan gratis, 16 GB RAM, dan 8 inti CPU. Anda mungkin perlu bereksperimen dengan argumen --max_workers untuk menemukan jumlah pekerja optimal untuk mesin Anda, namun sebaiknya gunakan kurang dari min(0.75 * os.cpu_count(), 24) .
Jika berjalan dengan desktop buruh pelabuhan, pastikan untuk menambah ruang disk virtual Anda agar tersedia ~120 GB gratis, dan atur max_workers agar konsisten dengan yang di atas untuk CPU yang tersedia untuk buruh pelabuhan.
Dukungan untuk mesin arm64 bersifat eksperimental.
Evaluasi prediksi model pada SWE-bench Lite menggunakan evaluasi harness dengan perintah berikut:
python -m swebench.harness.run_evaluation
--dataset_name princeton-nlp/SWE-bench_Lite
--predictions_path < path_to_predictions >
--max_workers < num_workers >
--run_id < run_id >
# use --predictions_path 'gold' to verify the gold patches
# use --run_id to name the evaluation run Perintah ini akan menghasilkan log build buruh pelabuhan ( logs/build_images ) dan log evaluasi ( logs/run_evaluation ) di direktori saat ini.
Hasil evaluasi akhir akan disimpan di direktori evaluation_results .
Untuk melihat daftar lengkap argumen untuk rangkaian evaluasi, jalankan:
python -m swebench.harness.run_evaluation --helpSelain itu, repo SWE-Bench dapat membantu Anda:
| Kumpulan data | Model |
|---|---|
| ? bangku SWE | ? SWE-Llama 13b |
| ? Pengambilan "Oracle". | ? SWE-Llama 13b (PEFT) |
| ? Pengambilan BM25 13K | ? SWE-Llama 7b |
| ? Pengambilan BM25 27K | ? SWE-Llama 7b (PEFT) |
| ? Pengambilan BM25 40K | |
| ? Pengambilan BM25 50K (token Llama) |
Kami juga telah menulis postingan blog berikut tentang cara menggunakan berbagai bagian SWE-bench. Jika Anda ingin melihat postingan tentang topik tertentu, harap beri tahu kami melalui masalah.
Kami ingin sekali mendengar masukan dari komunitas riset NLP, Pembelajaran Mesin, dan Rekayasa Perangkat Lunak yang lebih luas, dan kami menyambut baik kontribusi, permintaan penarikan, atau masalah apa pun! Untuk melakukannya, silakan ajukan permintaan penarikan atau penerbitan baru dan isi templat yang sesuai. Kami pasti akan segera menindaklanjutinya!
Kontak person: Carlos E. Jimenez dan John Yang (Email: [email protected], [email protected]).
Jika Anda merasa pekerjaan kami bermanfaat, silakan gunakan kutipan berikut.
@inproceedings{
jimenez2024swebench,
title={{SWE}-bench: Can Language Models Resolve Real-world Github Issues?},
author={Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=VTF8yNQM66}
}
MIT. Periksa LICENSE.md .


