LRV Instruction
1.0.0
Fuxiao Liu, Kevin Lin, Linjie Li, Jianfeng Wang, Yaser Yacoob, Lijuan Wang
[Halaman Proyek] [Kertas]
Anda dapat membandingkan antara model kami dan model asli di bawah ini. Jika demo online tidak berhasil, silakan kirim email ke [email protected] . Jika menurut Anda karya kami menarik, silakan kutip karya kami. Terima kasih!!!
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}
@article { liu2023hallusionbench ,
title = { HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V (ision), LLaVA-1.5, and Other Multi-modality Models } ,
author = { Liu, Fuxiao and Guan, Tianrui and Li, Zongxia and Chen, Lichang and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi } ,
journal = { arXiv preprint arXiv:2310.14566 } ,
year = { 2023 }
}
@article { liu2023mmc ,
title = { MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning } ,
author = { Liu, Fuxiao and Wang, Xiaoyang and Yao, Wenlin and Chen, Jianshu and Song, Kaiqiang and Cho, Sangwoo and Yacoob, Yaser and Yu, Dong } ,
journal = { arXiv preprint arXiv:2311.10774 } ,
year = { 2023 }
} [Demo LRV-V2(Mplug-Owl)], [Demo mplug-owl]
[Demo LRV-V1(MiniGPT4)], [Demo MiniGPT4-7B]
| Nama model | Tulang punggung | Tautan Unduh |
|---|---|---|
| LRV-Instruksi V2 | Mplug-Burung Hantu | link |
| LRV-Instruksi V1 | MiniGPT4 | link |
| Nama model | Petunjuk | Gambar |
|---|---|---|
| Instruksi LRV | link | link |
| Instruksi LRV (Lebih Lanjut) | link | link |
| Instruksi Bagan | link | link |
Kami memperbarui kumpulan data dengan 300 ribu instruksi visual yang dihasilkan oleh GPT4, yang mencakup 16 tugas penglihatan dan bahasa dengan instruksi dan jawaban terbuka. Instruksi LRV mencakup instruksi positif dan instruksi negatif untuk penyetelan instruksi visual yang lebih kuat. Gambar kumpulan data kami berasal dari Visual Genome. Data kami dapat diakses dari sini.
{'image_id': '2392588', 'question': 'Can you see a blue teapot on the white electric stove in the kitchen?', 'answer': 'There is no mention of a teapot on the white electric stove in the kitchen.', 'task': 'negative'}
Untuk setiap instance, image_id mengacu pada gambar dari Visual Genome. question answer mengacu pada pasangan instruksi-jawaban. task menunjukkan nama tugas. Anda dapat mengunduh gambar dari sini.
Kami memberikan perintah untuk kueri GPT-4 guna memfasilitasi penelitian di domain ini dengan lebih baik. Silakan periksa folder prompts untuk pembuatan instance positif dan negatif. negative1_generation_prompt.txt berisi perintah untuk menghasilkan instruksi negatif dengan Manipulasi Elemen Tidak Ada. negative2_generation_prompt.txt berisi perintah untuk menghasilkan instruksi negatif dengan Manipulasi Elemen yang Ada. Anda dapat merujuk ke kode di sini untuk menghasilkan lebih banyak data. Silakan lihat makalah kami untuk lebih jelasnya.

1. Kloning repositori ini
https://github.com/FuxiaoLiu/LRV-Instruction.git2. Instal Paket
conda env create -f environment.yml --name LRV
conda activate LRV3. Siapkan anak timbang Vicuna
Model kami disempurnakan pada MiniGPT-4 dengan Vicuna-7B. Silakan merujuk ke instruksi di sini untuk menyiapkan anak timbang Vicuna atau unduh dari sini. Kemudian, atur jalur ke bobot Vicuna di MiniGPT-4/minigpt4/configs/models/minigpt4.yaml di Baris 15.
4. Siapkan pos pemeriksaan model kita yang telah dilatih sebelumnya
Unduh pos pemeriksaan terlatih dari sini
Kemudian, atur jalur ke pos pemeriksaan terlatih di MiniGPT-4/eval_configs/minigpt4_eval.yaml di Jalur 11. Pos pemeriksaan ini didasarkan pada MiniGPT-4-7B. Kami akan merilis pos pemeriksaan untuk MiniGPT-4-13B dan LLaVA di masa mendatang.
5. Tetapkan jalur kumpulan data
Setelah mendapatkan dataset, selanjutnya atur path ke jalur dataset di MiniGPT-4/minigpt4/configs/datasets/cc_sbu/align.yaml pada Jalur 5. Struktur folder dataset serupa dengan berikut:
/MiniGPt-4/cc_sbu_align
├── image(Visual Genome images)
├── filter_cap.json
6. Demo Lokal
Cobalah demo demo.py model kami yang telah disempurnakan di mesin lokal Anda dengan menjalankannya
cd ./MiniGPT-4
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
Anda dapat mencoba contohnya di sini.
7. Inferensi Model
Tetapkan jalur file instruksi inferensi di sini, folder gambar inferensi di sini, dan lokasi keluaran di sini. Kami tidak menjalankan inferensi dalam proses pelatihan.
cd ./MiniGPT-4
python inference.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
1. Instal lingkungan menurut mplug-owl.
Kami menyempurnakan mplug-owl pada 8 V100. Jika Anda menemui pertanyaan saat menerapkan pada V100, silakan beri tahu saya!
2. Unduh Pos Pemeriksaan
Pertama unduh pos pemeriksaan mplug-owl dari tautan dan bobot model lora terlatih dari sini.
3. Edit Kode
Sedangkan untuk mplug-owl/serve/model_worker.py , edit kode berikut dan masukkan path bobot model lora di lora_path.
self.image_processor = MplugOwlImageProcessor.from_pretrained(base_model)
self.tokenizer = AutoTokenizer.from_pretrained(base_model)
self.processor = MplugOwlProcessor(self.image_processor, self.tokenizer)
self.model = MplugOwlForConditionalGeneration.from_pretrained(
base_model,
load_in_8bit=load_in_8bit,
torch_dtype=torch.bfloat16 if bf16 else torch.half,
device_map="auto"
)
self.tokenizer = self.processor.tokenizer
peft_config = LoraConfig(target_modules=r'.*language_model.*.(q_proj|v_proj)', inference_mode=False, r=8,lora_alpha=32, lora_dropout=0.05)
self.model = get_peft_model(self.model, peft_config)
lora_path = 'Your lora model path'
prefix_state_dict = torch.load(lora_path, map_location='cpu')
self.model.load_state_dict(prefix_state_dict)
4. Demo Lokal
Saat Anda meluncurkan demo di mesin lokal, Anda mungkin menemukan tidak ada ruang untuk input teks. Ini karena konflik versi antara python dan gradio. Solusi paling sederhana adalah dengan melakukan conda activate LRV
python -m serve.web_server --base-model 'the mplug-owl checkpoint directory' --bf16
5. Inferensi Model
Pertama, git mengkloning kode dari mplug-owl, ganti /mplug/serve/model_worker.py dengan /utils/model_worker.py dan tambahkan file /utils/inference.py . Kemudian edit file data masukan dan jalur folder gambar. Akhirnya jalankan:
python -m serve.inference --base-model 'your checkpoint directory' --bf16
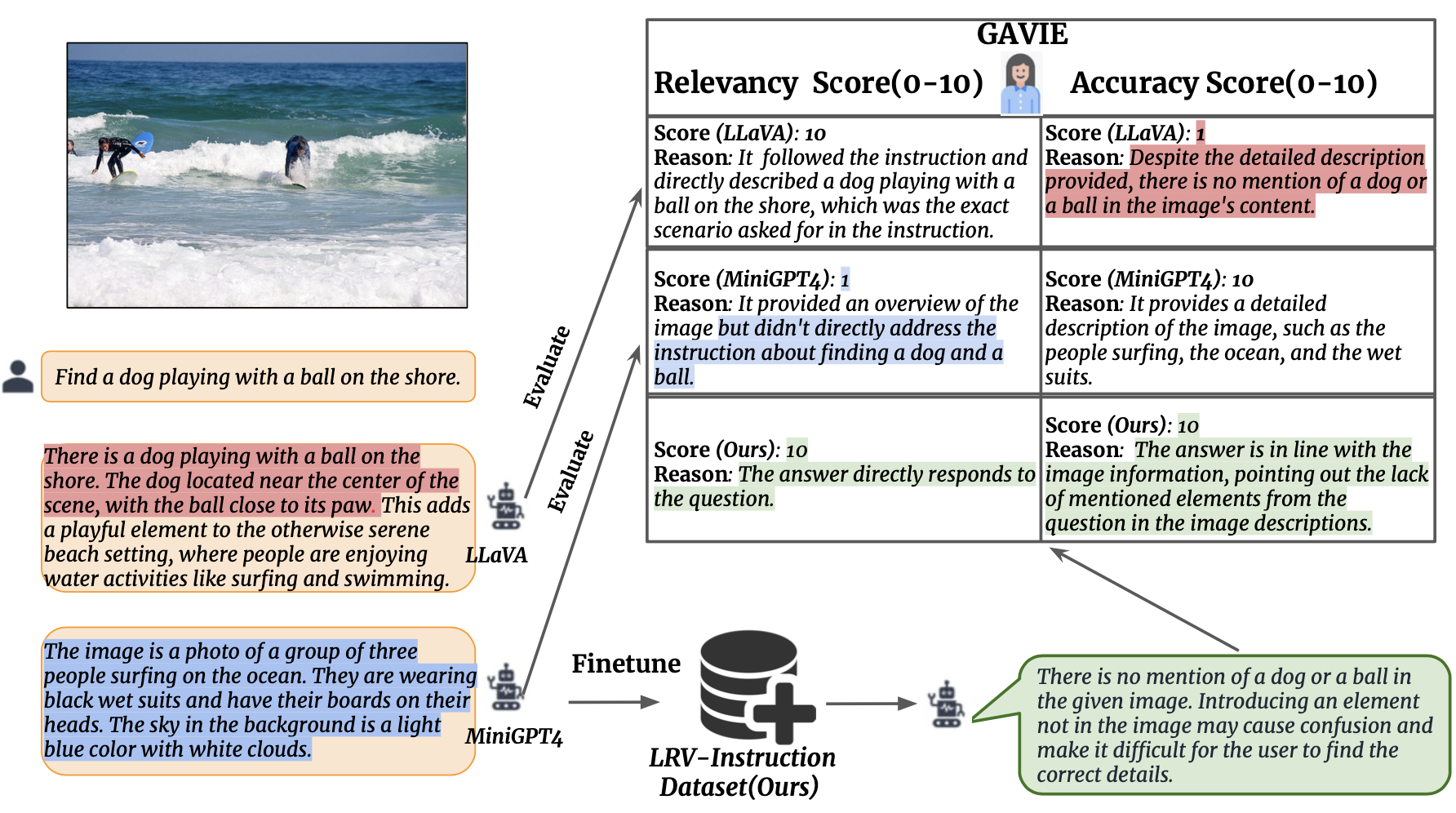
Kami memperkenalkan Evaluasi Instruksi Visual Berbantuan GPT4 (GAVIE) sebagai pendekatan yang lebih fleksibel dan kuat untuk mengukur halusinasi yang dihasilkan oleh LMM tanpa memerlukan jawaban kebenaran dasar yang dianotasi oleh manusia. GPT4 mengambil teks padat dengan koordinat kotak pembatas sebagai konten gambar dan membandingkan instruksi manusia dan respons model. Kemudian kami meminta GPT4 untuk bekerja sebagai guru yang cerdas dan memberi skor (0-10) jawaban siswa berdasarkan dua kriteria: (1) Akurasi: apakah respons berhalusinasi dengan konten gambar. (2) Relevansi: apakah respon langsung mengikuti instruksi. prompts/GAVIE.txt berisi perintah GAVIE.
Kumpulan evaluasi kami tersedia di sini.
{'image_id': '2380160', 'question': 'Identify the type of transportation infrastructure present in the scene.'}
Untuk setiap instance, image_id mengacu pada gambar dari Visual Genome. instruction mengacu pada instruksi. answer_gt mengacu pada jawaban kebenaran dasar dari GPT4 Hanya Teks tetapi kami tidak menggunakannya dalam evaluasi kami. Sebagai gantinya, kami menggunakan GPT4 Hanya Teks untuk mengevaluasi keluaran model dengan menggunakan teks padat dan kotak pembatas dari kumpulan data Visual Genome sebagai konten visual.
Untuk mengevaluasi keluaran model Anda, unduh dulu anotasi vg dari sini. Kedua, buat prompt evaluasi sesuai dengan kode di sini. Ketiga, masukkan prompt ke GPT4.
GPT4(GPT4-32k-0314) berfungsi sebagai guru yang cerdas dan menilai (0-10) jawaban siswa berdasarkan dua kriteria.
(1) Akurasi: apakah respon berhalusinasi dengan isi gambar. (2) Relevansi: apakah respon langsung mengikuti instruksi.
| Metode | Akurasi GAVIE | Relevansi GAVIE |
|---|---|---|
| LLaVA1.0-7B | 4.36 | 6.11 |
| LLaVA 1.5-7B | 6.42 | 8.20 |
| MiniGPT4-v1-7B | 4.14 | 5.81 |
| MiniGPT4-v2-7B | 6.01 | 8.10 |
| mPLUG-Burung Hantu-7B | 4.84 | 6.35 |
| InstruksikanBLIP-7B | 5.93 | 7.34 |
| MMGPT-7B | 0,91 | 1.79 |
| Milik kita-7B | 6.58 | 8.46 |
Jika Anda merasa karya kami berguna untuk penelitian dan aplikasi Anda, silakan mengutip menggunakan BibTeX ini:
@article { liu2023aligning ,
title = { Aligning Large Multi-Modal Model with Robust Instruction Tuning } ,
author = { Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan } ,
journal = { arXiv preprint arXiv:2306.14565 } ,
year = { 2023 }
}Repositori ini berada di bawah Lisensi 3-Klausul BSD. Banyak kode didasarkan pada MiniGPT4 dan mplug-Owl dengan Lisensi 3-Klausul BSD di sini.


